
Артём Колисниченко: Nocode-сервисы стали обычным инструментом для решения важных задач. С их помощью рутину можно переложить с человека на робота. В рубрике «Рассказ от первого лица» представляю Дмитрия Амелина — продюсера, продакшен-продюсера, менеджера проектов по разработке различного медийного и мультимедийного контента. Он работает в качестве независимого специалиста и сотрудничает с различными командами на проектной основе. Дмитрий поделится опытом работы в сервисе Make и его интеграции с ПланФиксом. Передаю ему слово.

Дмитрий Амелин: Справочники ПланФикса существенно расширяют пользовательские возможности конструирования необходимой системы управления бизнес-процессами, особенно в области CRM функционала. Одним из вариантов использования является возможность создания справочников товаров (номенклатуры). Это позволяет через аналитику формировать корзину (состав) конкретной заявки (сделки) и проводить с составом этой заявки все необходимые бизнес-действия.
К сожалению, на момент написания этой статьи (май 2023 года), у ПланФикса ещё нет штатного механизма массового обновления данных записей этих справочников (допустим, через импорт файла содержащего те же записи, что и в справочнике, но с новыми данными по некоторым характеристикам). Можно обновить данные каждой записи по отдельности, указав новое значение вручную, а вот обновить группу записей уже не выйдет, даже если вы хотите всем обновляемым записям присвоить какое-то единое значение.
Когда в справочнике записей 2-3 десятка, то обновление данных в ручном режиме ещё приемлемо, но когда записей от ста и более — задача становится неприемлемо накладной по трудозатратам. Благо, что в ПланФиксе есть API (Rest API и XML API), с помощью которого, в числе прочего, можно обновлять данные справочников, например, через синхронизацию этих данных с другими БД, в том числе и Google Таблицы.
В этот статье я описываю кейс массового обновления данных существующих записей в справочниках с помощью платформы Make (Integromat), которая уже имеет готовые блоки интеграций с ПланФиксом, в том числе и для получения, создания и обновления данных в справочниках. Особенностью платформы Make является то, что как и ПланФикс, это система no-code, т.е. она позволяет создавать необходимые интеграции с помощью API-запросов пользователям не владеющим языками программирования. А наличие уже готовых блоков интеграции и вовсе делает этот процесс простым и доступным.
Конкретный ситуационный пример этого кейса является лишь иллюстрацией процесса обновления данных в справочниках, которые мы берём из других систем, посредством API-запросов. В данном кейсе я беру новые данные из Google Таблицы, чтобы не усложнять описание самого принципа. В идеале для рассматриваемой ситуации, конечно, было бы верно настроить синхронизацию с самой системой ведения складских остатков, допустим с 1С УТ или с БД интернет-магазина.
Исходные данные
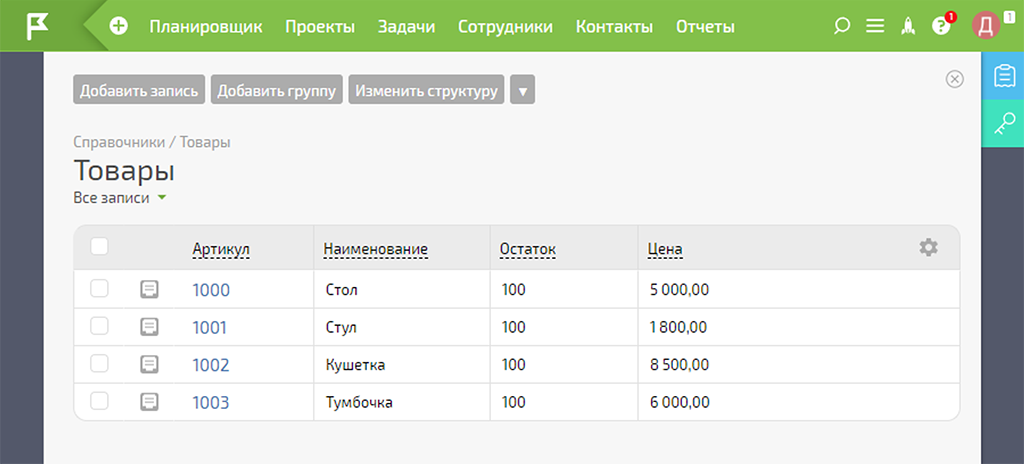
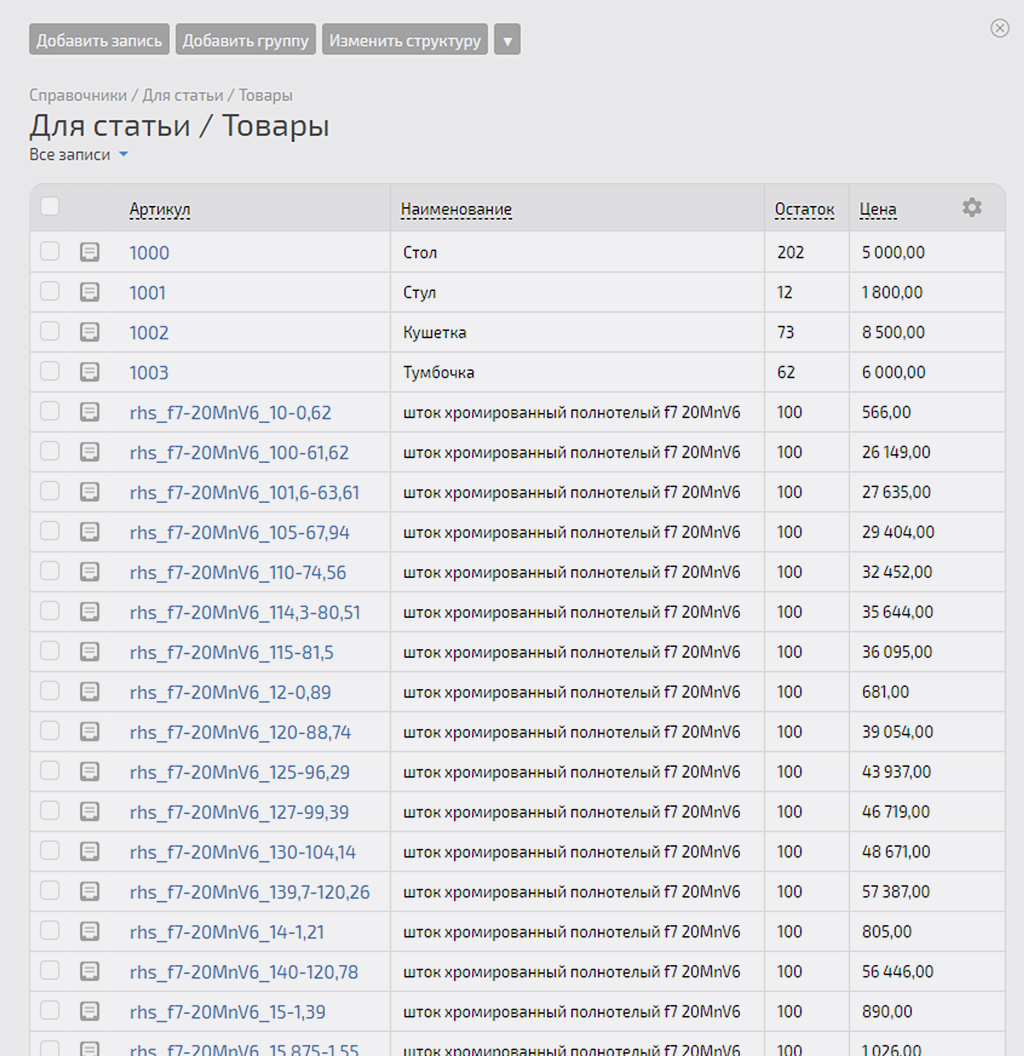
1. Справочник «Товары» в ПланФиксе
Для демонстрации кейса я создал справочник «Товары» с минимальной структурой данных и небольшим количеством записей. Описываемая далее механика будет аналогично работать и на более сложных таблицах:
2. Файл с актуальными остатками — Google Таблица
Допустим, из 1С я выгрузил складские остатки по конкретной номенклатуре в Excel и на основание этого документа создал Google-таблицу «Актуальные остатки», чтобы мне иметь к этим данным доступ по API. Эта таблица сейчас полностью аналогична структуре справочника «Товары» в ПланФиксе, но это совсем не обязательное условие — мы будем брать из неё данные по конкретной колонке «Остаток». В этой колонке у меня как раз уже отличные данные от справочника в ПланФиксе — их то мне и надо передать в соответствующие записи справочника «Товары»:
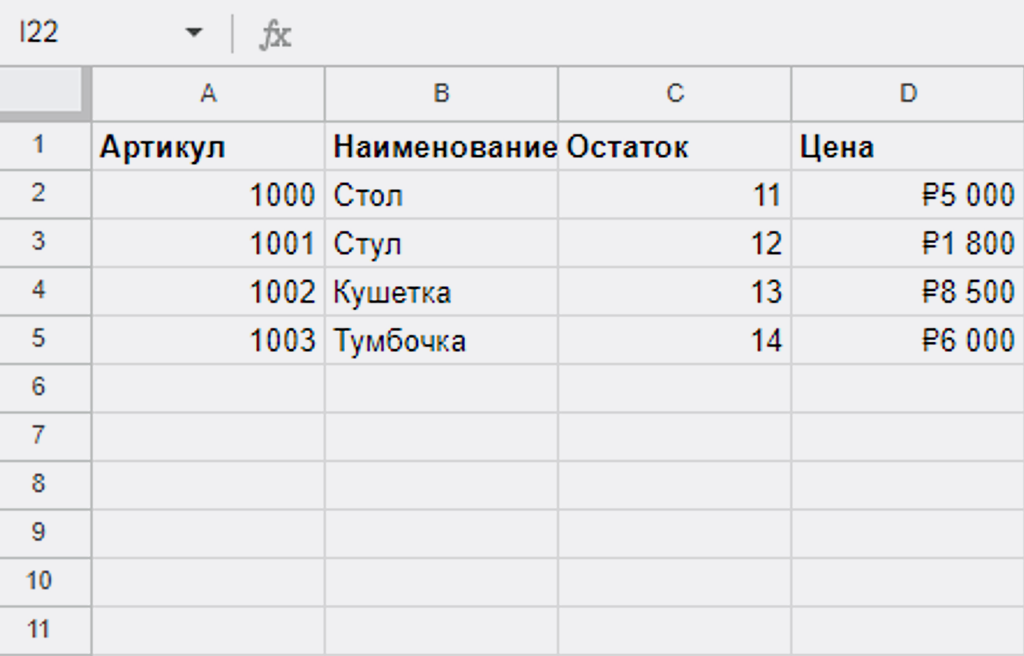
3. Задача
Наша задача получить из Google-таблицы новые данные по остаткам товара и передать эту информацию в справочник ПланФикса, чтобы он обновил у каждого соответствующего товара в справочнике эту информацию.
Общий алгоритм действий
Чтобы решить задачу необходимо:
- Настроить в ПланФиксе интеграцию с сервисом Make.
- Настроить Make — создать один раз специализированное соединение Make с ПланФиксом.
- Создать в Make сценарий, который будет брать определённый данные (Остатки) из Google-таблицы и передавать их в соответствующие записи в справочник «Товары».
- С Google все необходимые настройки происходят на стороне Make.
В общем, всё не сложно, но есть нюанс, который можно решить по разному — способ соотнесения записей из справочника «Товары» и нашей Google-таблицы «Складские остатки».
Идентификация записей справочника и записей Google-таблицы
Вариант 1 — по ID записи в справочнике
ID записи (или ещё key record) в любых базах данным (в том числе и в ПланФиксе) является уникальным идентификатором (ключом) записи, который не повторяется, назначается системой автоматически и позволяет однозначно идентифицировать конкретную запись. Вот этот ID по каждой записи товара в справочнике «Товары» в ПланФиксе нам и надо получить, что бы далее его иметь и во всех других таблицах (системах), с которыми мы будем синхронизироваться.
В итоге, в рамках нашего кейса у нас будет два уникальных идентификатора товара — ID записи из ПланФикса, и артикул, который по сути уже выполняет аналогичную функцию, но уже в пользовательской среде.
Эту операцию мы проведём на соответствующем шаге, после коммуникации ПланФикса и Make, создав в Make отдельный сценарий интеграции.
При добавление новых записей в справочник ПланФикса можно или просто увидеть данные по ID (в справочнике) и перенести их в ручную в необходимую Google-таблицу, или настроить отдельный сценарий Make, который будет запускаться вебхуком ПланФикса (или иным способом) каждый раз, когда в справочнике будет создаваться новая запись, чтобы данные по её ID передать в необходимую Google-таблицу. Но это уже другой кейс:
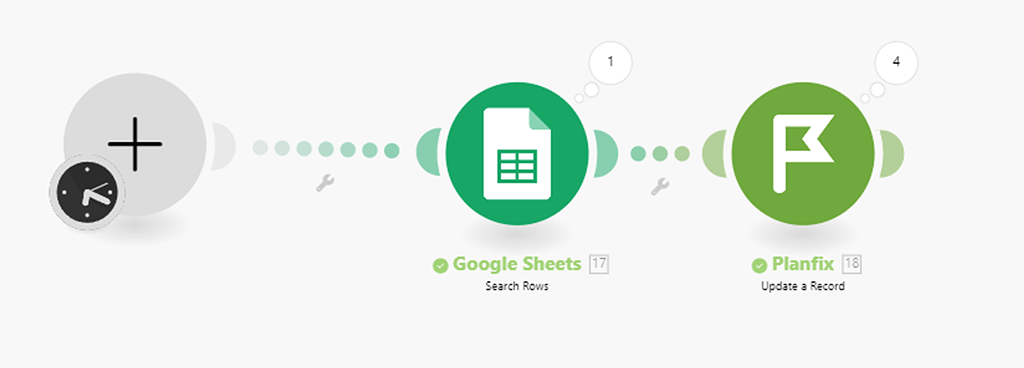
Вариант 2 — поиск по артикулу
Make позволяет соотнести записи из разных БД (ПланФикса и Google-таблицы в нашем случае) по какому-то иному уникальному идентификатору записи. У товаров таким идентификатором является Артикул. В этом случае сам сценарий будет несколько сложнее и дороже по расходам на каждый запуск, но это может быть единственным решением в некоторых ситуациях.
Алгоритм в Make тоже не сложный:
- Получаем в Make все записи конкретного справочника ПланФикса.
- Берём артикул каждой полученной записи и по нему ищем соответствующую запись в указанной Google-таблице.
- При нахождении запускаем блок обновления записи ПланФикса, получив новые данные из указанной ячейки найденной записи в Google-таблице.
В общем, не сложно, но нужен несколько сложнее (и дороже) сценарий, нежели это требуется для создания сценария обновления данных по первому варианту:
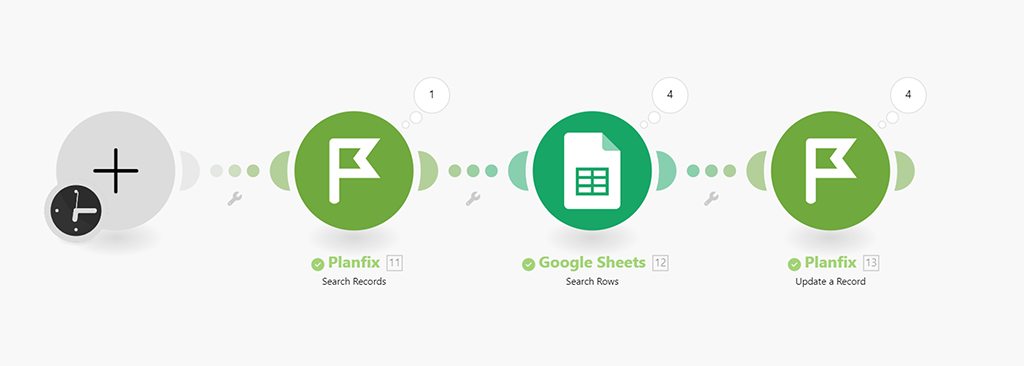
Какой вариант выбрать?
В каждом варианте есть свои плюсы для каждой уникальной ситуации.
Первый вариант:
- Чуть больше мороки в самом начале — надо выгрузить все ID записей справочника в Google-таблицу. При создание новых записей в справочнике надо этот ID снова переносить в синхронизируемую Google-таблицу.
- Сам сценарий проще и дешевле при использовании — на обновление записей по 4 товарам ушло 5 операций (против 9 операций по варианту 2). 1000 операций в Make стоит 1,06$ на момент написания статьи. Ерунда для 4 товаров, а для нескольких десятков тысяч и при интенсивном обновлении остатков может образоваться существенный бюджет.
- Мне кажется, соотнесение записей по ID более надёжно, чем по Артикулу — его, всё-таки, проставляют руками.
Второй вариант:
- В реальной ситуации он проще — один раз настроил и пользуйся.
- На больших объёмах может выйти дороже первого. На 4 товара у нас уже 9 операций (против 5 для первого варианта), т.е. почти в два раза дороже.
- Риск ошибки несколько выше, так как артикулы вводят люди руками.
Далее на простом примере обновления данных я покажу настройки обоих вариантов сценариев, а для ситуации с большим объёмом товаров и демонстрации нюансов, которые требуют чуть более сложного сценария, воспользуюсь вариацией варианта идентификации по артикулу.
Настраиваем PlanFix для интеграции с Make
Нам необходимо подготовить данные для авторизации ПланФикса со стороны Make. Это настройка делается один раз и далее используется для любых сценариев интеграции.
Переходим в меню «Управление аккаунтом»:
Слева выбираем пункт «Доступ к API»:
Нам необходима настройка XML API — в этот раздел и переходим:
Далее выбираем пункт «Активировать и получить ключи»:
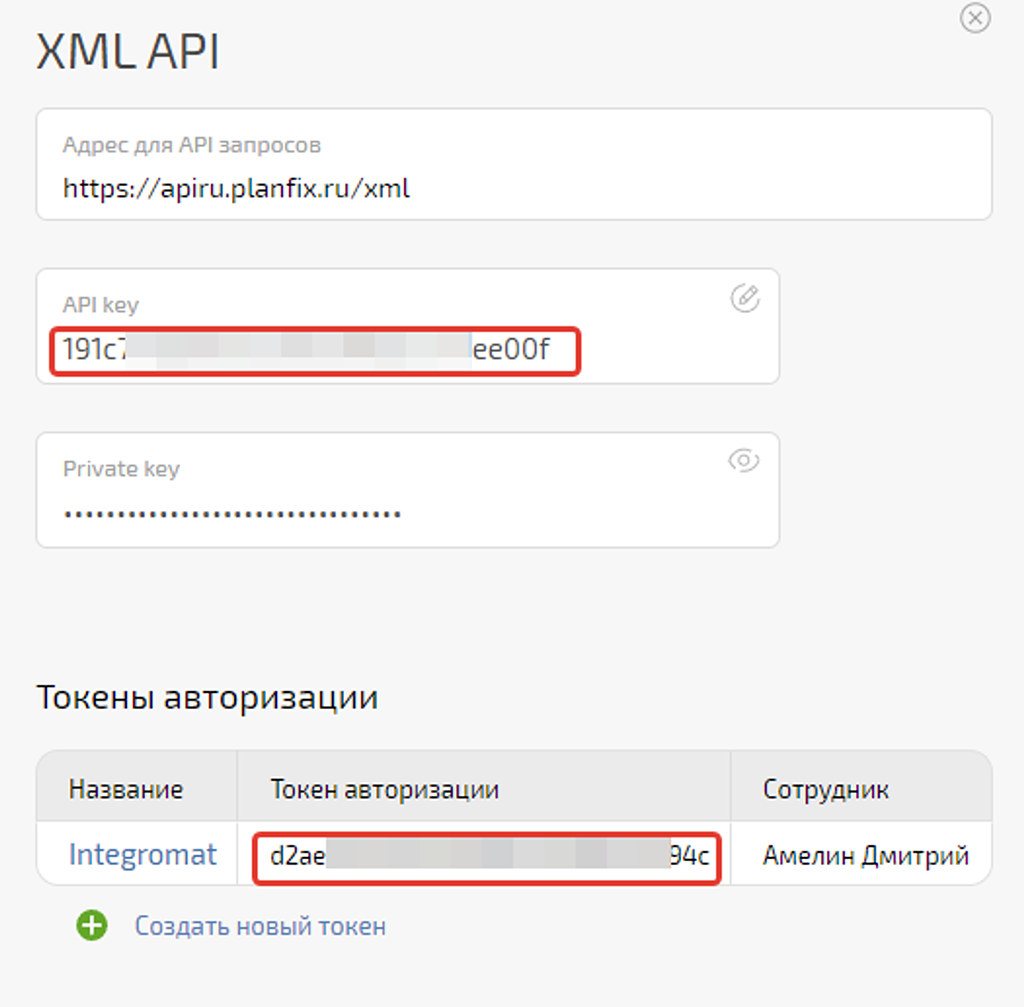
Система создаёт необходимые данные для авторизации. Они нам пригодятся на следующих шагах:
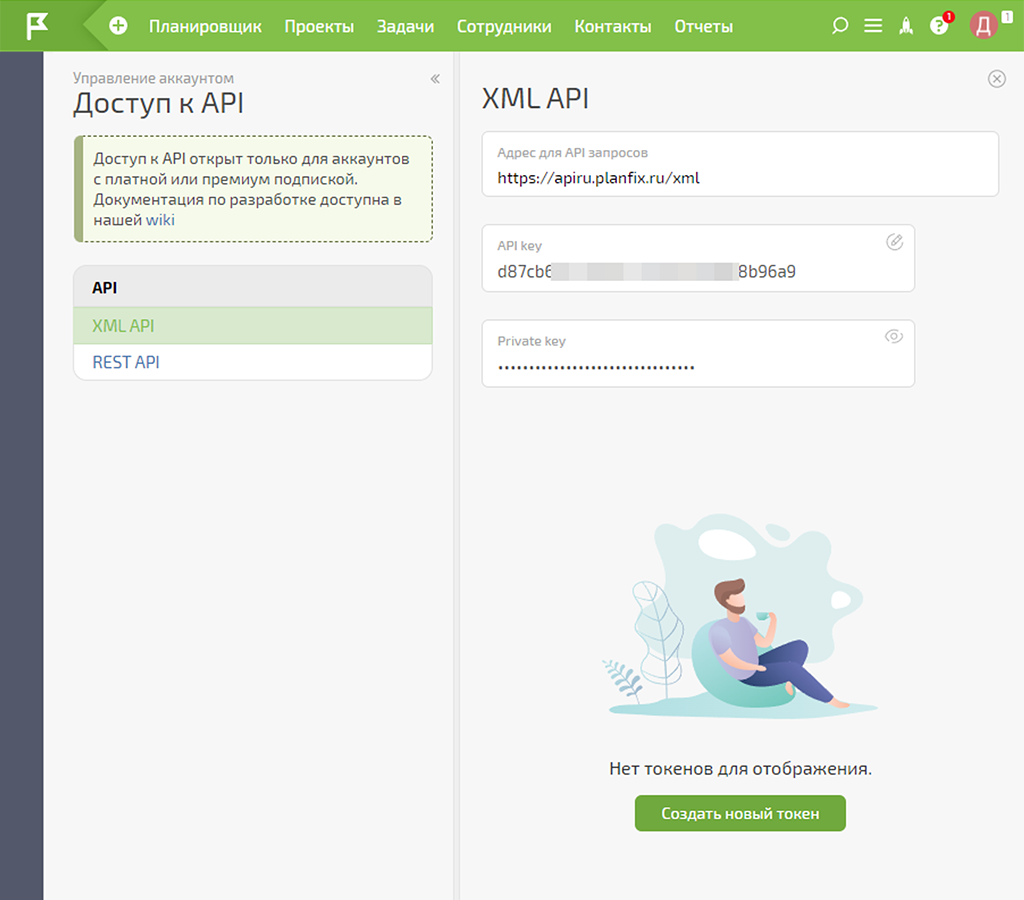
На скриншоте выше заблюрил часть ключа API (API key), так как это данные авторизации, аналогичные логину и паролю. Берегите эти данные в сохранности и приватности, чтобы избежать несанкционированного подключения к вашей системе.
Ещё нам необходим токен для Make — создаём его и называем соответственно:
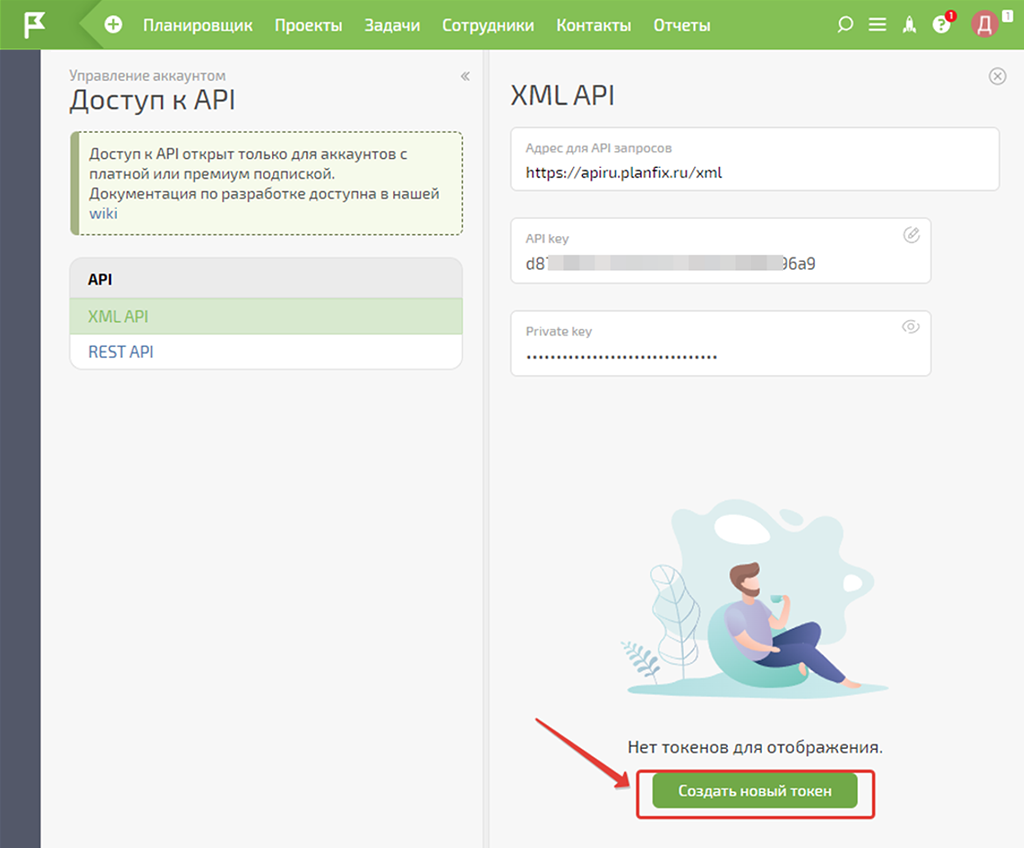
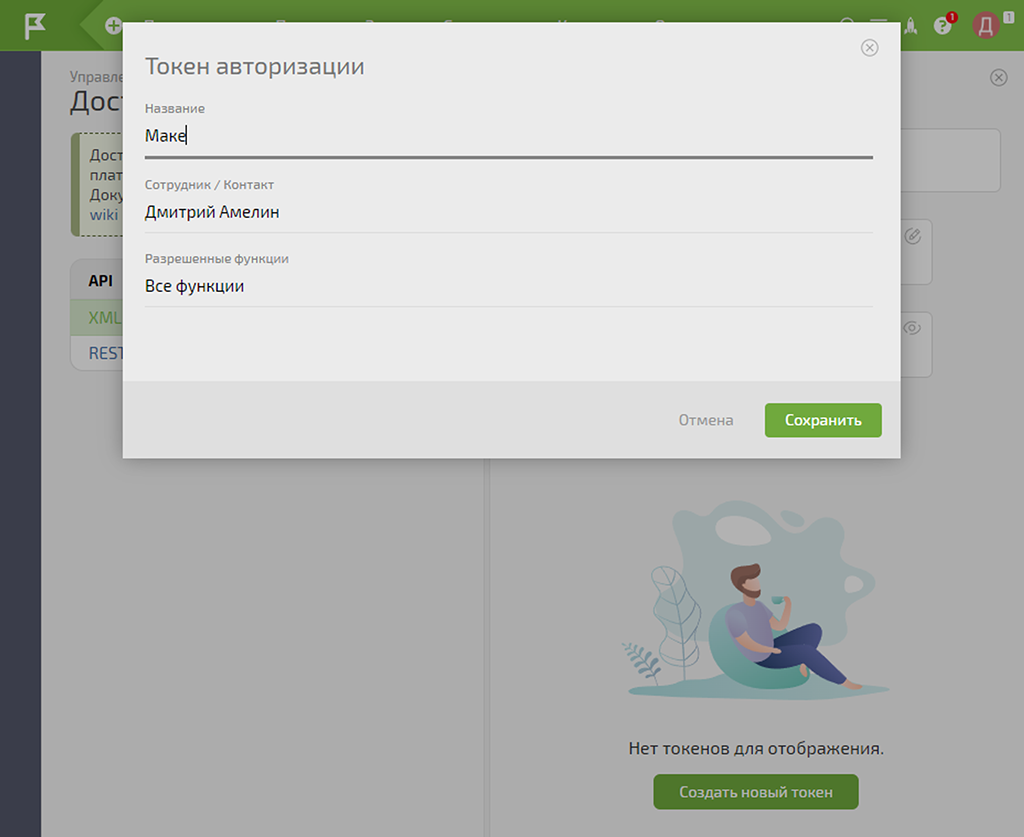
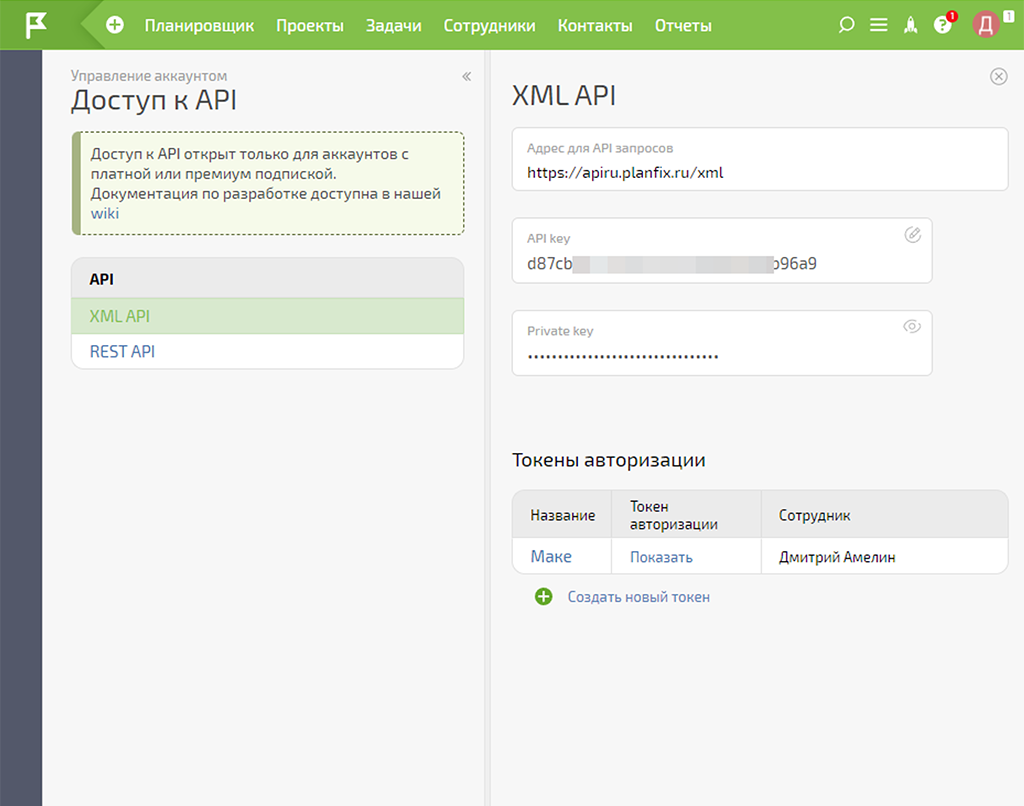
На этом предварительная настройка данных авторизации API ПланФикса для коммуникации с Make завершена. Вернёмся к этим данным на следующих шагах.
Настраиваем Make для интеграции с ПланФиксом
Make позволит нам связать посредством API-запросов данные справочника «Товаров» в ПланФиксе и данные Google-таблицы «Актуальные остатки» и обновить в справочнике ПланФикса нужную нам информацию. На бесплатном тарифе вам будет доступно 1000 операций по API-запросам — этого вполне достаточно для повторения инструкций этого кейса. Сам процесс регистрация расписывать не буду.
Настройку авторизированной коммуникации Make с ПланФиксом можно произвести только в рамках разработки сценария интеграции, поэтому в этом разделе не важно какой далее модуль ПланФикса мы выберем — нам он нужен будет лишь для того, чтобы настроить нужное соединение. Вот такая логика у Make, видимо, в этом есть резон.
Шаг 1 — Cоздаём сценарий интеграции
После регистрации и авторизированного входа мы попадаем на стартовый дашборд своего аккаунта. Создаём новый сценарий в интерфейсе конструирования сценариев интеграций:
Шаг 2 — Добавляем первый модуль интеграции с ПланФиксом
У ПланФикса на платформе Make уже есть разработанные ранее модули интеграций, которые помогут решить нам нашу задачу. Поэтому первым модулем нашего сценария будет один из готовых:
Список готовых модулей ПланФикса пролистываем до раздела работы со справочниками и выбираем модуль Search Records (но для настройки соединения можно выбрать любой модуль блока) — сейчас нам надо лишь настроить соединение с ПланФиксом, а оно настраивается лишь в рамках разработки сценария:
Шаг 3 — Настраиваем соединение Make с ПланФиксом через модуль сценария
Настраиваем соединение Make c ПланФиксом (в дальнейшем будем указывать в настройках других модулей ПланФикса именно его). Сейчас кликаем на добавить (add):

В открывшемся окне настроек вставляем данные авторизации из ПланФикса, которые подготовили на первом шаге. Обратите внимание, в моём случае регион Russia, так как у меня российский аккаунт ПланФикса. В последнем окошке указываете адрес вашего аккаунта ПланФикса:
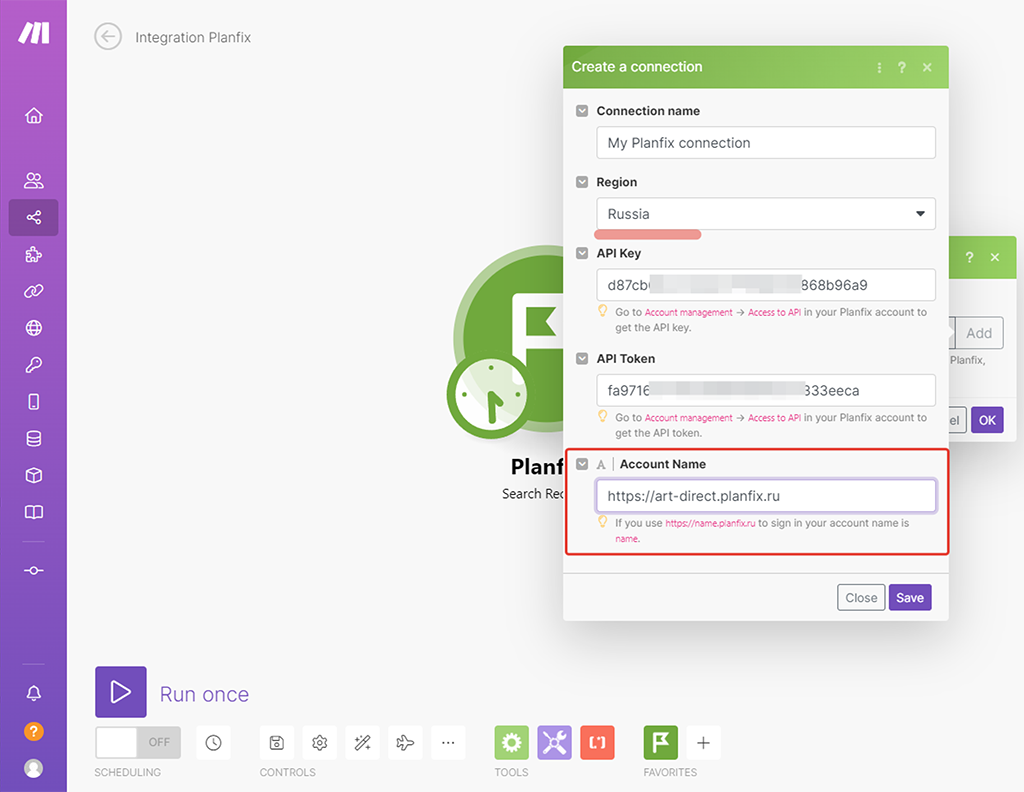
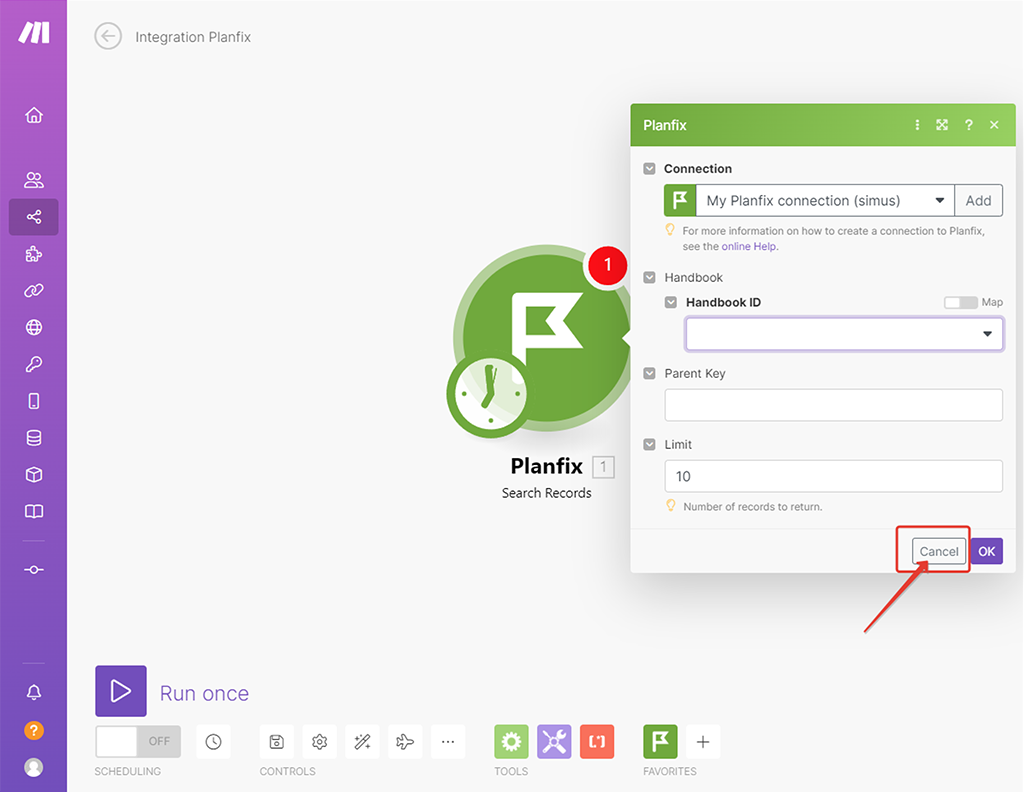
Можно пока никаких дальнейших настроек этого модуля не делать и просто нажать «Cancel», чтобы:
- Отбить шаг настройки соединения Make c ПланФиксом.
- Чтобы я смог проиллюстрировать нюанс создания сценариев, который многим может в дальнейшем упростить жизнь.
Ок, Make для работы с ПланФиксом мы настроили! Сам модуль можно уже удалить — он нам нужен был лишь для настройки соединения.
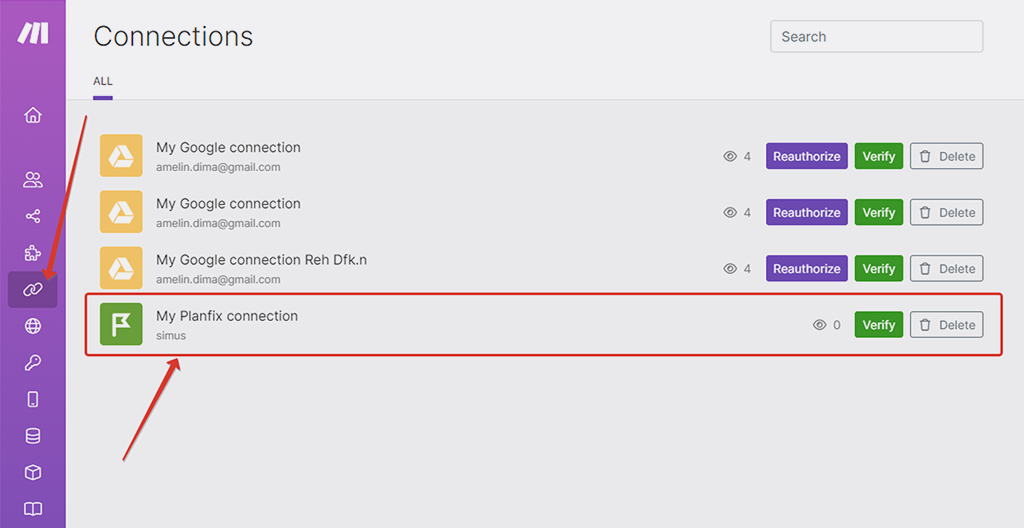
Для справки: созданное соединение с ПланФиксом находится теперь в разделе соединений нашего аккаунта, но только как запись — изменить настройки его не выйдет, но нам это и не надо:
Небольшой нюанс проектирования сценариев интеграций в Make
По умолчанию Make помещает первый модуль сценария интеграции на стартовую позицию настроек запуска самого сценария (это первая позиция в нашем сценарии), но я рекомендую вам с этой позиции этот модуль интеграции удалить и иметь эту позицию пустой — тогда вы сможете в одном сценарии хранить разные его варианты или даже какие-то технические сценарий интеграций для доп. задач, что для многих может выйти более удобным, чем создание для каждой отдельной задачи интеграции отдельного сценария.
Это совсем не обязательно делать (возможно, что для каких-то сценариев и вовсе нежелательно), но я далее будут иллюстрировать весь процесс с учётом такого подхода. Если сейчас не очень понятно, что я имею в виду, то не переживайте — далее всё разъяснится.
Выделяем правой кнопки мыши созданный модуль интеграции и из выпадающем меню выбираем «Удалить модуль»:
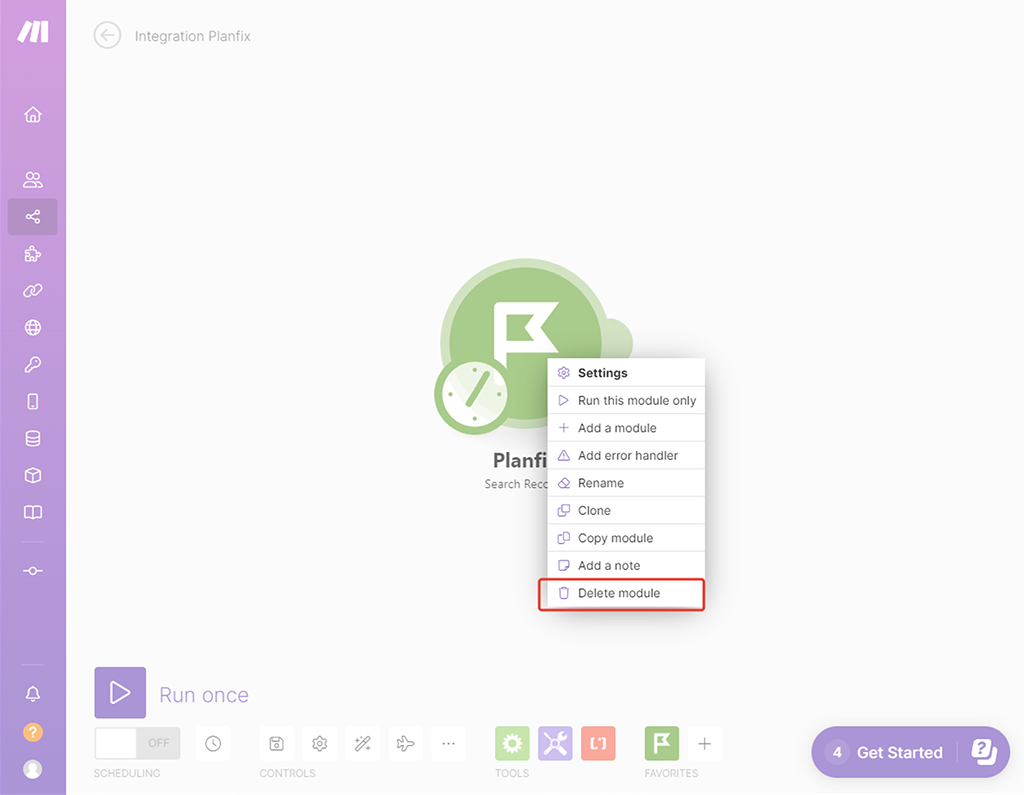
Ок, теперь всё на нужном старте:
Получения ID записей справочника ПланФикса и передача их в Google-документ с остатками
Прежде чем создавать сценарий по первому варианту, когда мы идентифицируем записи по ID, давайте получим эти ID записей из справочника «Товары» в ПланФиксе и подставим эти данные к соответствующим записям товаров в Google-таблице «Актуальные остатки».
Общий алгоритм действий в Make:
- Настроить модуль получения записей из справочников в ПланФикс.
- Настроить модуль поиска соответствующих записей в Google-документе по Артикулу.
- Настроить модуль обновления найденных записей в Google-документе — передача информации по ID записи из справочника ПланФикса.
В рамках этой же задачи мы разово настроим соединение с нашим Google-аккаунтом, для интеграции с Google-таблицей «Актуальные остатки».
Шаг 1 — Добавляем модуль (1) получения списка записей справочника
Создаём новый сценарий или возвращаемся в старый сценарий не принципиально — у нас там всё с чистого листа. Можно сразу его и назвать, допустим «Integration PlanFix», чтобы периодически сохранять — автосохранения нет:
Как уже писал выше, первый модуль сценария интеграции буду создавать не на штатном месте (как по умолчанию), а на следующей (второй) позиции:
При клике на маленький «+» создаётся новая позиция сценария и сразу открывается список выбора доступных систем, с которыми мы хотим настроить интеграцию. По первым буквам бренда PlanFix находим его в быстром поиске и выбираем:
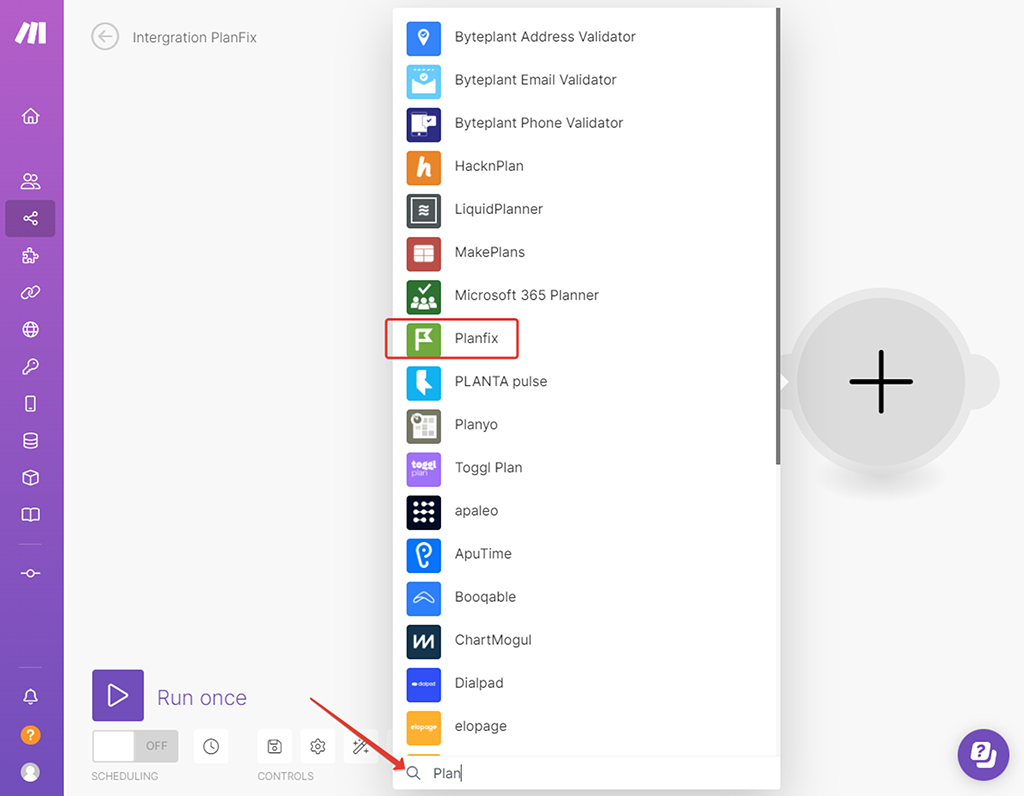
В открывшемся списке блоков интеграций PlanFix выбираем модуль «Search Records», чтобы получить список всех записей конкретного справочника:
Созданное ранее соединение с ПланФиксом в первое поле ввода данных настроек модуля должен подгрузиться автоматом, но если этого не произошло, то выберите его из списка:

Далее нам нужно указать наш конкретный справочник «Товары» из выпадающего списка всех справочников в ПланФиксе, а в поле Limit стоит по умолчанию значение «10» — это количество записей из справочника, которое будет нам выгружено.
Максимальное значение 100 — как создавать сценарий, когда у нас в справочнике больше записей, я напишу далее в отдельном разделе этой статьи, пока нам хватит и 10, так как у нас всего 4 товара:

Всё отлично – кликаем «Ок»:
Шаг 2 — Проверяем корректность работы отдельного модуля сценария
Первый модуль нашего сценарий настроен, давайте проверим корректность его работы.
Мы можем или запустить разово весь сценарий, или разово запустить только работу конкретного модуля сценария — так и поступим. Правым кликом мыши по модулю отобразится меню действий с ним, выбираем запустить только этот модуль:
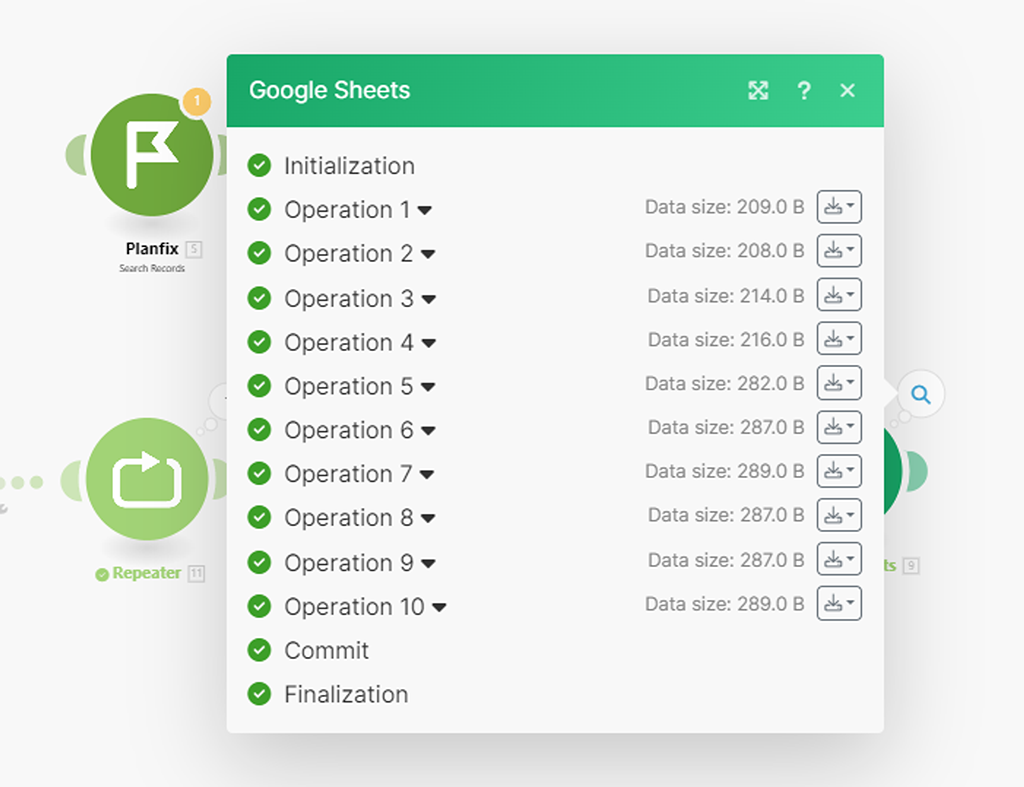
Произошла магия Make — он отправил API запрос к PlanFix на список записей по справочнику «Товары» и что-то там нашёл, о чём сигнализирует маркер с цифрой 1 (потрачена одна операция) — клик по этому маркеру покажет нам полученные данные. Изучим их, так как нам они важны:

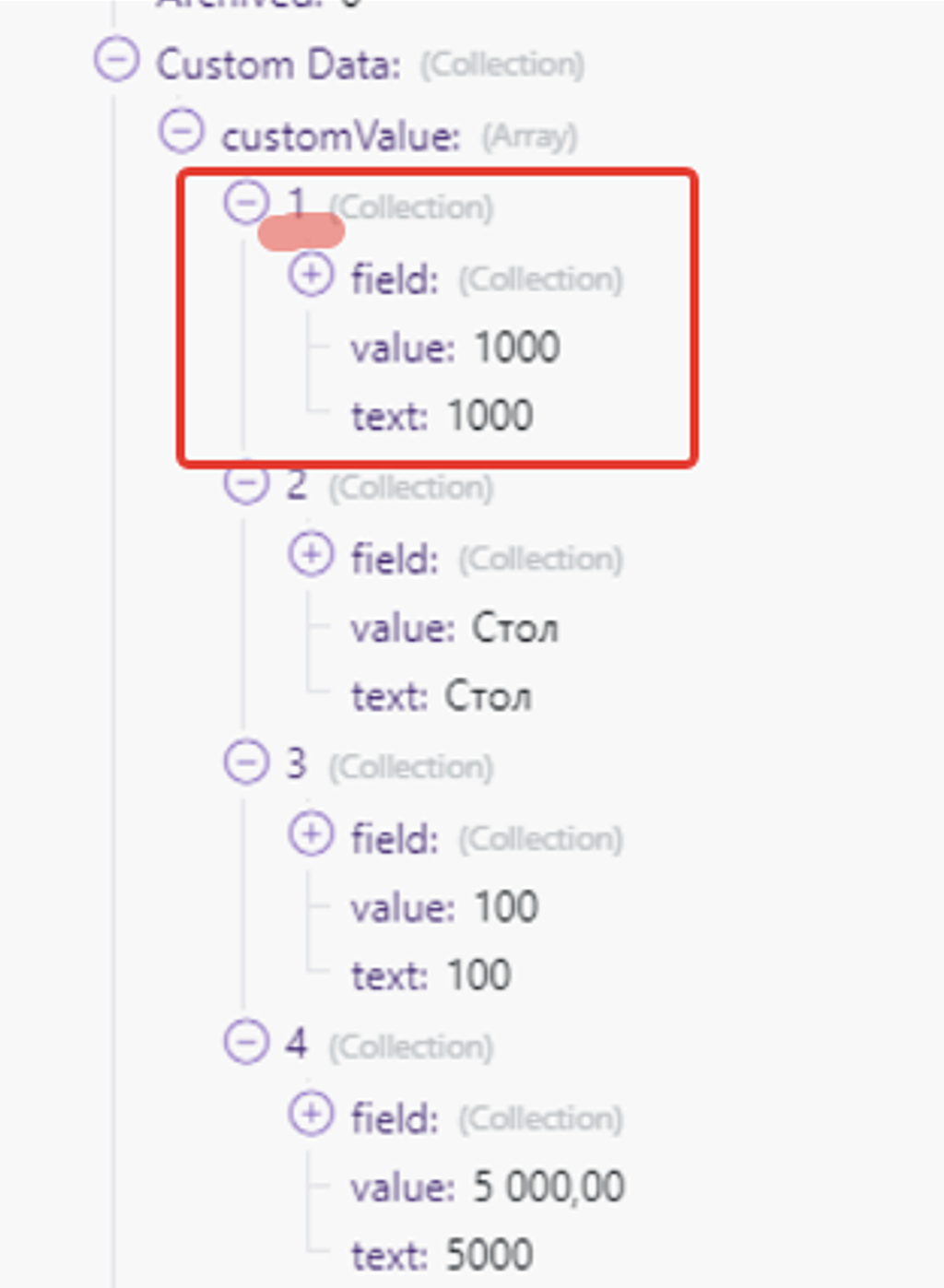
Каждый «Бандл» — это пакет с массивом информации по одной записи. Всего у нас 4 таких «Бандла», как и записей в справочнике. Record Key — это наш ID записи. Для этого сценария он нам как раз и нужен:
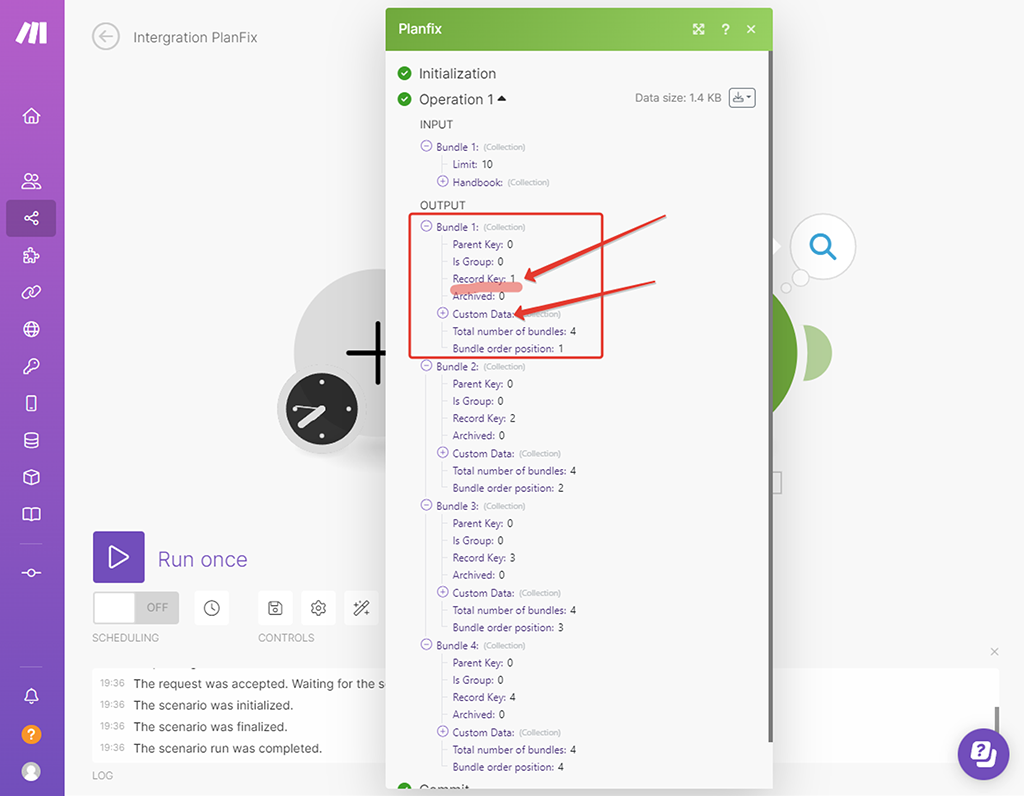
А вот все данные по самой найденной записи находятся в подмассиве бандла «Custom Data» — нам они также нужны буду позже, как и понимание этой структуры, чтобы указать какие данные в какие колонки нашей Google-таблицы будут записываться:
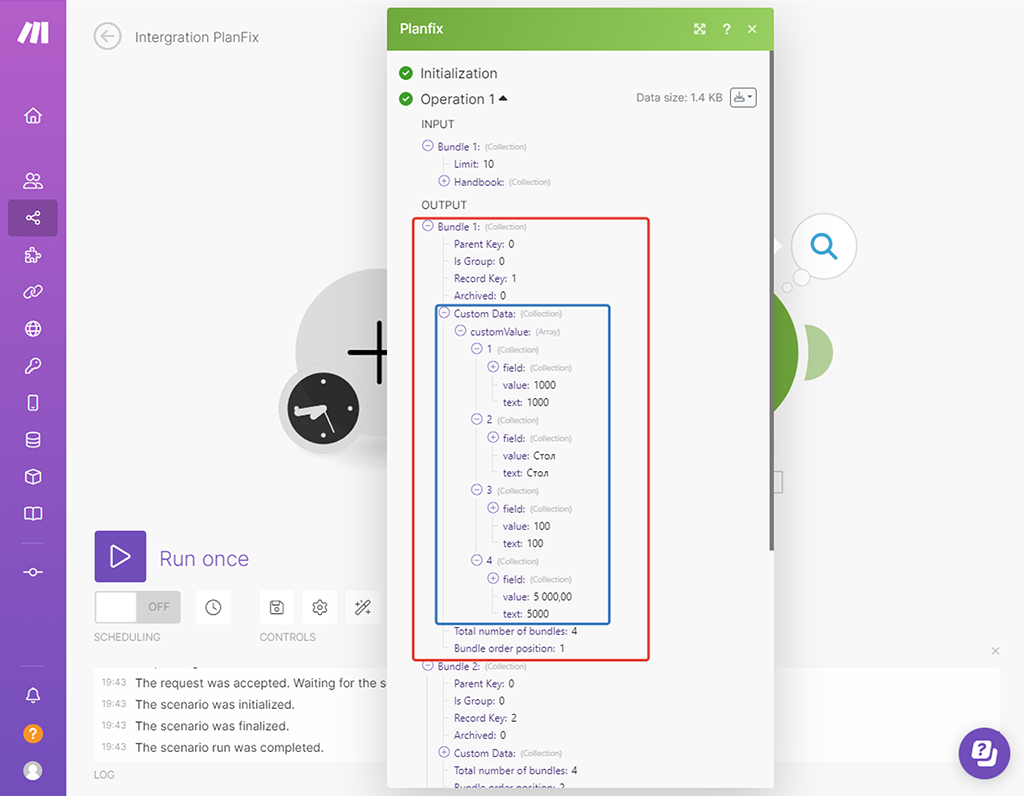
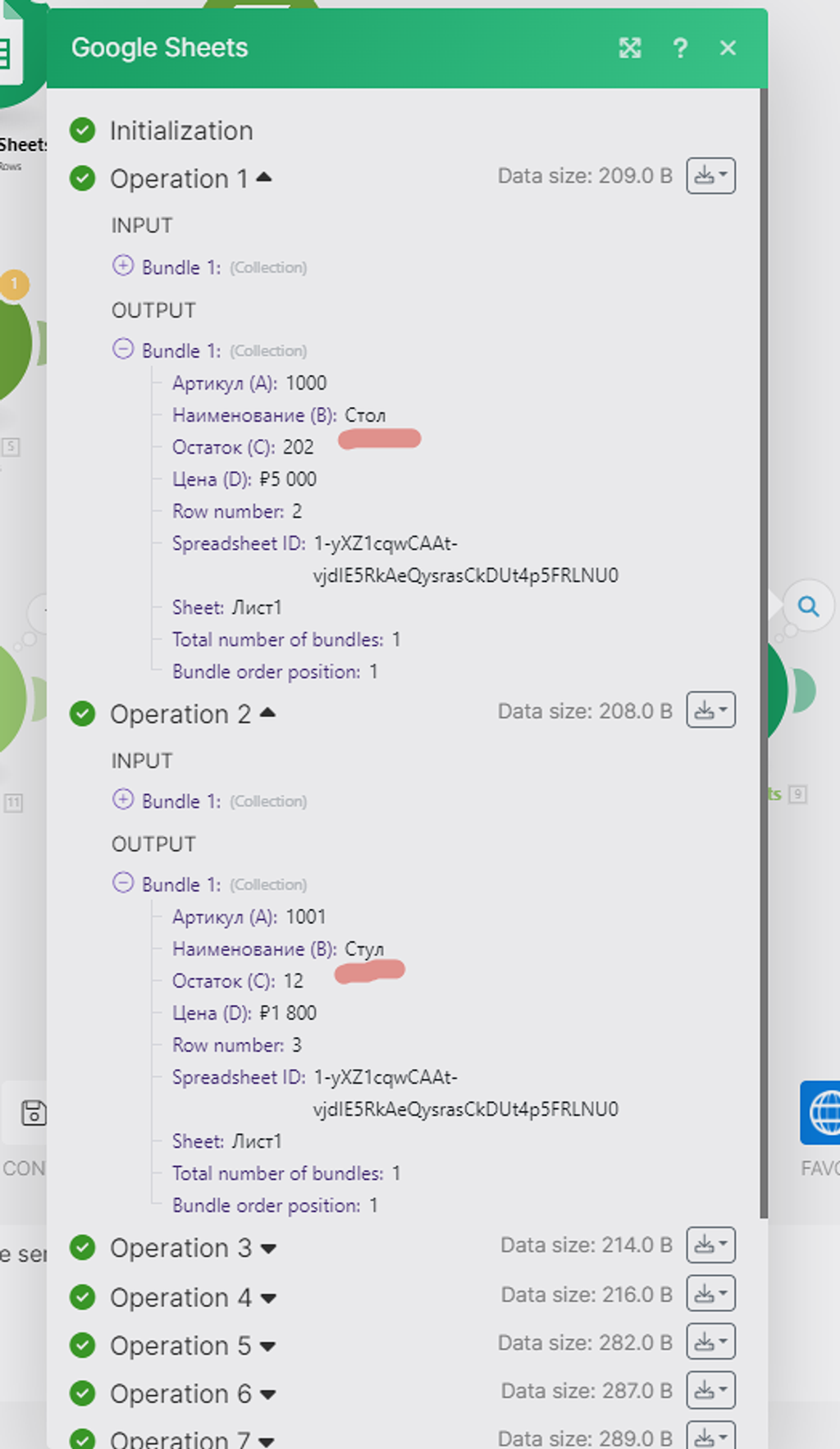
Синий прямоугольник обозначает все данные этого массива. Мы видим запись по товару «Стол», с артикулом «1000», с остатком «100», и ценой «5 000».
Для более сложных таблиц и задач, содержащих десятки или сотни характеристик одной записи, можно сделать специальный сценарий, который сделает нам Google-таблицу с названием всех полей (колонок) и всех их ID, чтобы мы могли ориентироваться какие поля что значат, но сейчас нам это не требуется — пока всё очевидно и так.
Шаг 3 — Добавляем модуль (2) сценария поиска записей в Google Таблице в соответствии с критерием поиска
Переходим к созданию второго модуля сценария «Поиск записей в Google Таблице». Справа от 1го модуля кликаем на маленький + (он появляется сразу, как мы подводим в это место курсор мыши):

Теперь нам надо найти готовые модули интеграций, но уже для Google — кликаем на добавить модули другой системы:
Находим блок интеграций для Google Таблиц и кликаем по нему:
Прокручиваем список готовых модулей интеграций Google Таблиц до модуля «Search Rows» и выбираем его:
В открывшемся экране настроек модуля интеграции Google прежде нам нужно будет создать соединение уже с Google, по аналогии как мы его создавали с PlanFix (чуть проще выйдет, правда). Если он у вас уже настроен, то выбираете из списка, если нет, то кликаете на добавить. Далее процедура простая и очевидная — отображу её в скриншотах без пояснений:
Нас возвращает в Make и созданное соединение сразу выбирается в списке автоматически. Далее в верхних блоках настроек этого модуля надо найти в списке файлов вашего Google Диска необходимую Google Таблицу, выбрать её и указать, на каком её листе будем искать необходимые нам записи:
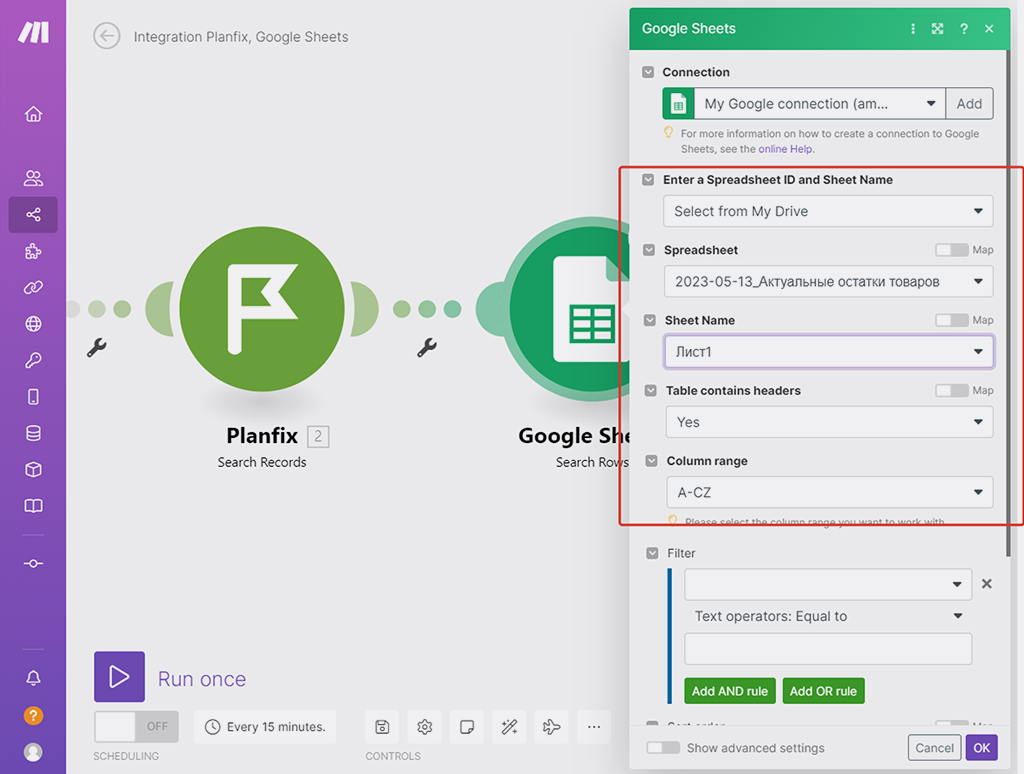
Теперь нам надо настроить фильтр поиска:
- По какой колонке таблицы мы будем искать.
- На соответствие с какими данными будем искать запись.
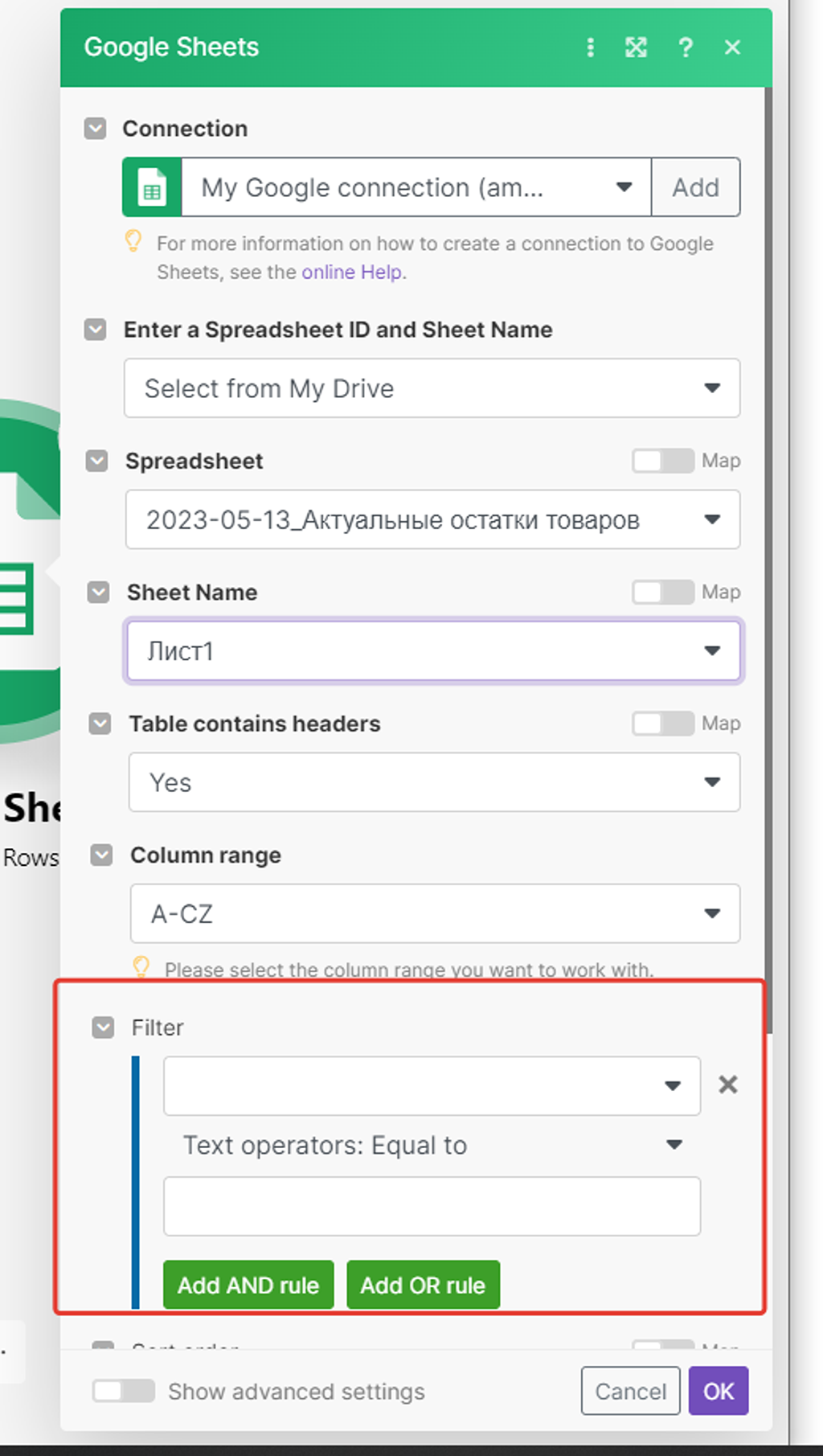
Напомню, что мы ищем:
- В первом модуле мы получаем запись из справочника PlanFix со всеми её данными.
- Вторым модулем мы загружаем Google-таблицу с аналогичными данными. В ней мы ищем запись, у которой артикул (уникальная характеристика товара) будет совпадать с Артикулом записи, полученной из справочника PlanFix.
Настраиваем это блок настроек модуля соответственно:
- В первом поле ввода данных из списка колонок Google Таблицы выбираем «Артикул» – поиск будет происходить по ней:
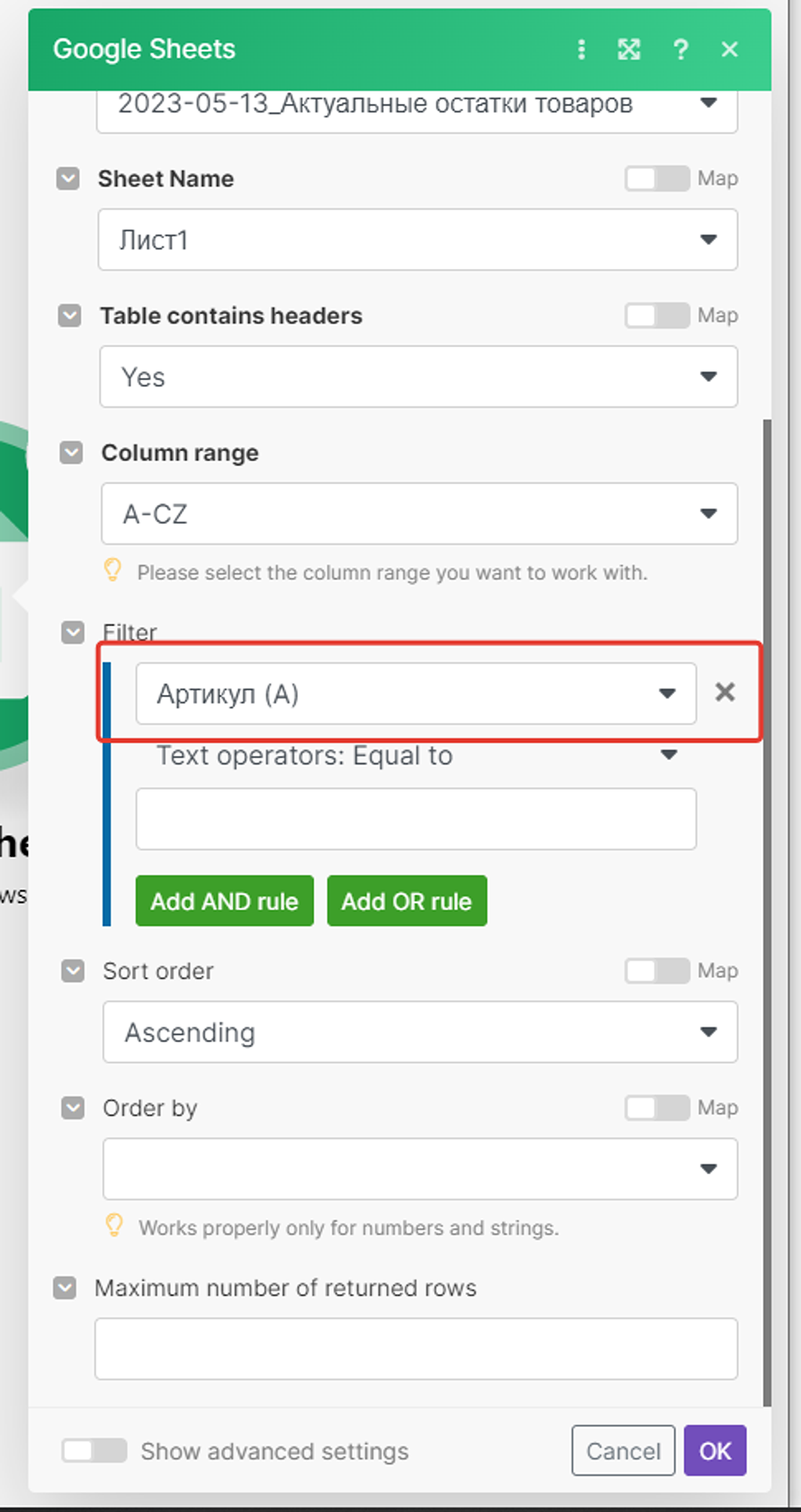
- А в поле ввода критерия поиска подставим полученное значение Артикула записи из справочника PlanFix, которое мы получаем в первом модуле.
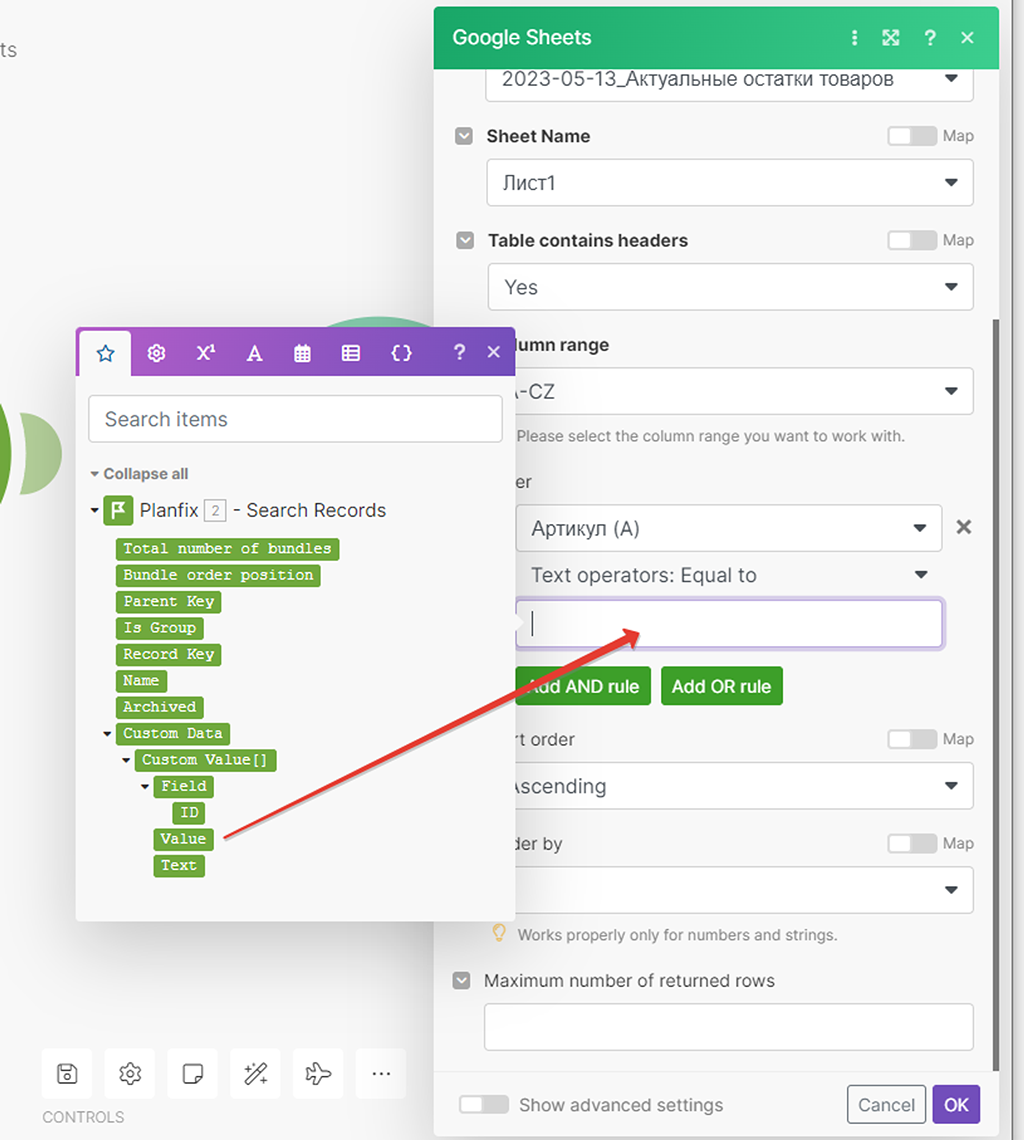
При клике в этом поле нам откроется окно выбора источника входящих данных. Перед модулем Google у нас только один модуль, поэтому только структура данных результатов его работы и будет нам предложена в кратком отображении.
Нас интересует поле Value (значение) его и подставляем перетаскиванием в поле ввода информации — не смущайтесь отобразившейся более сложной записи этого поля, она формируется автоматически в таком виде (это просто полный путь к ней):
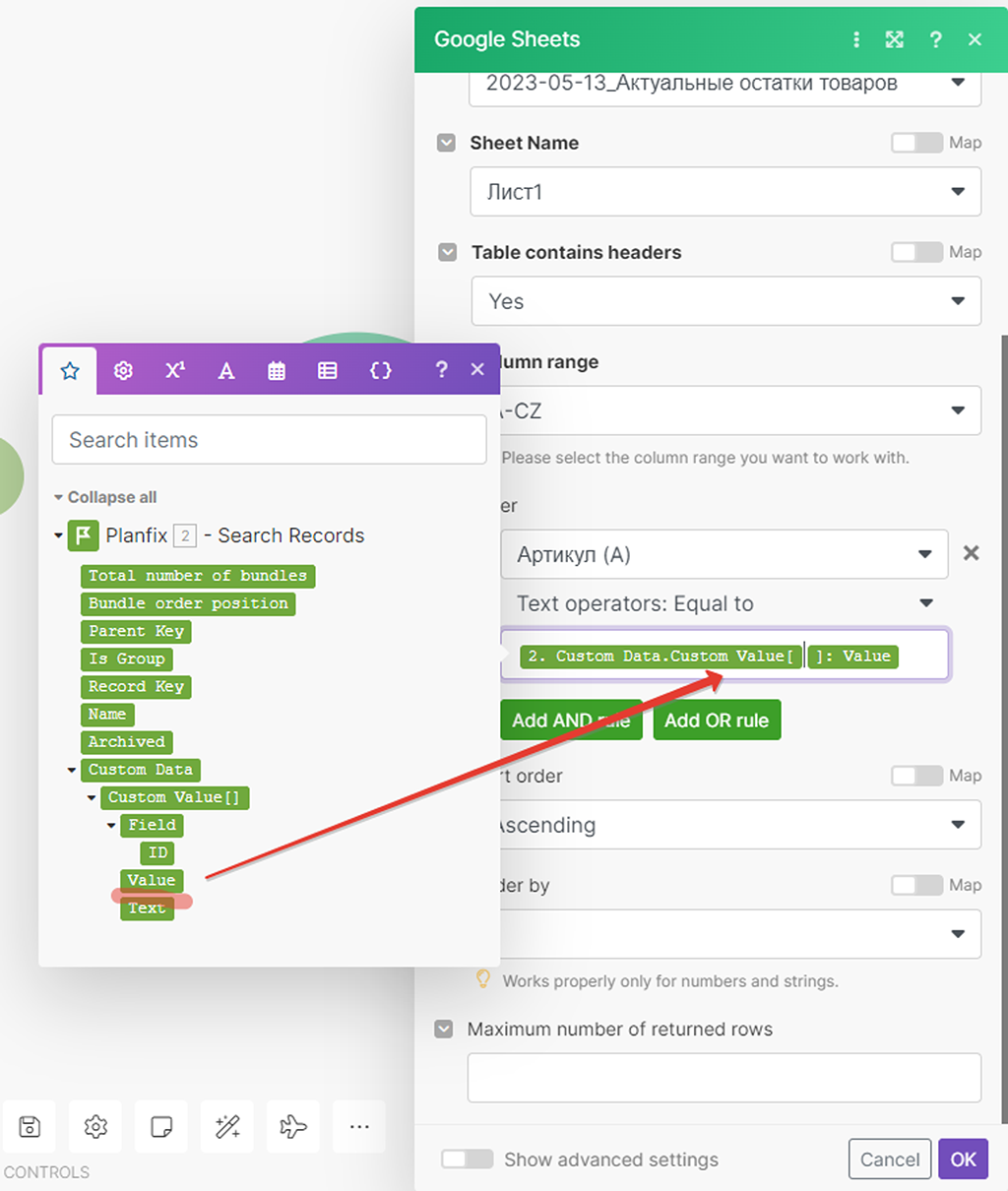
Но указанной информации пока ещё недостаточно, посмотрите внимательно на вставленную запись в поле ввода данных — нам необходимо указать, а из какой позиции полученных значений записи справочника мы получаем информацию:
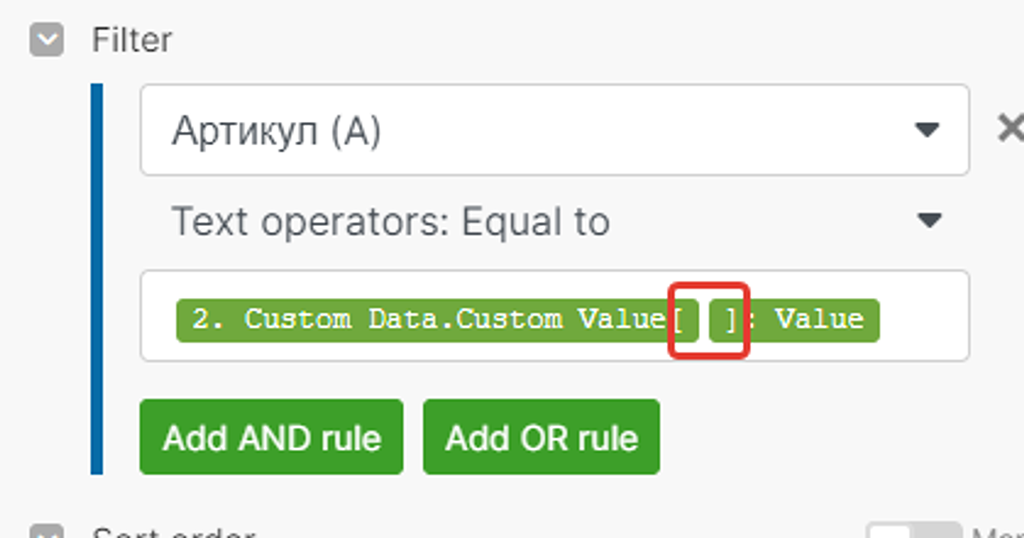
Прежде, чем сделать дальнейшие действия, посмотрим ещё раз на полный свиток подмассива «Custom Data» в результат поиска первого модуля. Можем закрыть этот модуль кликнув на «Ок» (все данные настройки сохраняться) и снова посмотреть результаты работы первого модуля — они всё ещё доступны:
Нам нужна структура данных подмассива «Custom Data» для любой записи:
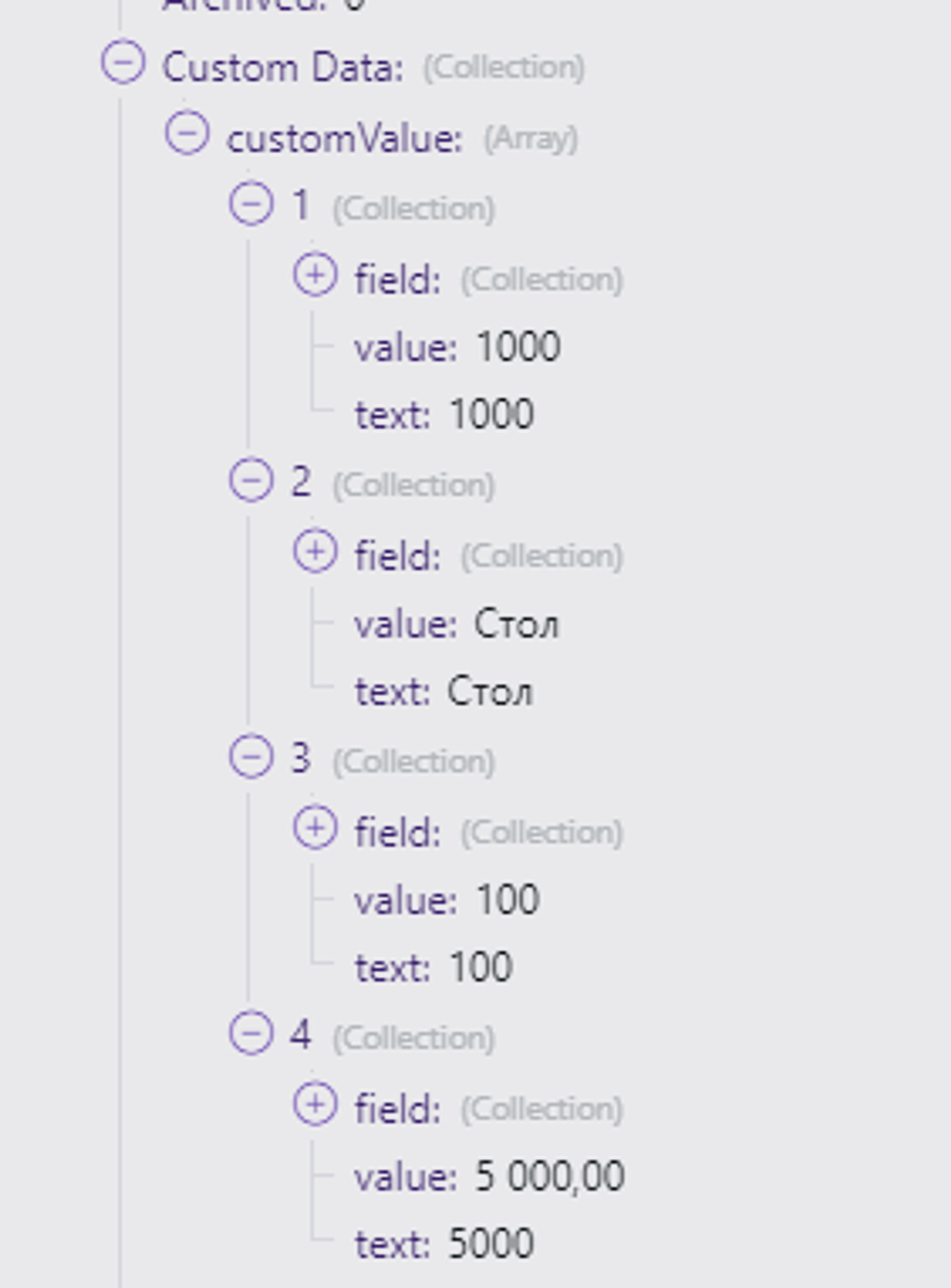
Мы видим, что:
- Артикул — это свиток «1».
- Наименование — это свиток «2».
- Остаток — это свиток «3».
- Цена — это свиток «4».
Как раз Артикул нам и нужен — № свитка «1».
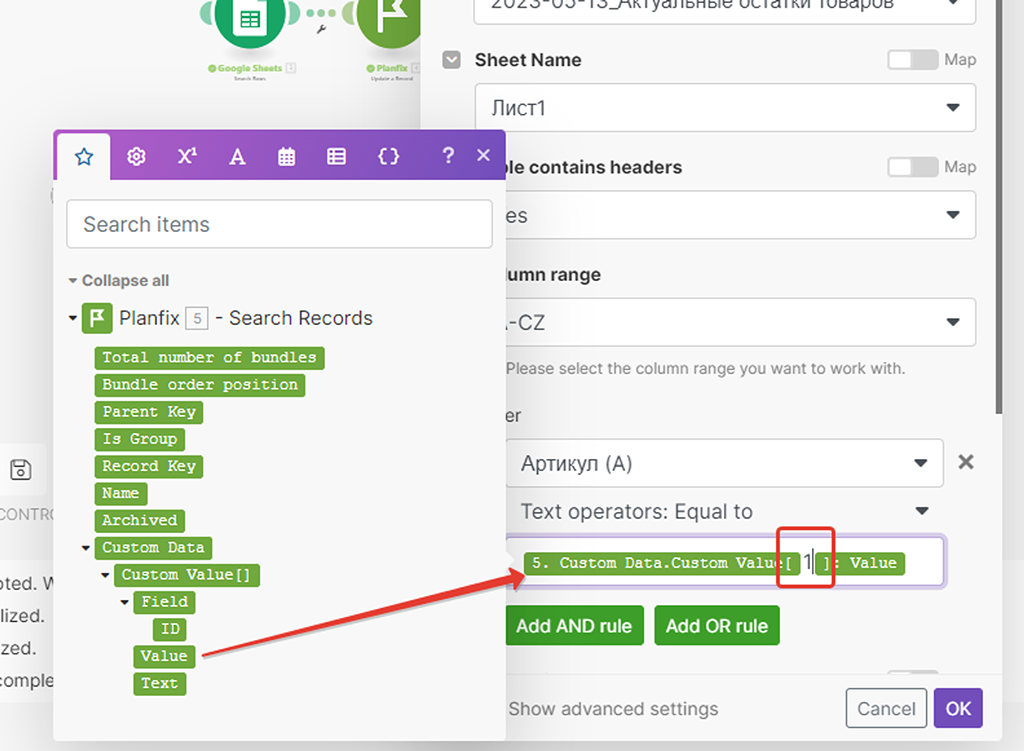
Продолжаем настройку параметров второго модуля. Возвращаемся к ним — просто кликните по модулю и снова откроется панель его настроек:
Вставляем наше значение «1» в поле получения данных:
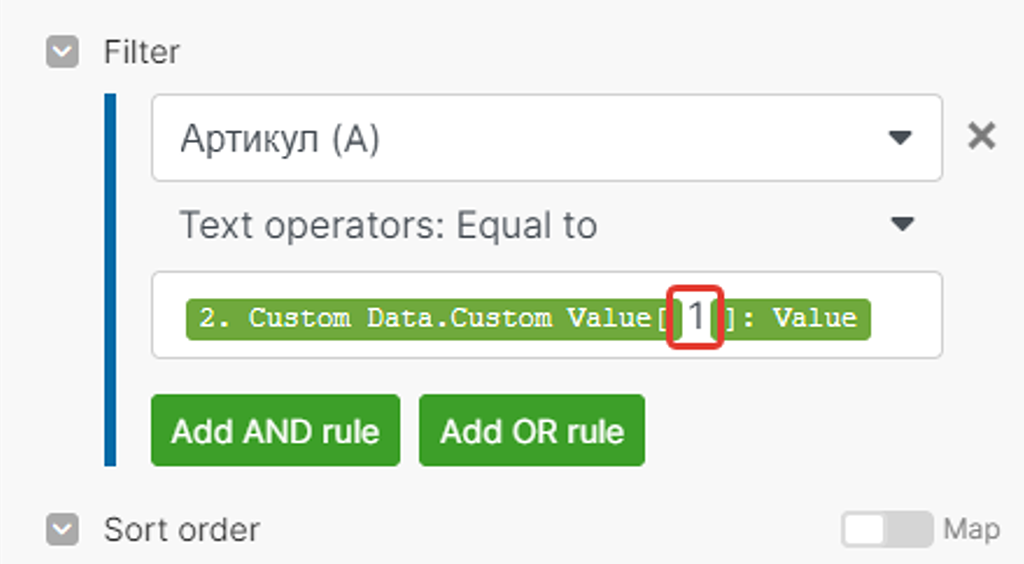
Ок. Модуль настроен. Давайте проверим корректность его работы.
Шаг 4 — Проверка корректности работы модуля (2) поиска записи в Google Таблице
Сейчас нам надо проверить корректность работы всей цепочки, а не только одного модуля.
Модуль (1) PlanFix должен выгрузить 4 наши записи из справочника PlanFix, а модуль (2) должен найти 4 соответствующие записи в нашей Google Таблице. Ок, запускаем сценарий, кликнув по кнопке «Запустить разово»:
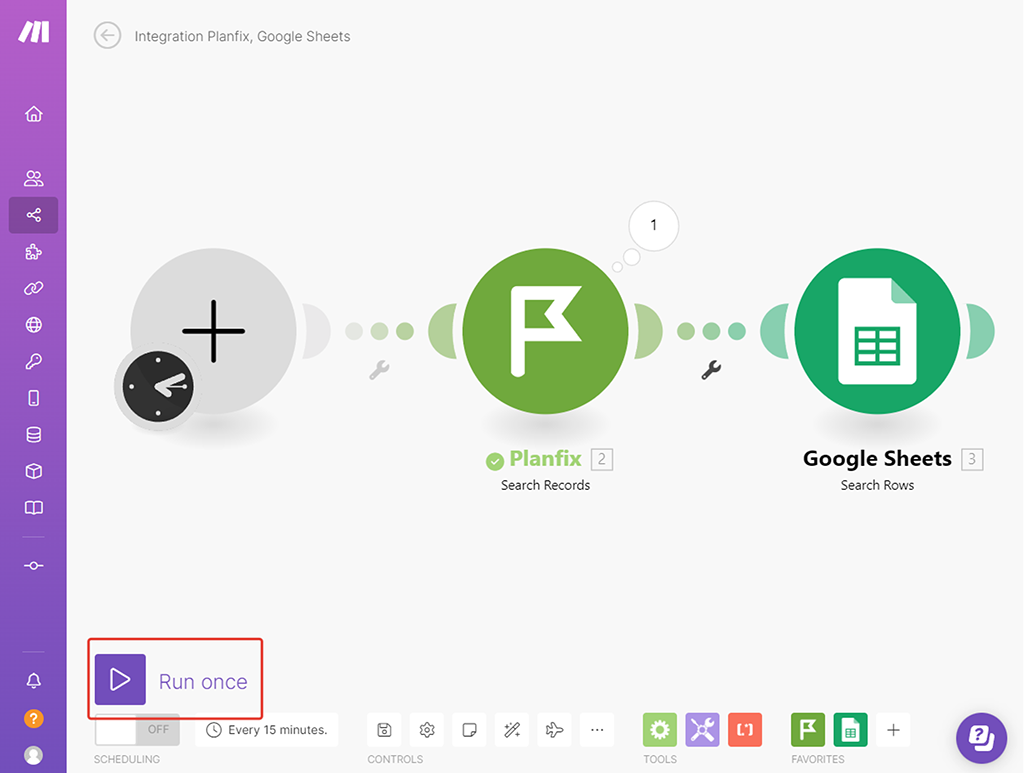
По маркерам результатов работы каждого модуля мы уже видим, что первый модуль сделал 1 запрос к PlanFix, а второй модуль как раз совершил поиск по 4 записям, т.е. отработал 4 раза:

Посмотрим результаты работы модуля (2).
Видим, что модуль сработал 4 раза, всё ок:
Разворачиваем каждый результат его работы и изучим, но прежде вспомним, что у нас сейчас в нашей Google Таблице:
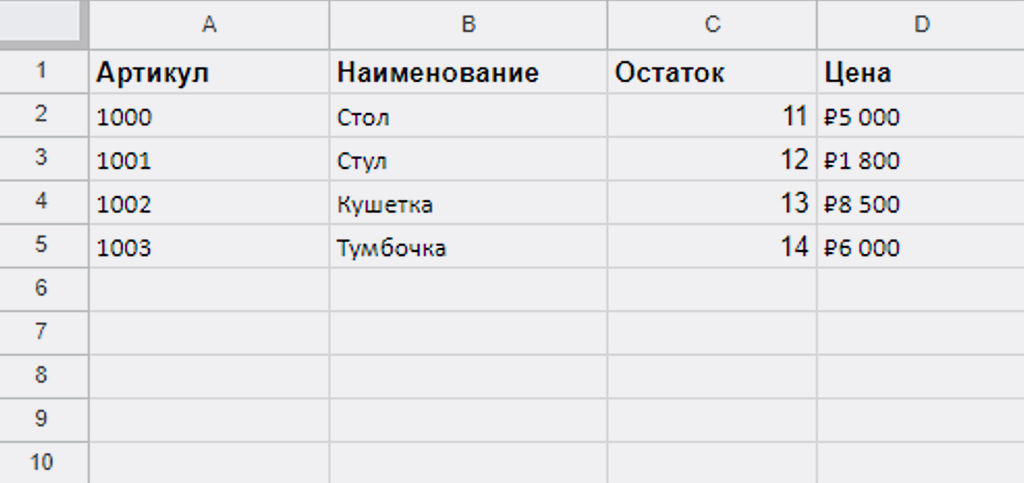
Смотрим результаты поиска по каждой операции.
Для первой операции модуль Google использовал как критерий поиска значение «1000» (это как раз артикул нашей первой записи в справочнике) и нашёл аналогичную запись с таким же артикулом и в Google Таблице «Стол» — модуль работает корректно:
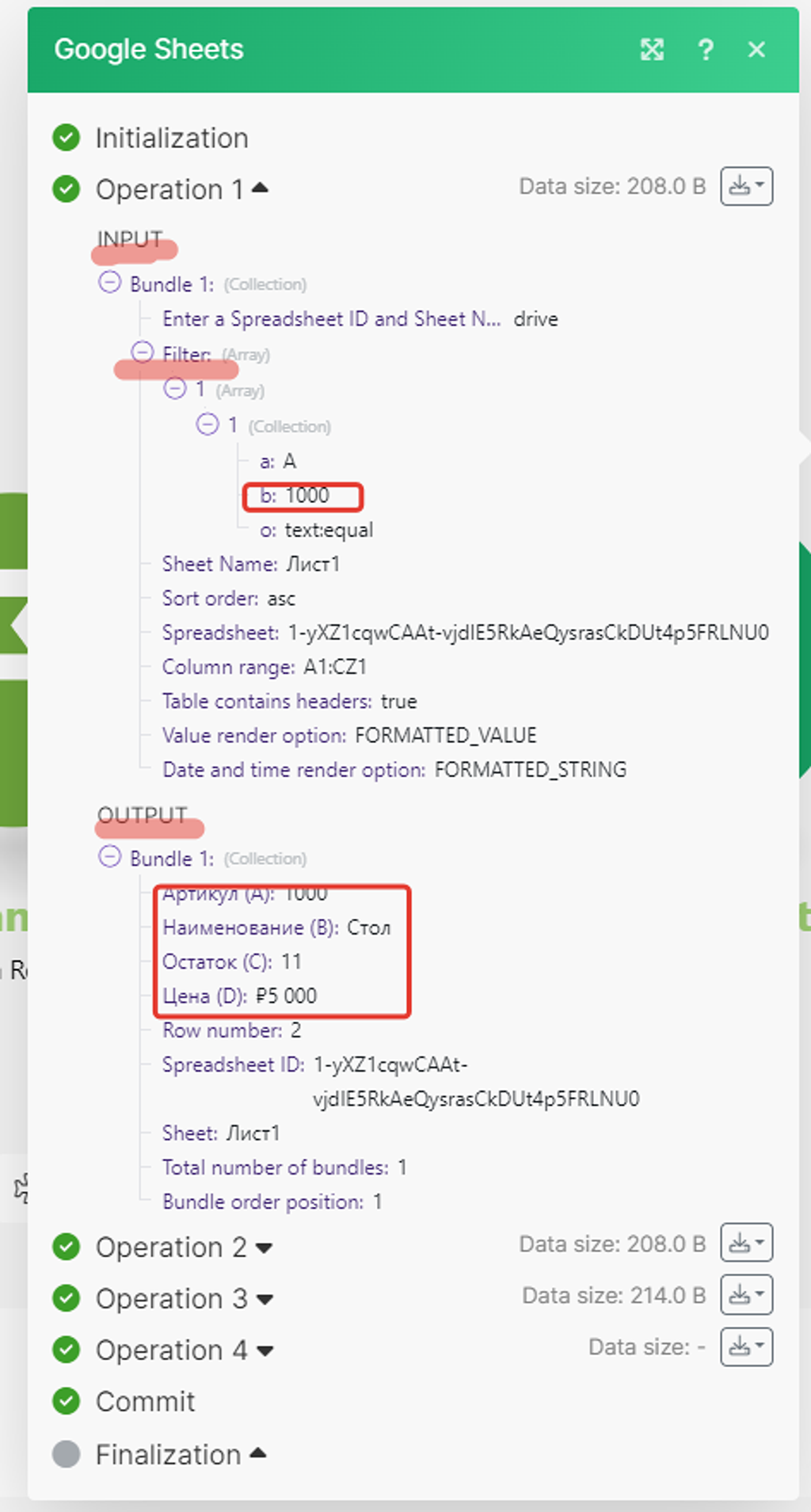
В оставшихся 3-х результатах работы модуля тоже всё ок, он брал уже артикул следующей записи и находил её аналог в Google Таблице:
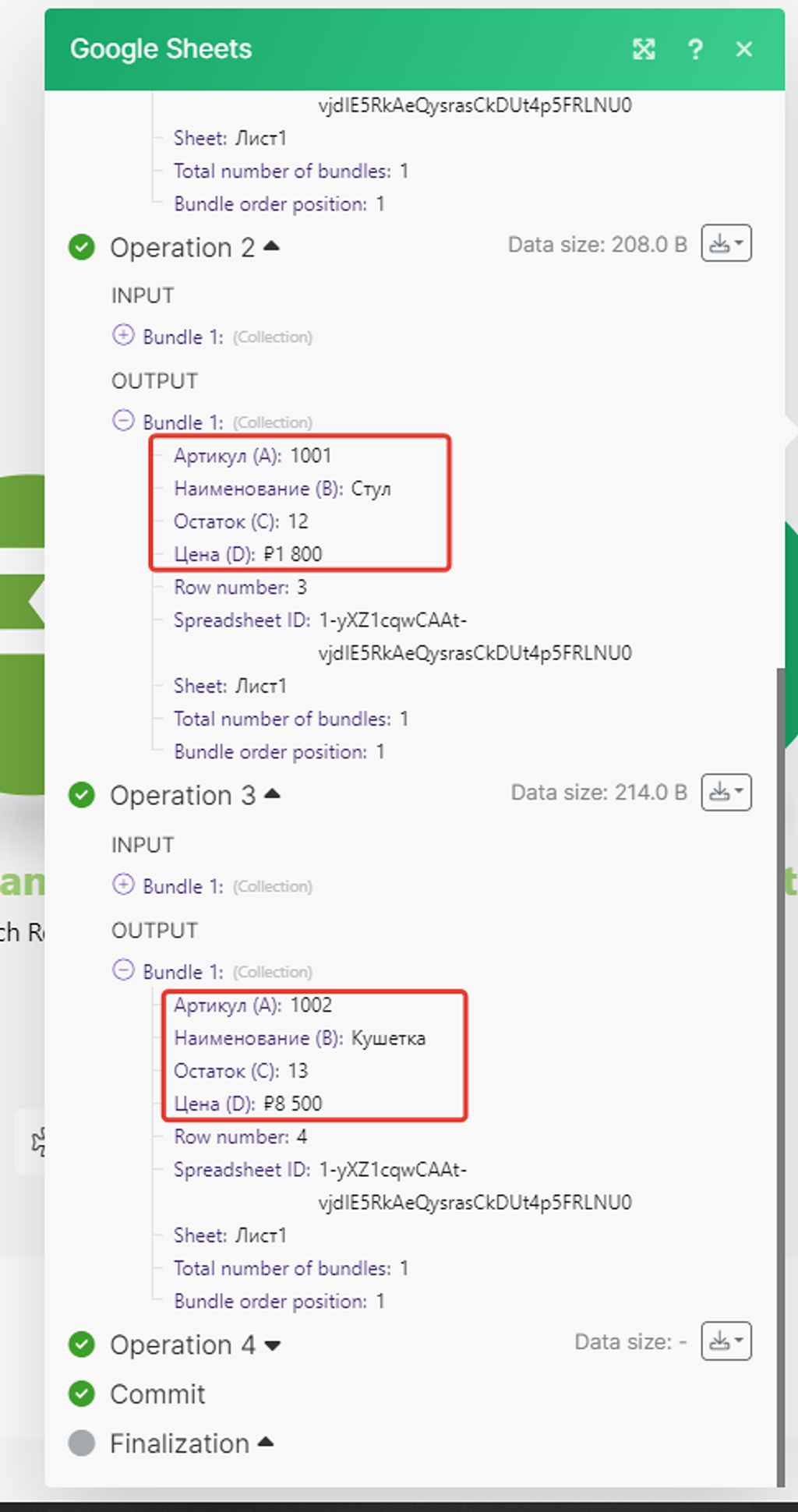
Шаг 5 — Добавляем модуль (3) — обновление ячейки записи в Google Таблице
Итак, в первых двух модулях мы получаем запись из справочника PlanFix и находим её аналог в Google Таблице. Теперь нам надо добавить модуль, который к этой записи в Google Таблице в новую ячейку будет добавлять значение ID записи в PlanFix.
Сначала назовем новую колонку в Google Таблице как “ID PlanFix” (это не принципиально, но для наглядности):
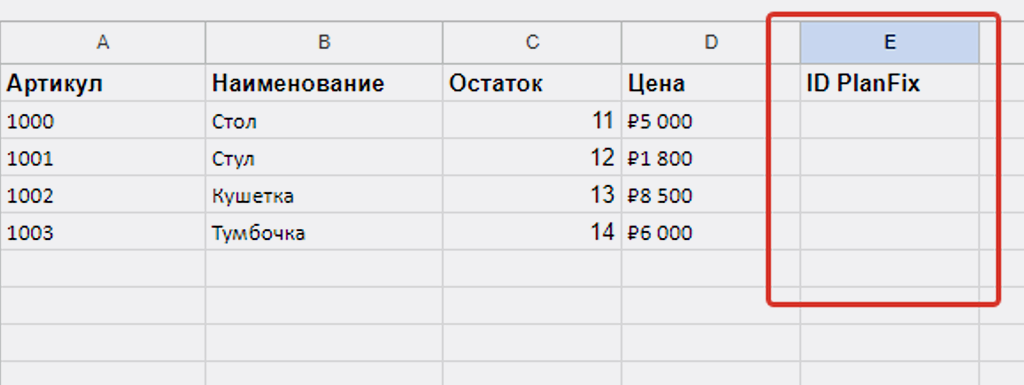
Возвращаемся в Make и добавляем новый модуль (3) из списка модулей Google Sheets «Update a Cell»:

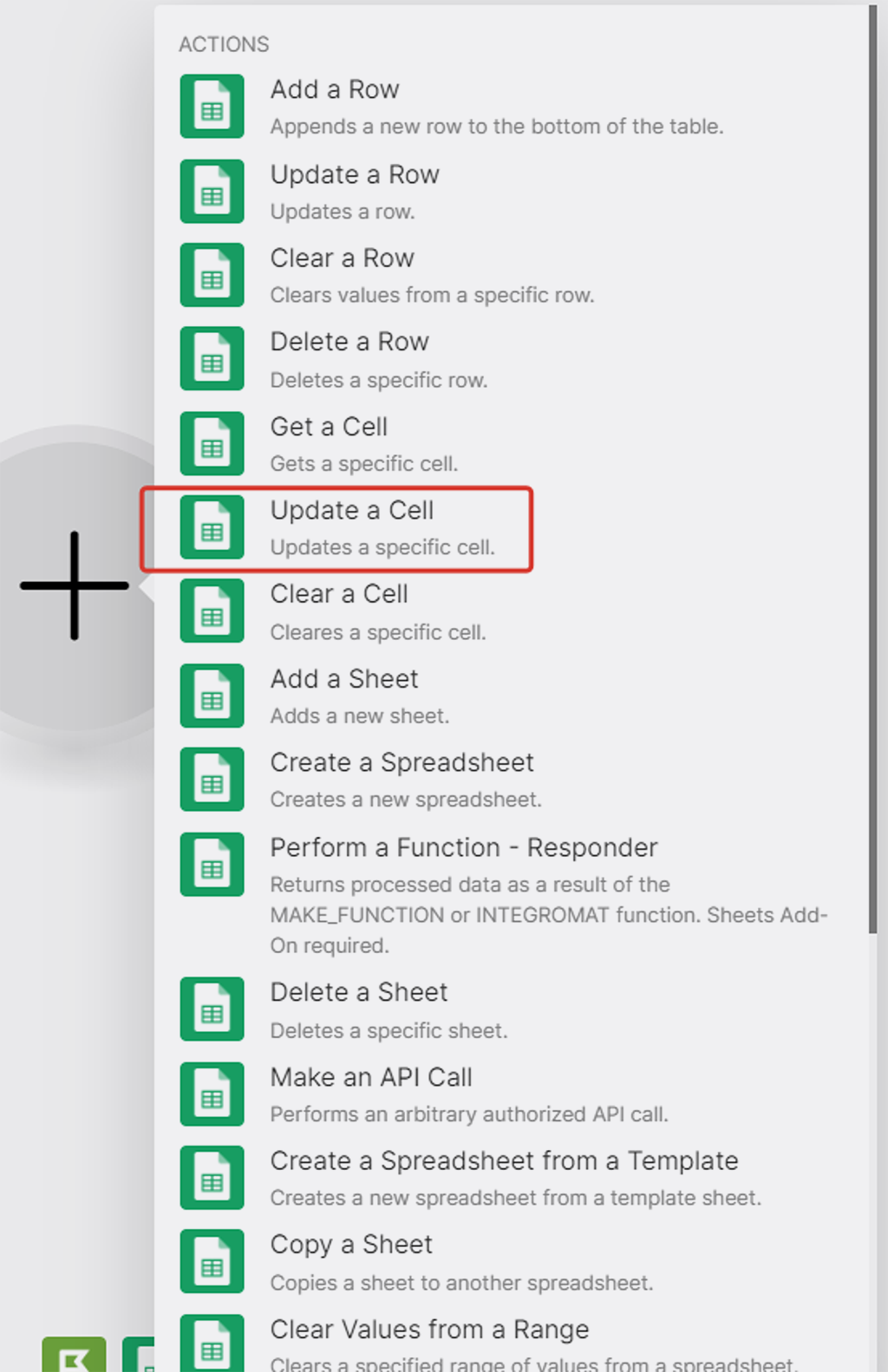
В окне настроек модуля:
- Соединение должно выбраться автоматически (если у вас не так, то выберите его из списка).
- Аналогично настройкам предыдущего модуля Google, укажите таблицу и нужный лист:
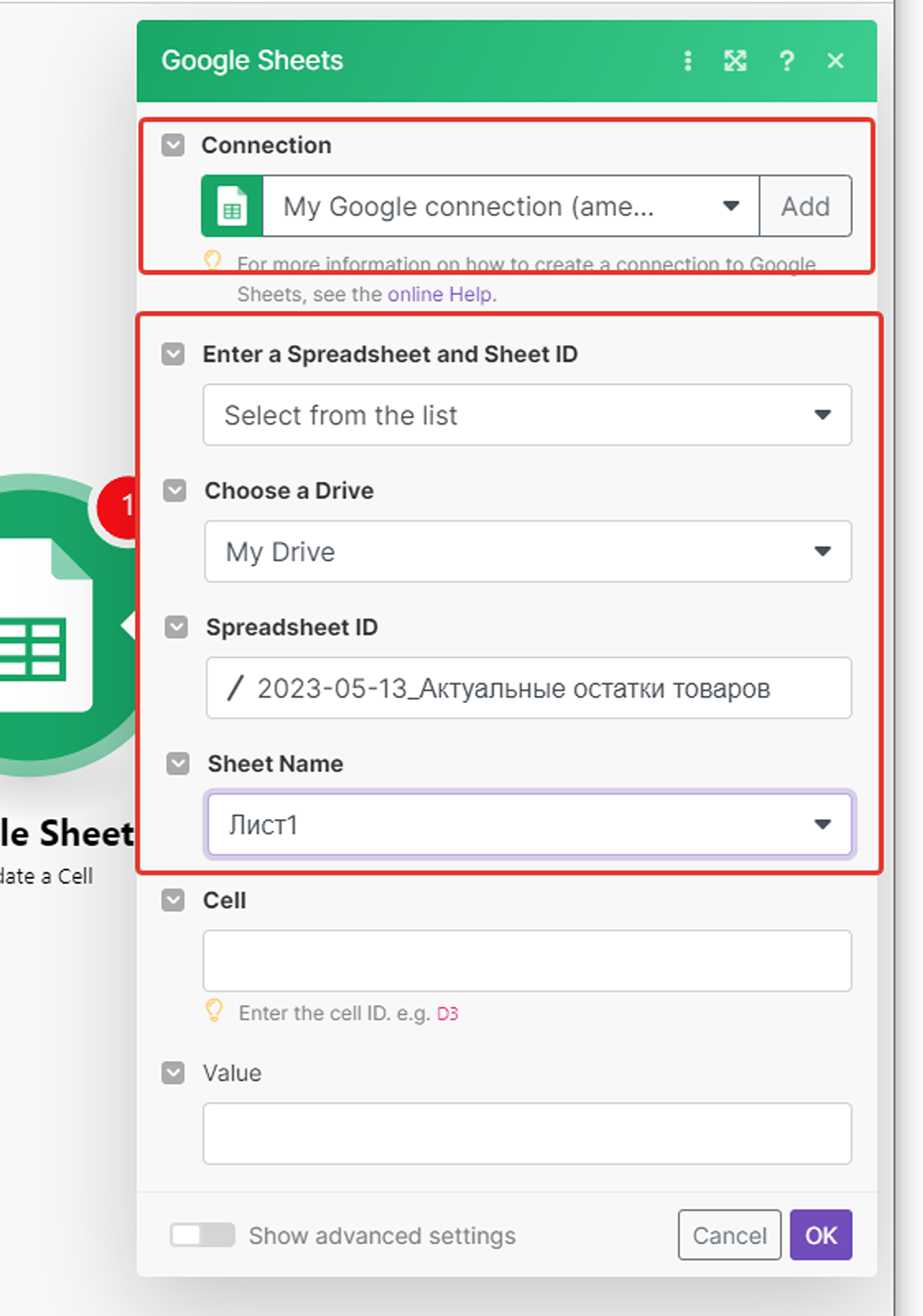
Теперь нам осталось указать, какую ячейку (Cell) записи мы будем обновлять и каким значением (Value).
Со значением всё просто — мы подставляем из результатов работы первого модуля полученное значение ID записи «Record key»:
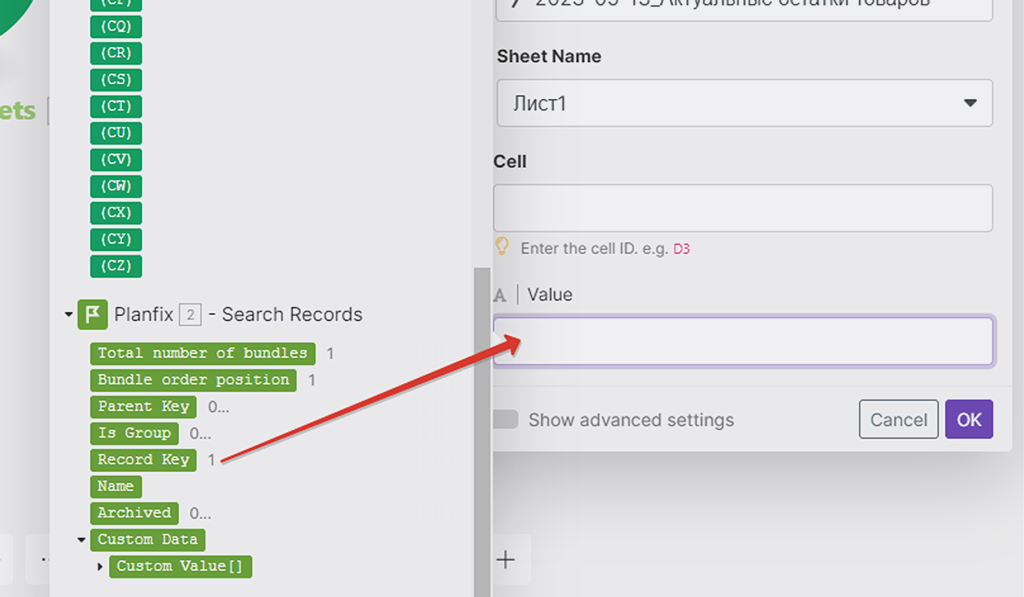
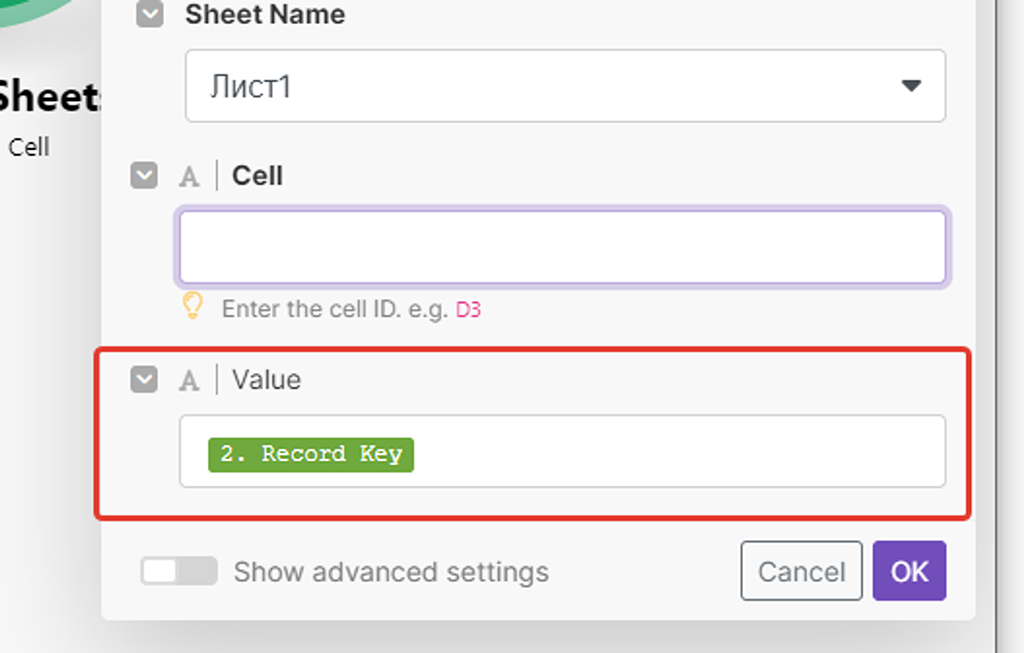
А вот адрес ячейки обновления мы соберём из двух показателей — литера колонки (E) + номера строки найденной записи предыдущим модулем. Литера колонки у нас «E» (англ), а номер строки берём из результатов работы 2-го модуля — в какой строке таблицы он аналогичную запись по артикулу нашёл, в такой строке и будет обновлять ячейку E (ID PlanFix):
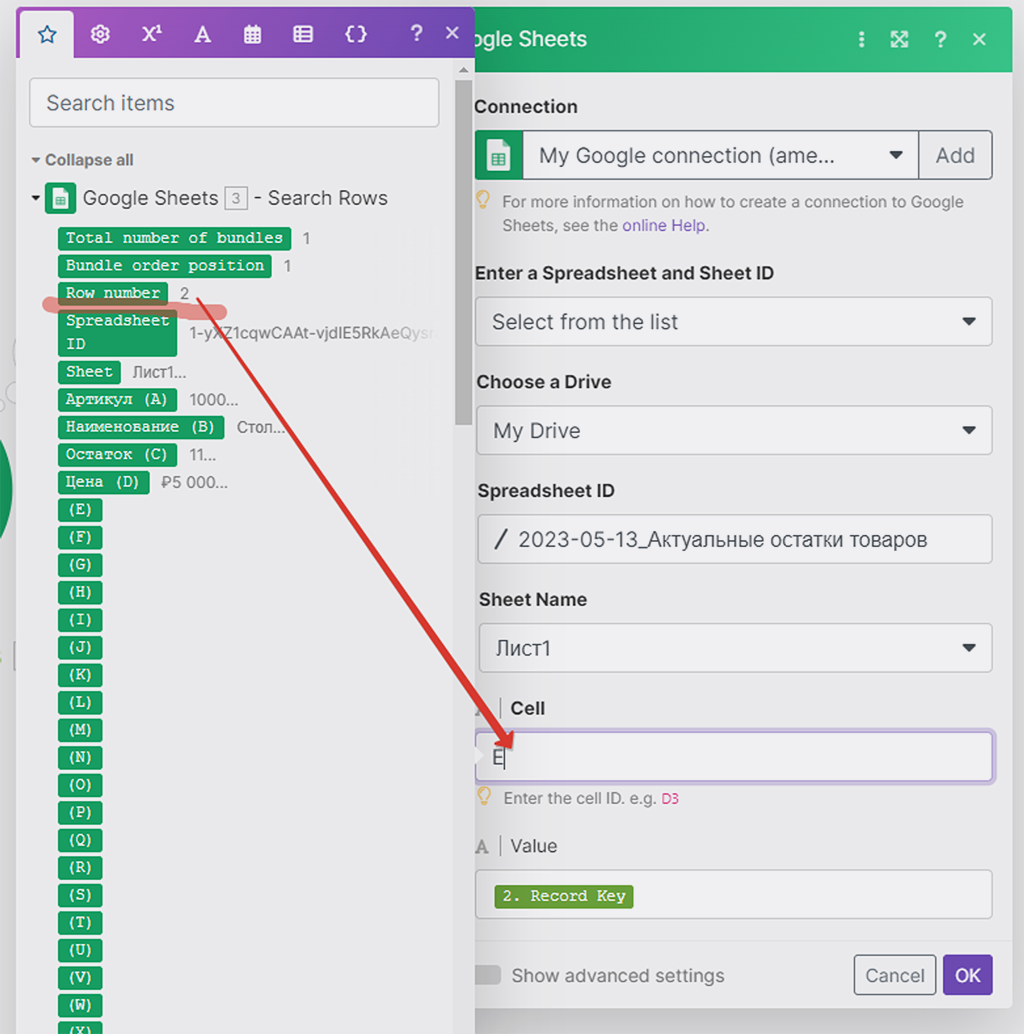
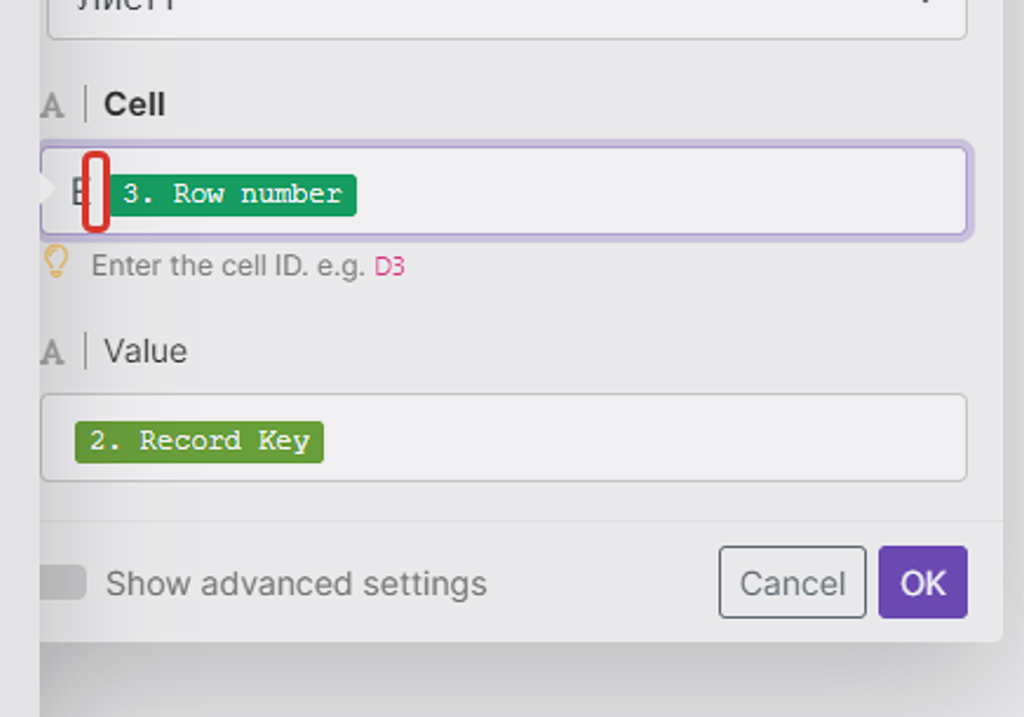
Между E и номером строки главное удалить пробел — по умолчанию он ставится!
Ок, с настройками этого модуля завершили.
Проверим корректность работы всего сценария.
Шаг 6 — Проверка работы сценария
Рекомендую первую проверку делать на малых значениях, чтобы уменьшить риск от неправильной работы нашего сценарий и множественного занесения некорректных данных в нашу таблицу, так как последний модуль вносит уже изменения в существующую Таблицу Google «Актуальные остатки».
Достаточно будет в настройках первого модуля указать значение «1» в поле Limit (количество получаемых записей) — проведём тестовый запуск на одной записи. Если что, негативный результат работы будет не сложно выявить и исправить:
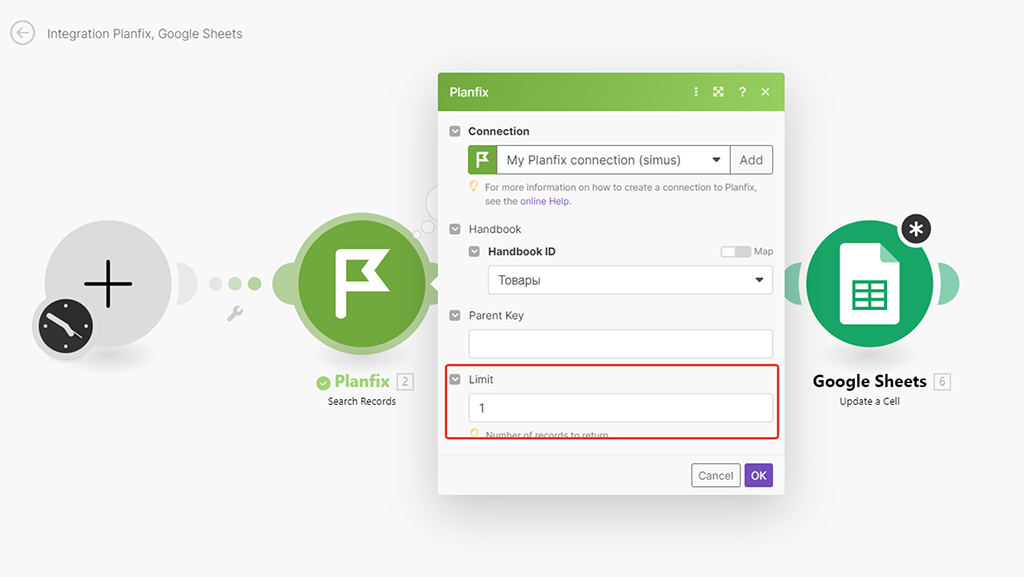
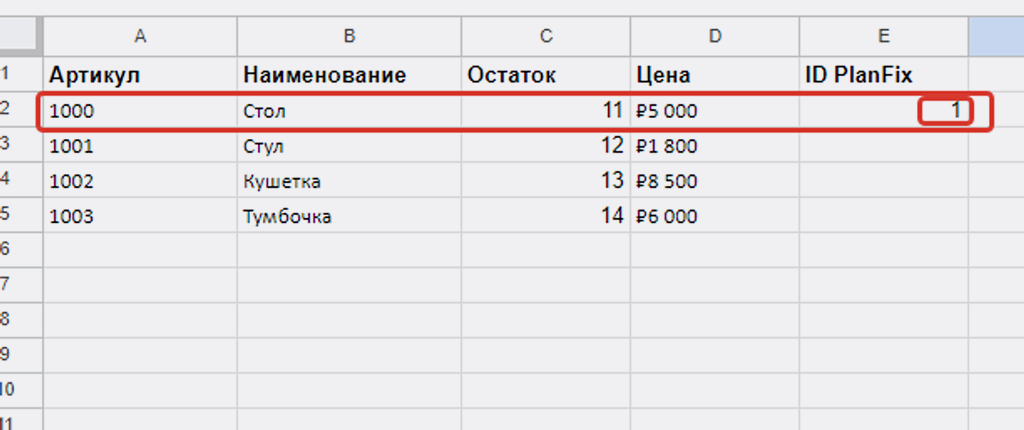
Запускаем разово сценарий. В результате его работы в нашей Google Таблице в колонке E «ID PlanFix» у записи «Стол» (артикул 1000) должно появиться значения ID этой записи. Мы его уже знаем — это «1».
После запуска по маркерам видно, что:
- Первый модуль сработал корректно — 1 раз обратился к базе (он по любому в нашем сценарии делает это один раз).
- Второй модуль, соответственно нашим лимитам в первом модуле, получил одну запись и произвёл поиск по Google Таблице.
- Третий модуль — внёс изменения по 1-ой найденной записи:
Ок, в Google Таблице предсказуемый результат:
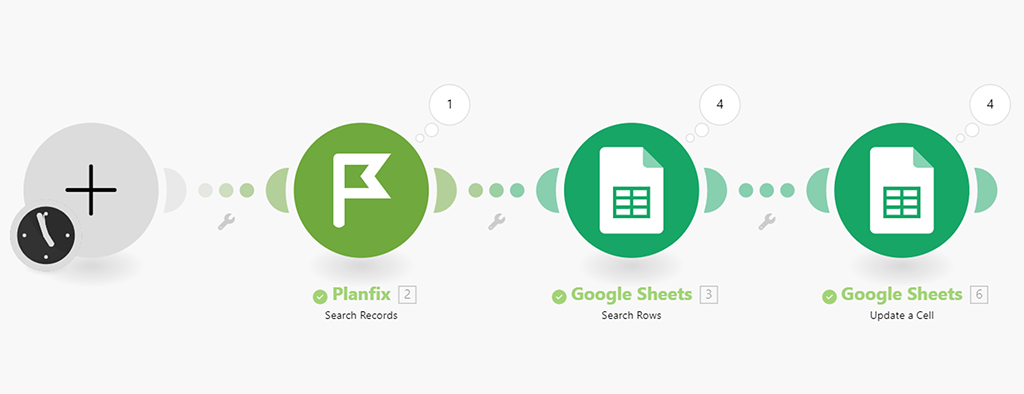
Вернём установку лимита на значение «10» в первом модуле и запустим сценарий уже в рабочем режиме:
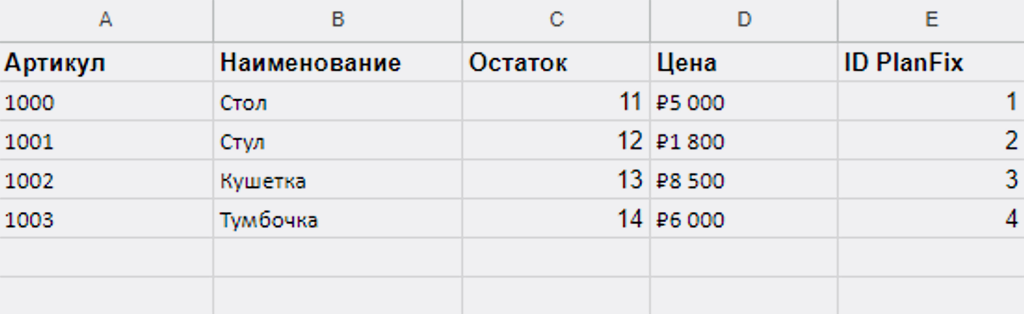
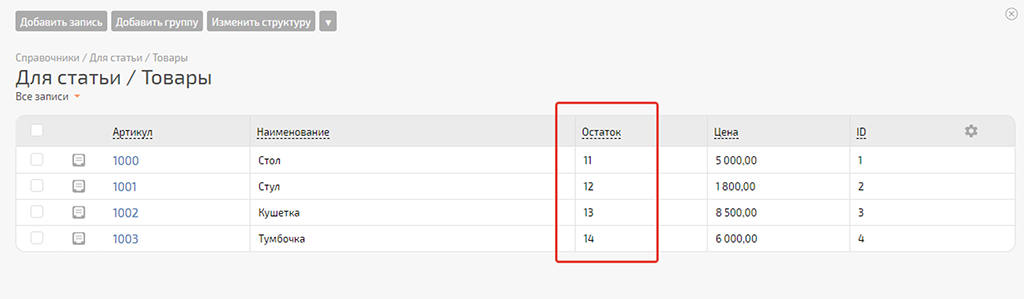
В PlanFix в настройках отображения справочника можно включить отображение колонки с данными по ID записей. Ок, всё соответствует:
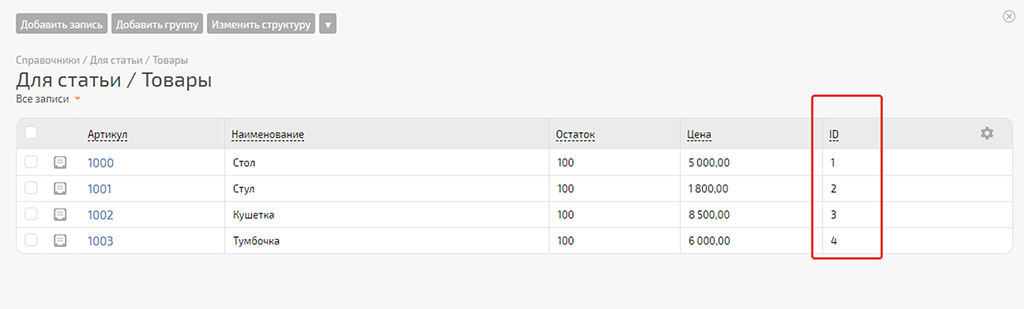
Всё отлично. Значения ID записей из справочника «Товары» в PlanFix перенесены в соответствующие записи нашей Google Таблицы «Актуальные остатки» — теперь настраивать сценарий «Обновления остатков» нам будет проще и надёжнее.
Сценарий обновления данных — вариант 1
Возвращаемся в наш Make и сохраняем наш сценарий, чтобы ненароком не потерять проделанную работу).
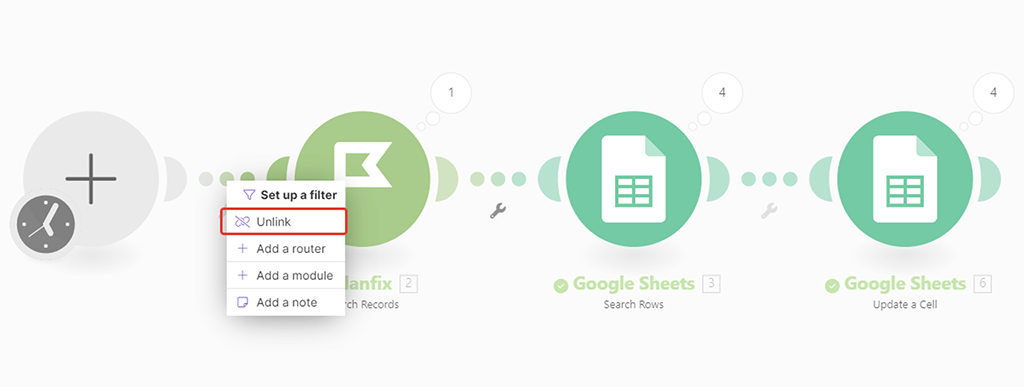
Продолжаем работу в нём же, но цепочку сценария получения ID записей в Google Таблицу пока «отстёгиваем» — кликаем правой кнопкой мыши на любом месте «цепочки» соединяющей стартовую позицию модулей и нашим первым модулем — из проявившего меняю выбираем «Unlink»:
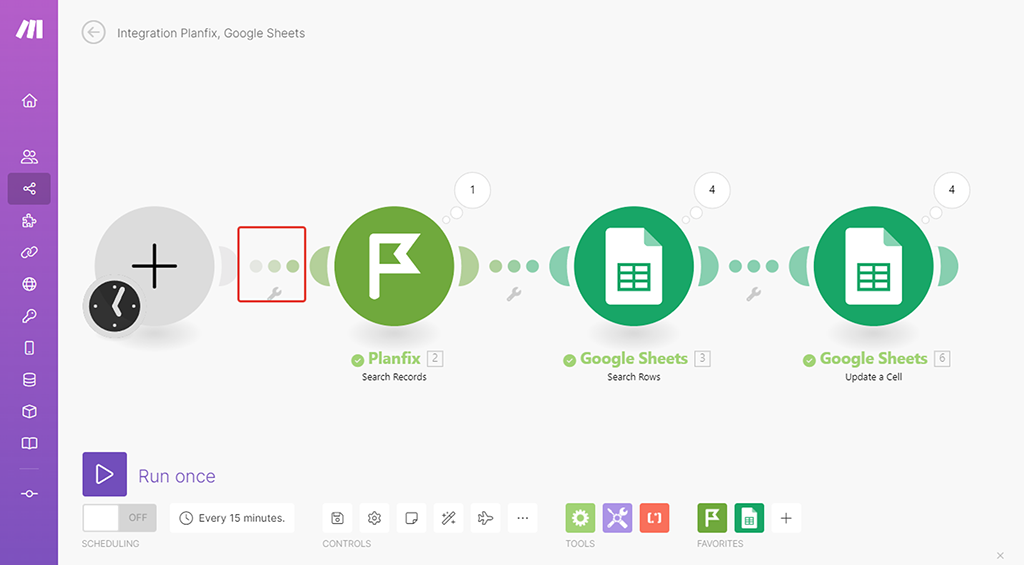
С зажатыми «Шифтом» выделяем «рамкой» всю цепочку этого сценария и перемещаем куда-нибудь повыше, чтобы не мешала создавать новый сценарий:
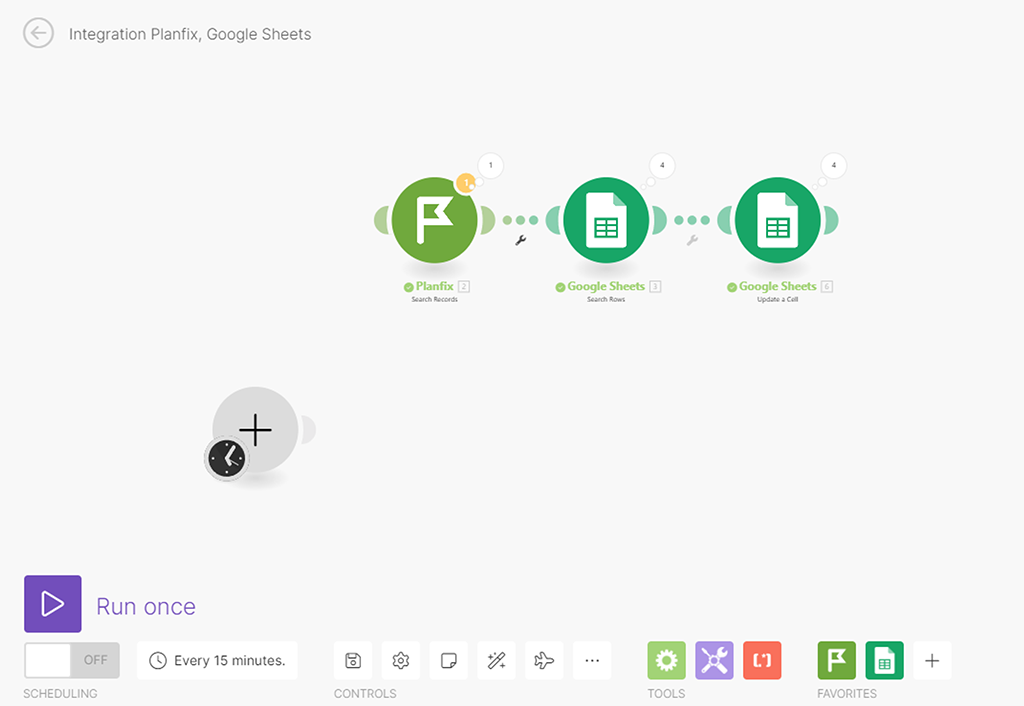
Создаём наш сценарий обновления данных.
По сути, это обратная задача, относительного сценария созданного ранее. Новый сценарий будет состоять лишь из двух модулей:
- Модуль (1) — получения записей из Google Таблицы.
- Модуль (2) — обновления конкретной записи в справочнике PlanFix по ID и данным из Google Таблицы:
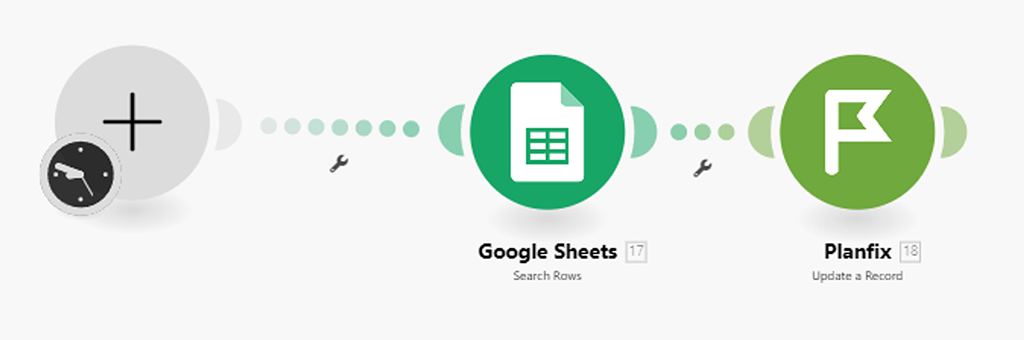
Шаг 1 — Настраиваем модуль (1) получения данных из Google Таблицы
Создаём новую цепочку сценария и первый модуль в ней для получения данных из Google Таблицы «Search Rows»:
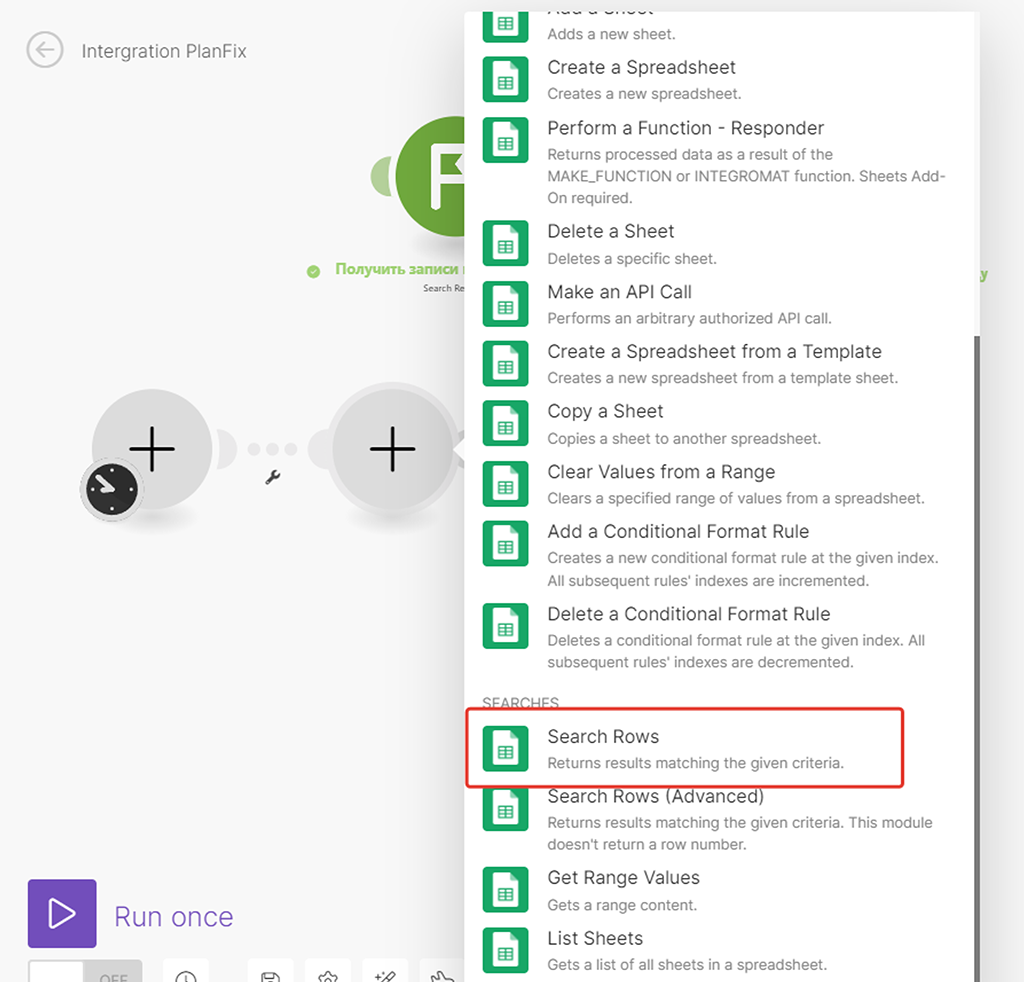
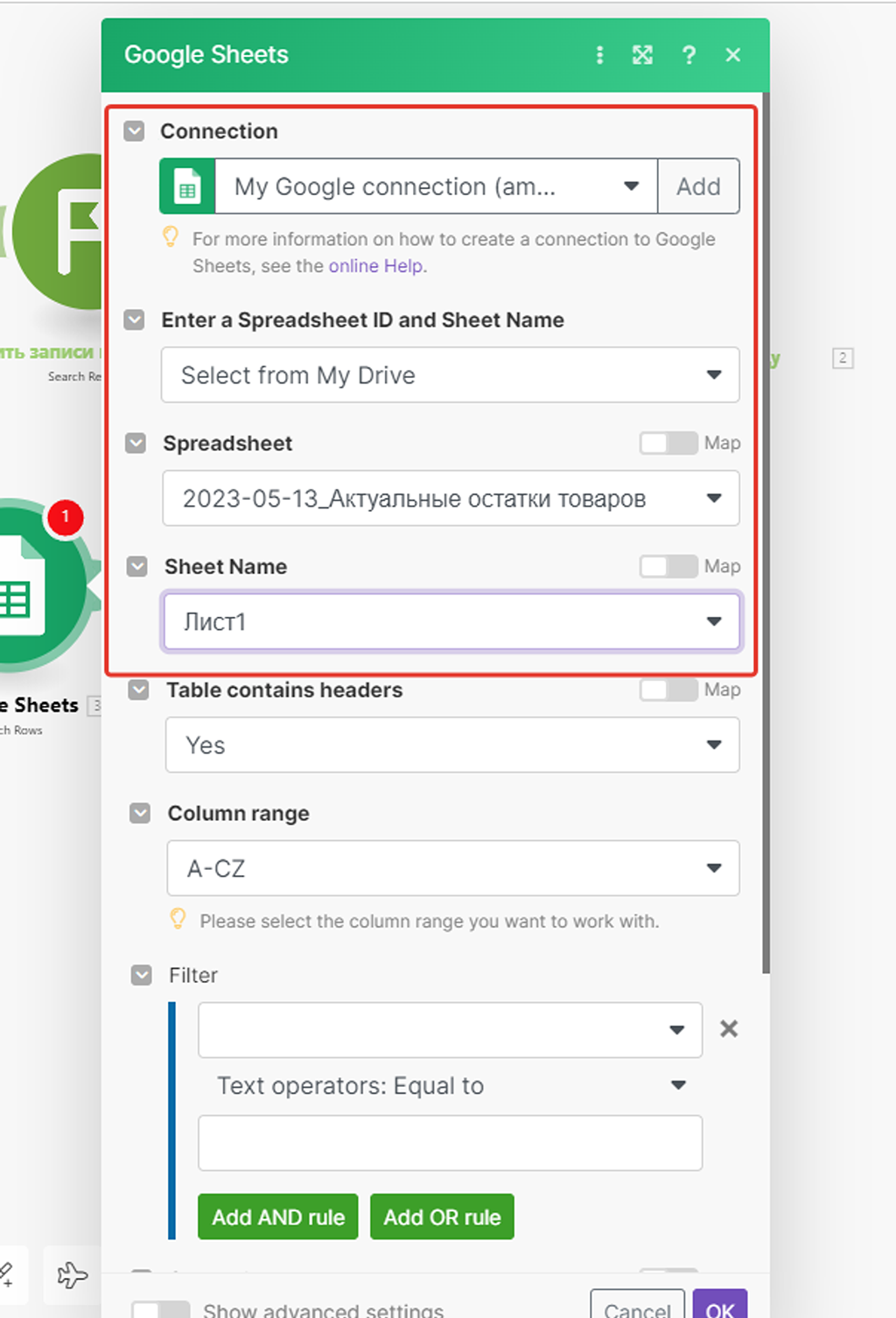
Настройки модуля схожи с предыдущими модулями Google — надо лишь указать соединение, таблицу и лист с данными — все остальные настройки не трогаем, т.е. мы выгружаем все записи нашей таблицы, без какой-либо предварительной их фильтрации:
Шаг 2 — Настраиваем модуль (2) обновления конкретной записи в справочнике
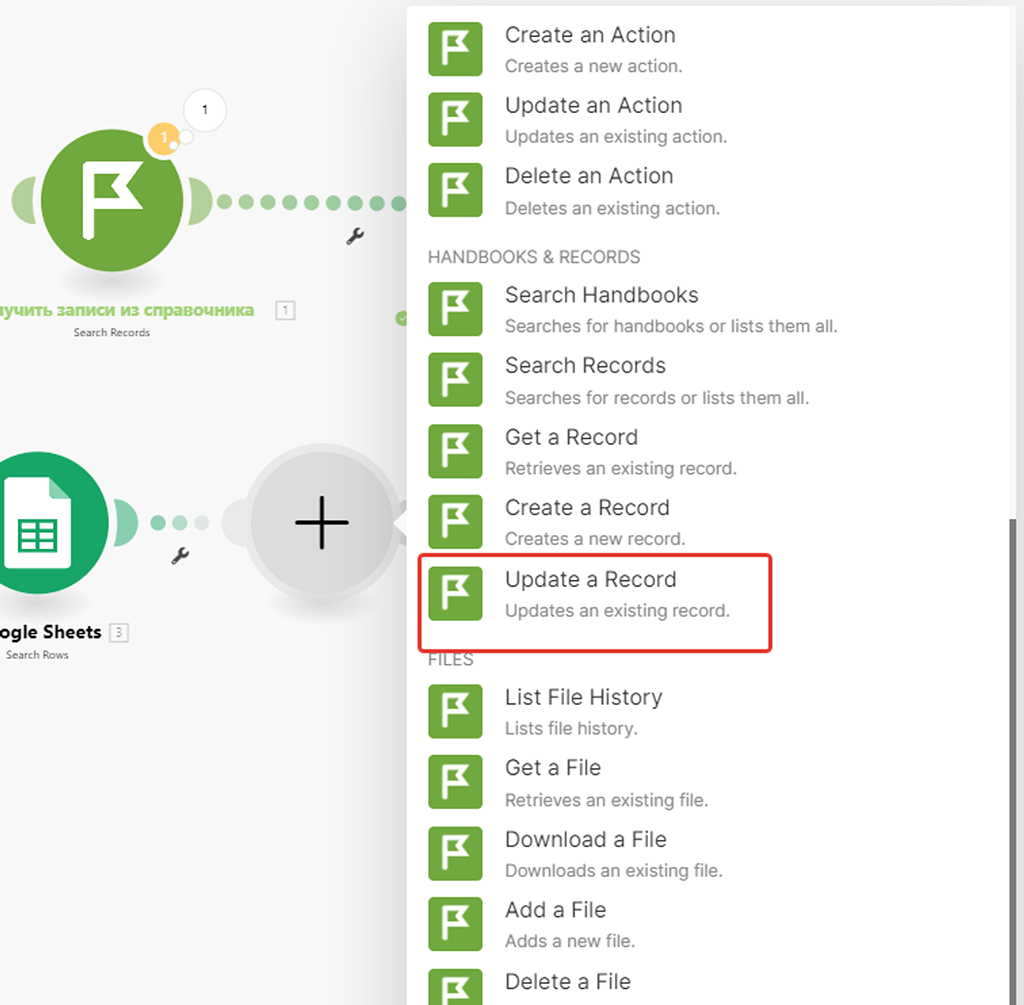
Настраиваем модуль.
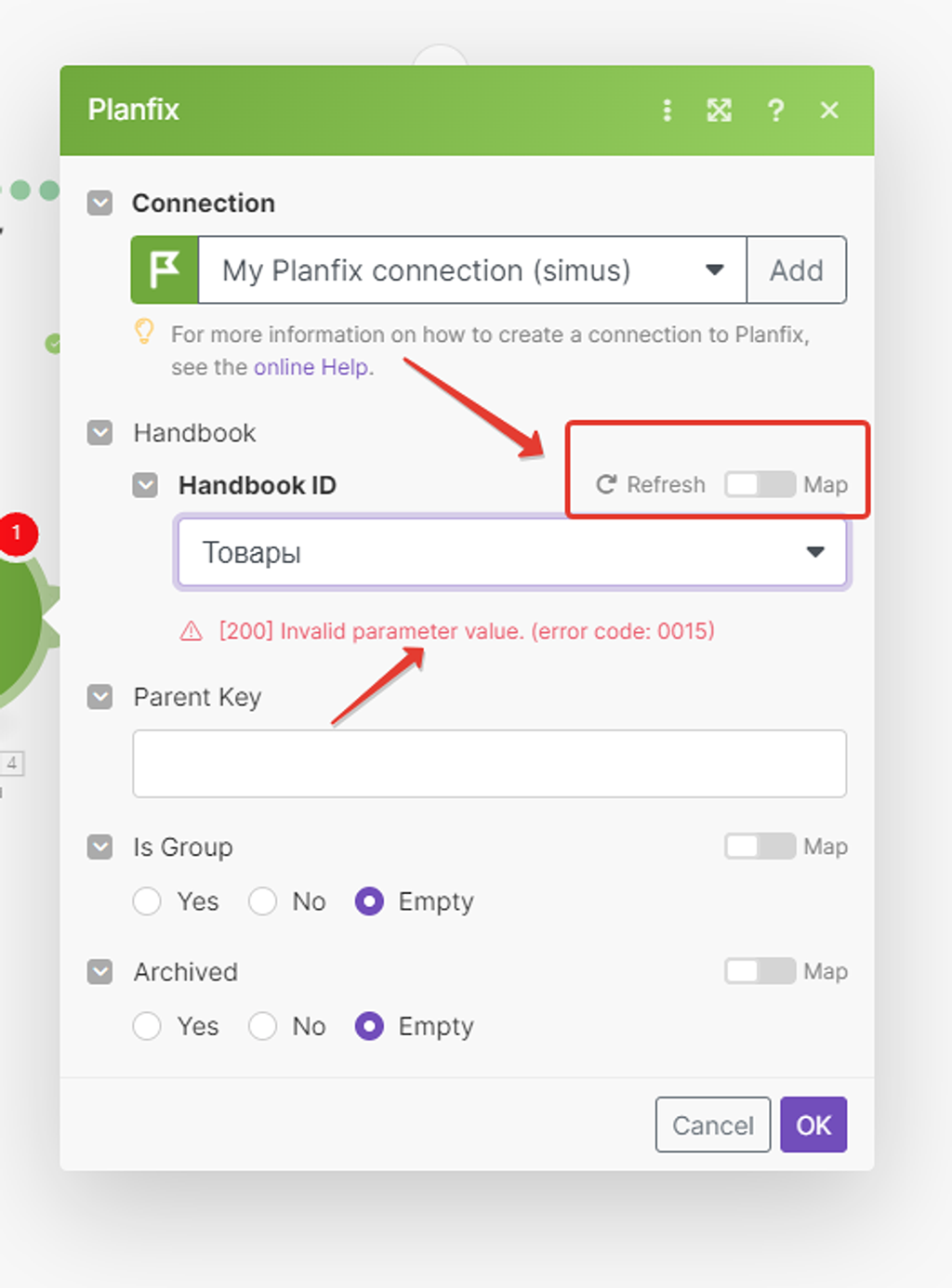
Обратите внимание:
- Чтобы «выбрать» нужный справочник из списка, надо выключить тумблер «map».
- Если у вас появляется красная надпись об ошибке, то просто закройте модуль через «ок» и откройте его заново (вот такая милая бага пока ещё есть):
Ок. Открываем снова модуль настроек, там теперь всё должно быть нормально и доступно для финальной настройки — нам надо указать откуда мы получаем ID записи (Record key), а откуда данные для обновления колонки «Остаток»:
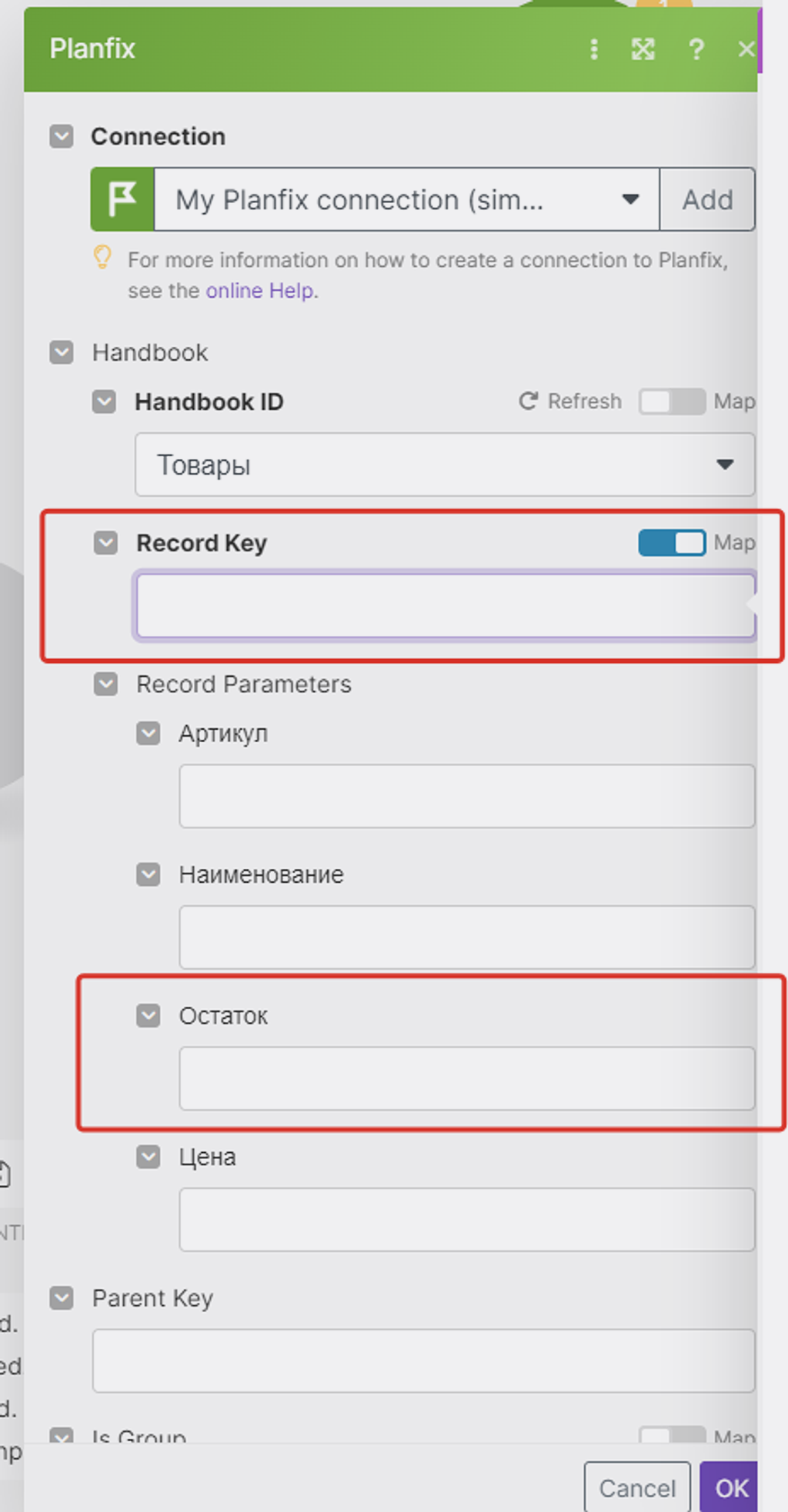
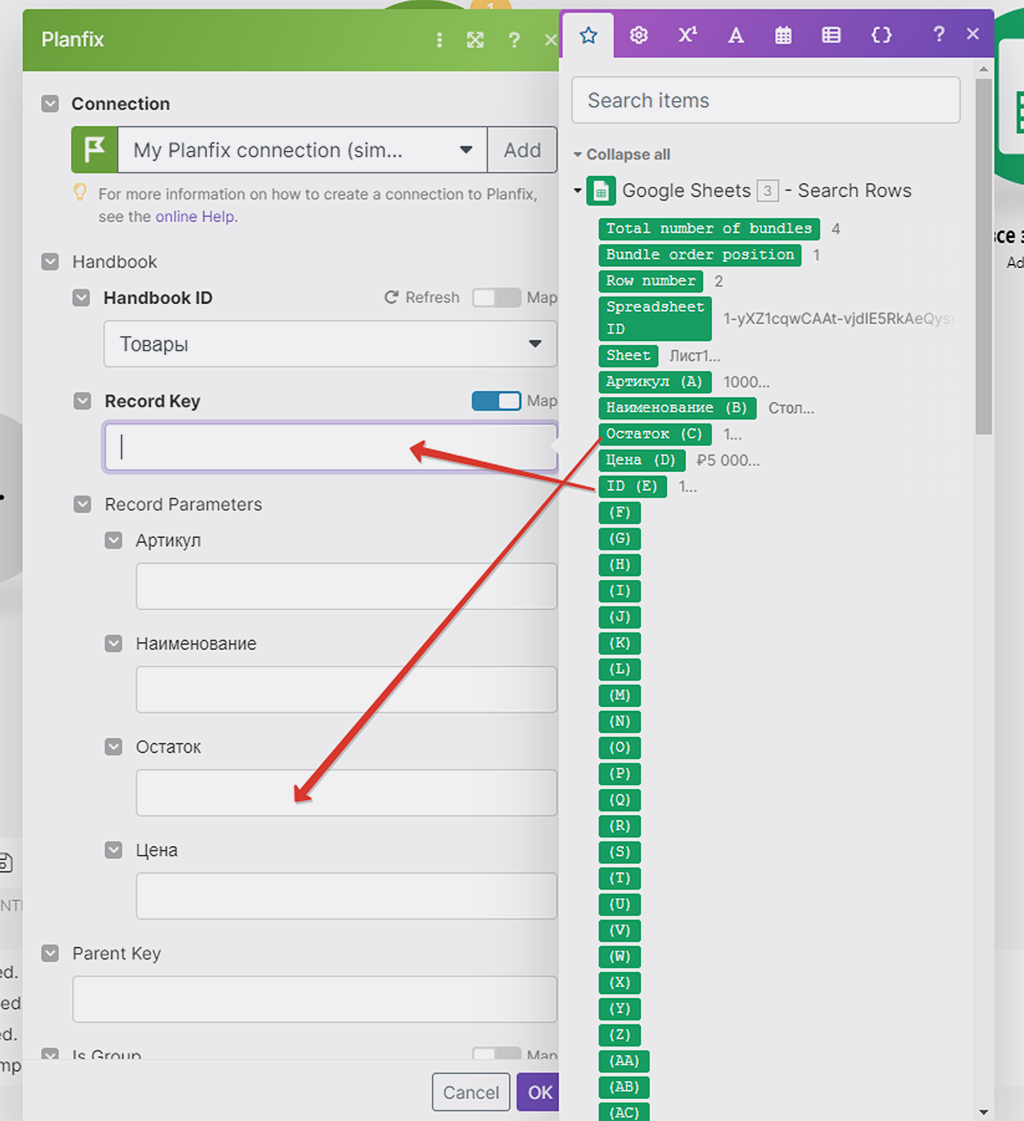
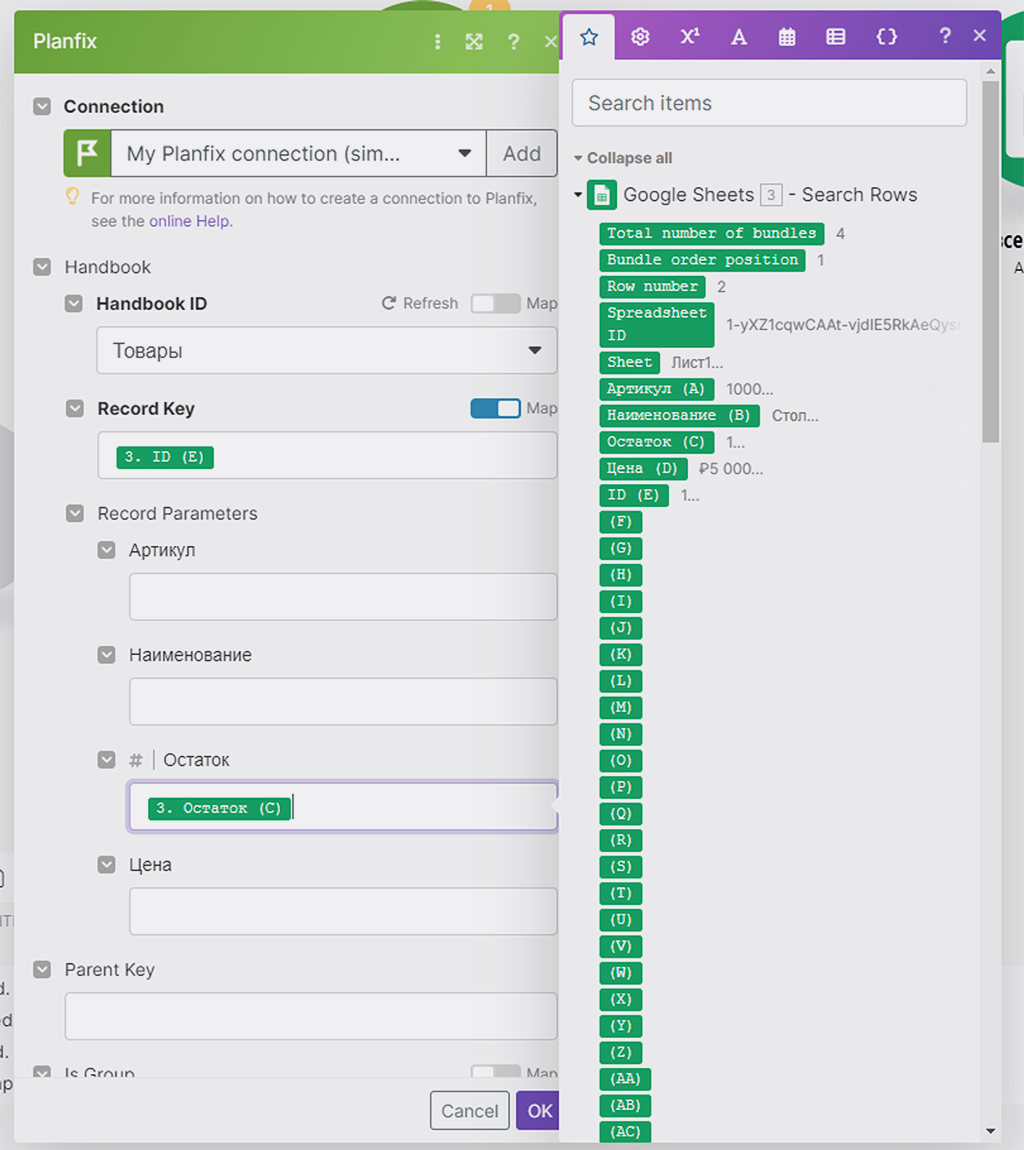
Тут всё по аналогии как было выше, только с модулем поиска записей Google всё проще и нагляднее:
Остальные настройки нам не важны. Нажимаем «Ок» — сценарий готов. Пора проверить его работу.
Запускаем сценарий и проверяем результат работы
Но прежде вспомним данные по остаткам в нашей Google Таблице:
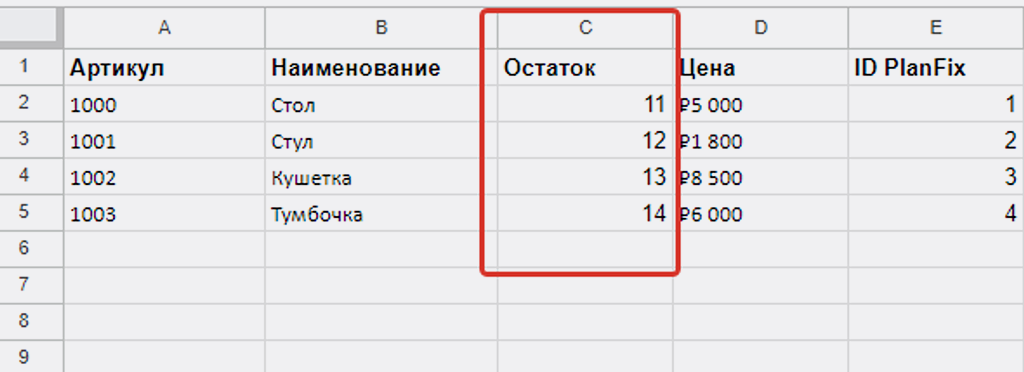
В справочнике «Товары» PlanFix пока так:
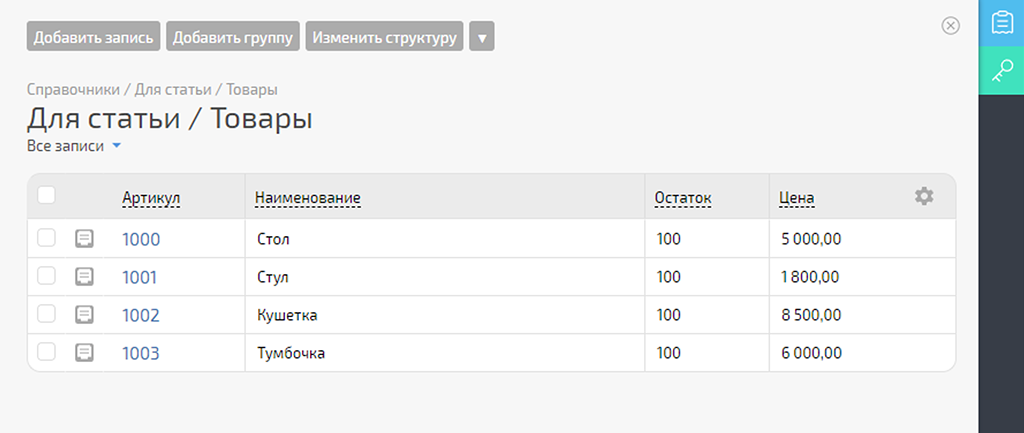
Запускаем сценарий и проверяем результат его работы:

Всё ок. Сценарий работает корректно.
Сценарий обновления данных — вариант 2
В общем, этот сценарий, конечно, проще, так как не требует первоначального импорта данных из справочника PlanFix в Google Таблицу, так как ID записи нам не нужен. Также избавляет нас и от добавления ID в Google Таблицу по новым записям товаров. Но при больших объёмах данных может выйти существенно дороже, так как тратит больше количество операций в Make.
В этом сценарии у нас будет три модуля:
- Модуль (1) — получение записей из справочника PlanFix.
- Модуль (2) — поиск соответствующих записей в Google Таблице по артикулу.
- Модуль (3) — обновление найденной записи в справочнике PlanFix по полученным новым данным из Google Таблицы из соответствующей найденной записи:

Шаг 1 — Настраиваем модуль (1) получения записей из справочника PlanFix
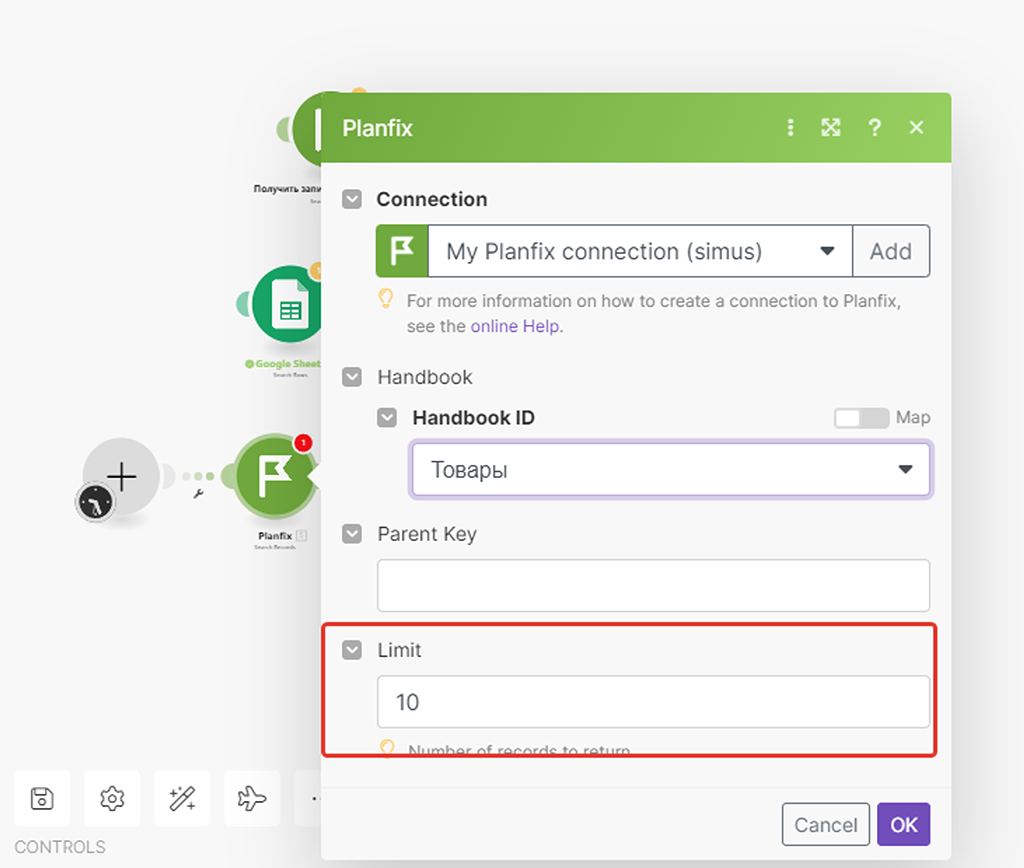
Всё уже очевидно и просто, надо лишь выбрать наш справочник из списка доступных справочников. А вот с лимитом записей мы разберёмся чуть позже — в вариации этого сценария. Пока всё ок.
Шаг 2 — Настраиваем модуль (2) поиска записи в Google Таблице по артикулу
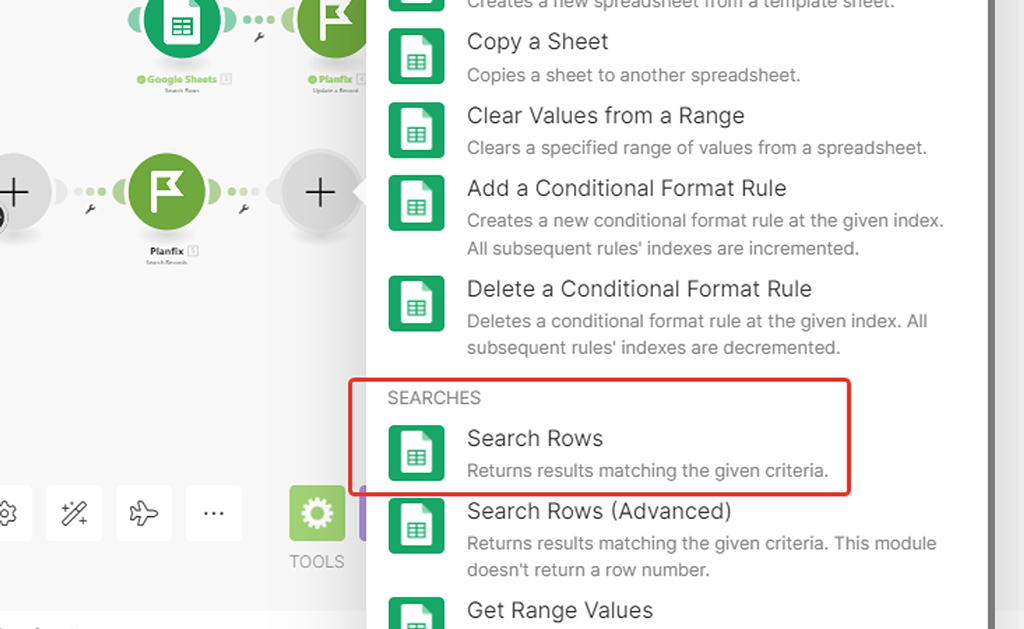
В верхней части настроек всё стандартно, а вот с блоком поиска (фильтрации) разберёмся чуть подробнее:
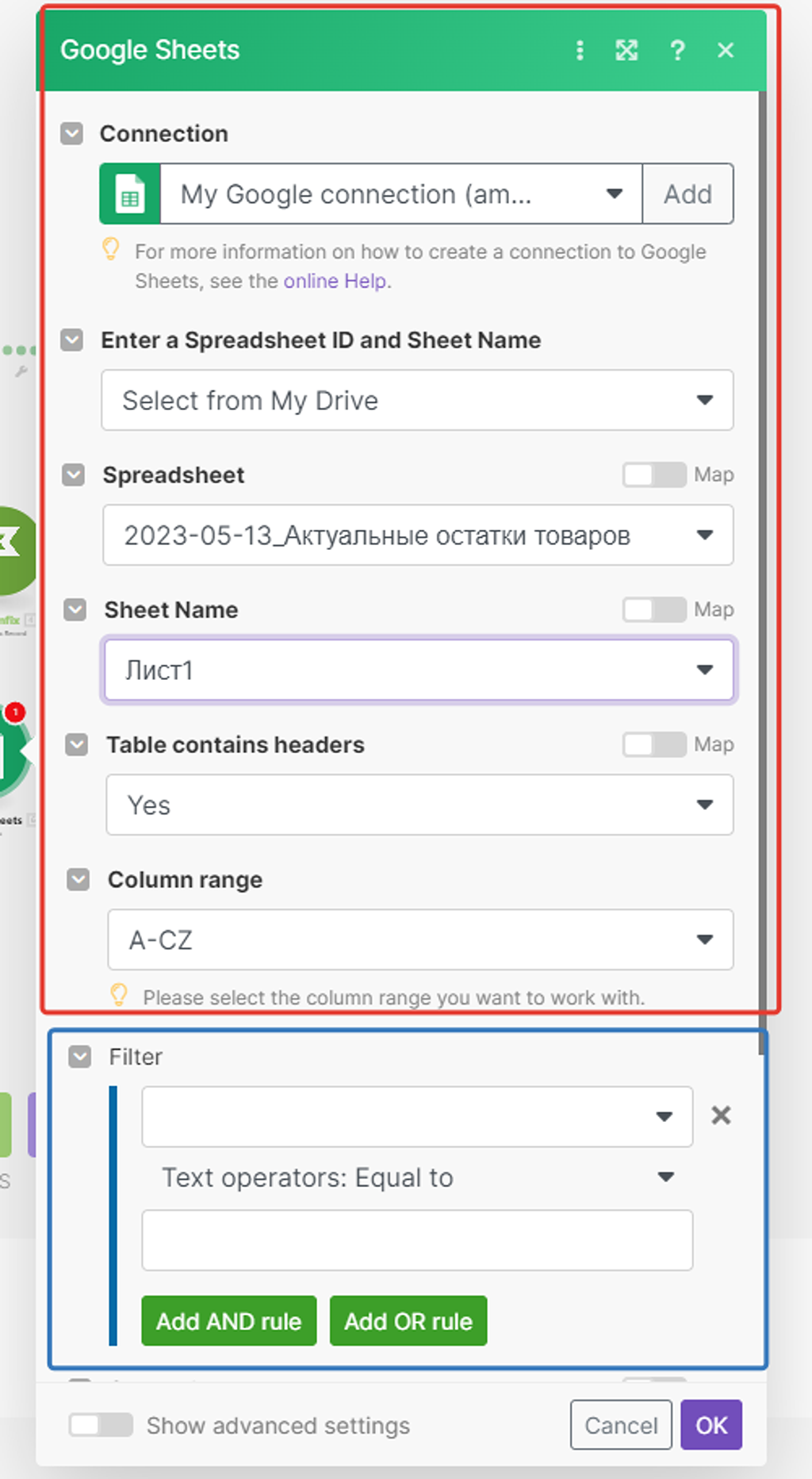
Мы будем искать записи, у которых в колонке «Артикул» такое же значение, как и у полученной записи из справочника PlanFix — это одно из значений подмассива полученных данных модулем (1) «Custom Data»:
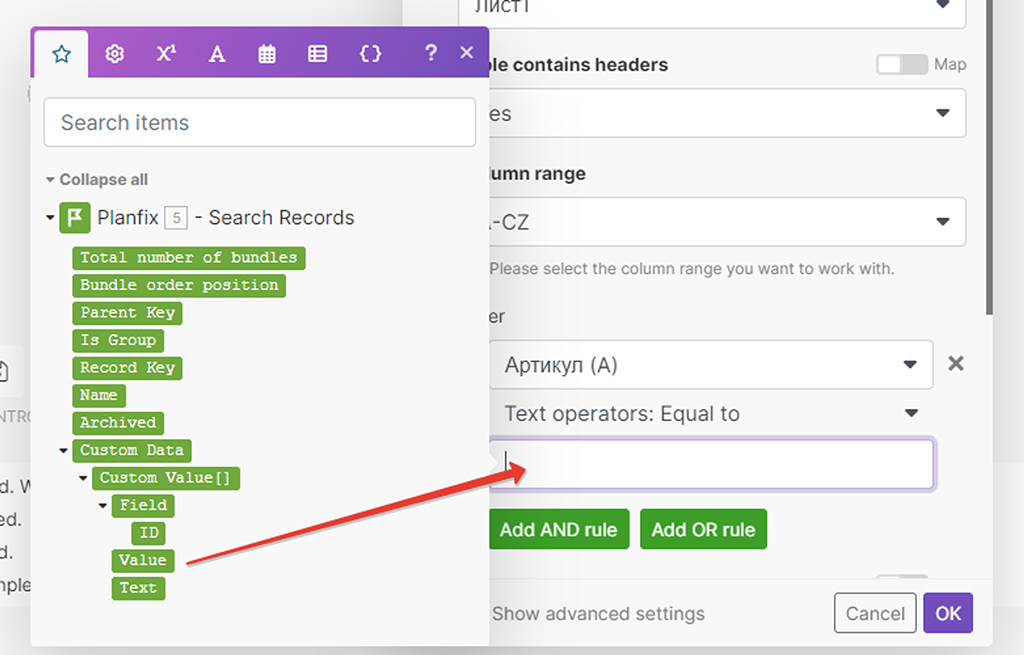
Мы ранее выше разбирали структуру подмассива данных модуля (1) для получения записей справочника и выяснили, что Артикул имеет номер свитка «1» — его мы и укажем:
На этом все необходимые настройки модуля завершены.
Шаг 3 — Настраиваем модуль (3) обновления записи справочника PlanFix

Как мы помним, модуль немножко «глючит» и после деактивации тумблера «map», он пишет ошибку. Но мы выбираем наш справочник «Товары» и просто закрываем модуль через «ок», а потом открываем вновь и продолжаем его настройку.
Здесь уже Record key мы берём не из Google Таблицы (в этом варианте у нас его просто нет), а из данных первого модуля (прокручиваем список выбора получения данных):
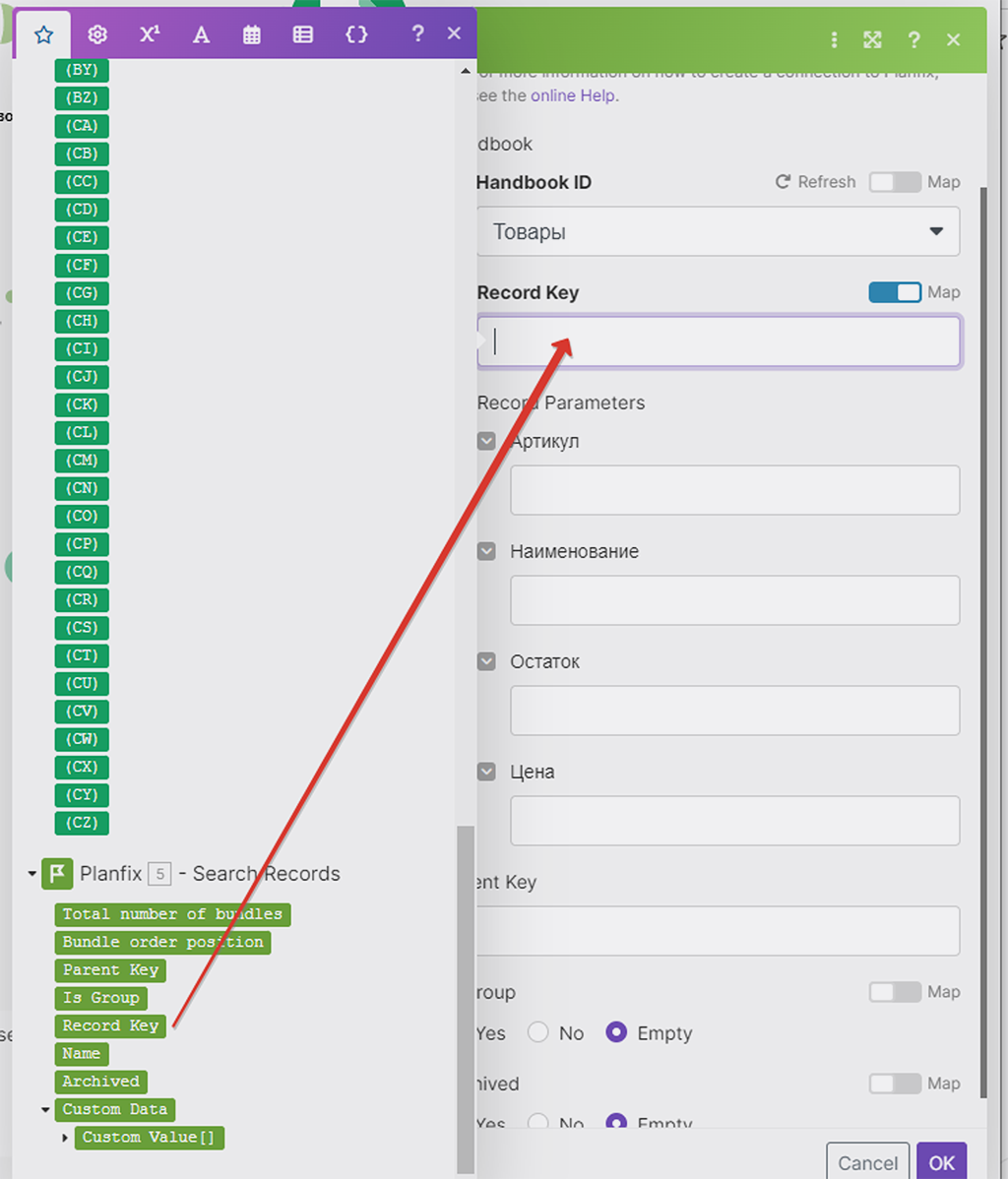
А вот нужные нам данные по Остатку берём как раз из Google Таблицы:
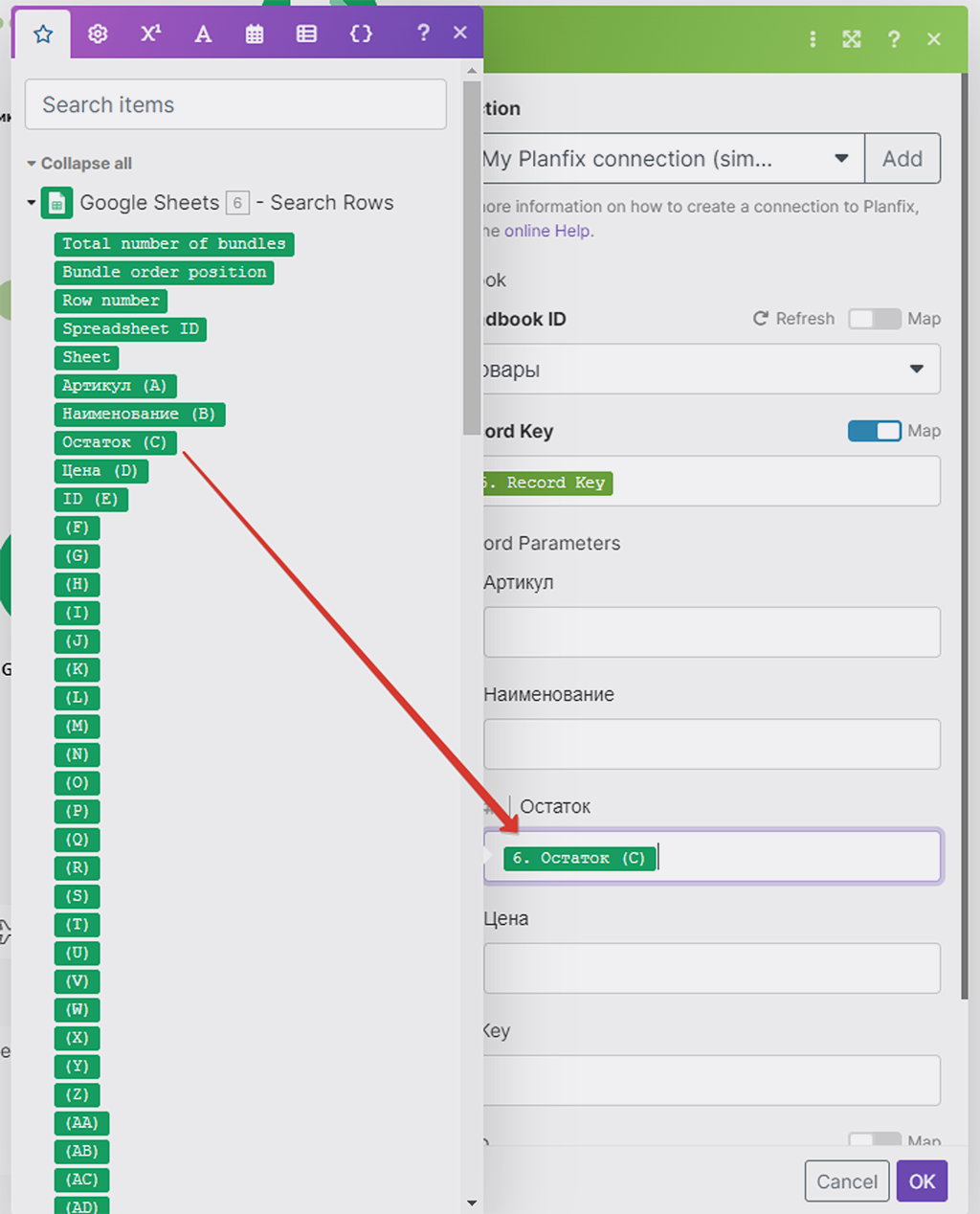
Ок. Модуль настроен. Можно запускать его в работу.
Проверка работы сценария обновления данных
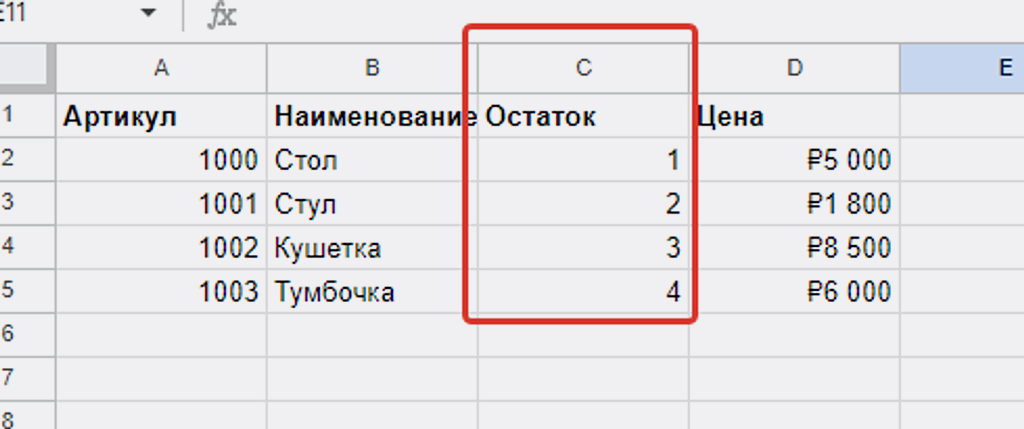
Но прежде снова заменим данные по остаткам в нашей Google Таблице, чтобы увидеть результат работы сценария.
Было так:
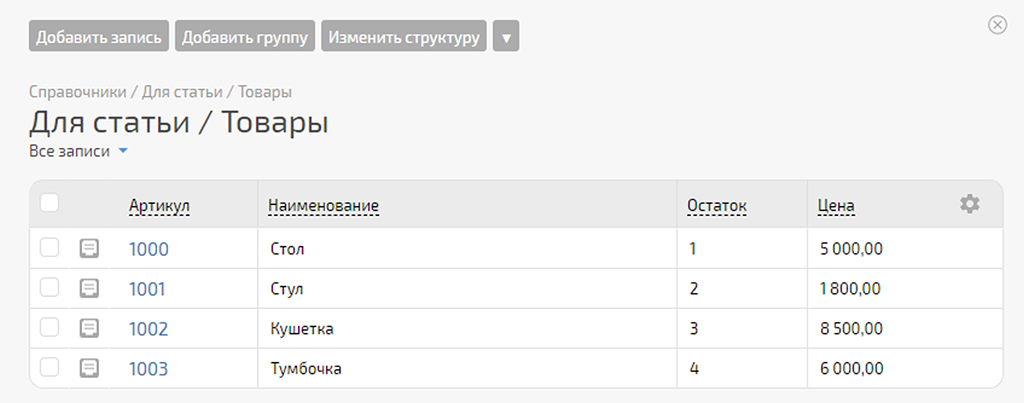
Так же сейчас в справочнике PlanFix:
Указал в Google Таблице новые данные по остаткам:
Запустили сценарий:
Работает корректно:
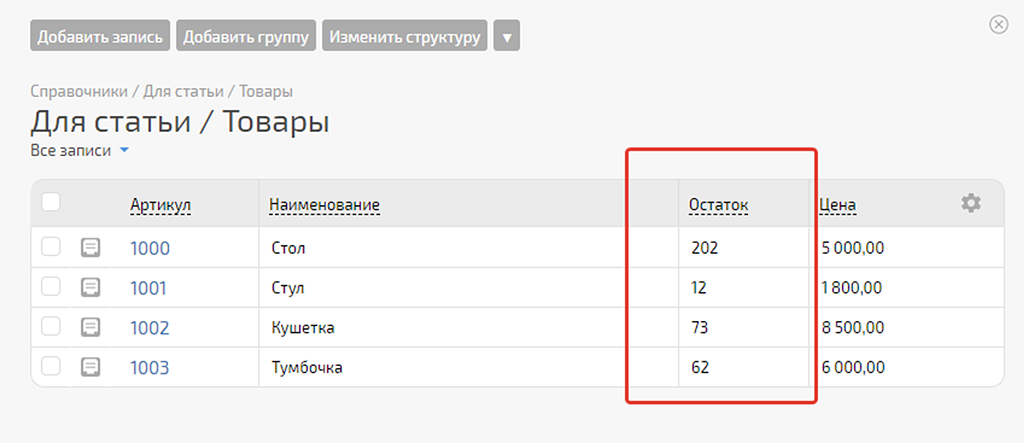
Далее рассмотрим вариант этого сценария, когда кол-во записей в справочнике товаров у нас более 100 (это максимальный объём вывода данных из справочника PlanFix в Make за один запуск сценария).
Сценарий обновления данных — вариант 2, большое кол-во записей (более 100)
Корректирую исходные данные
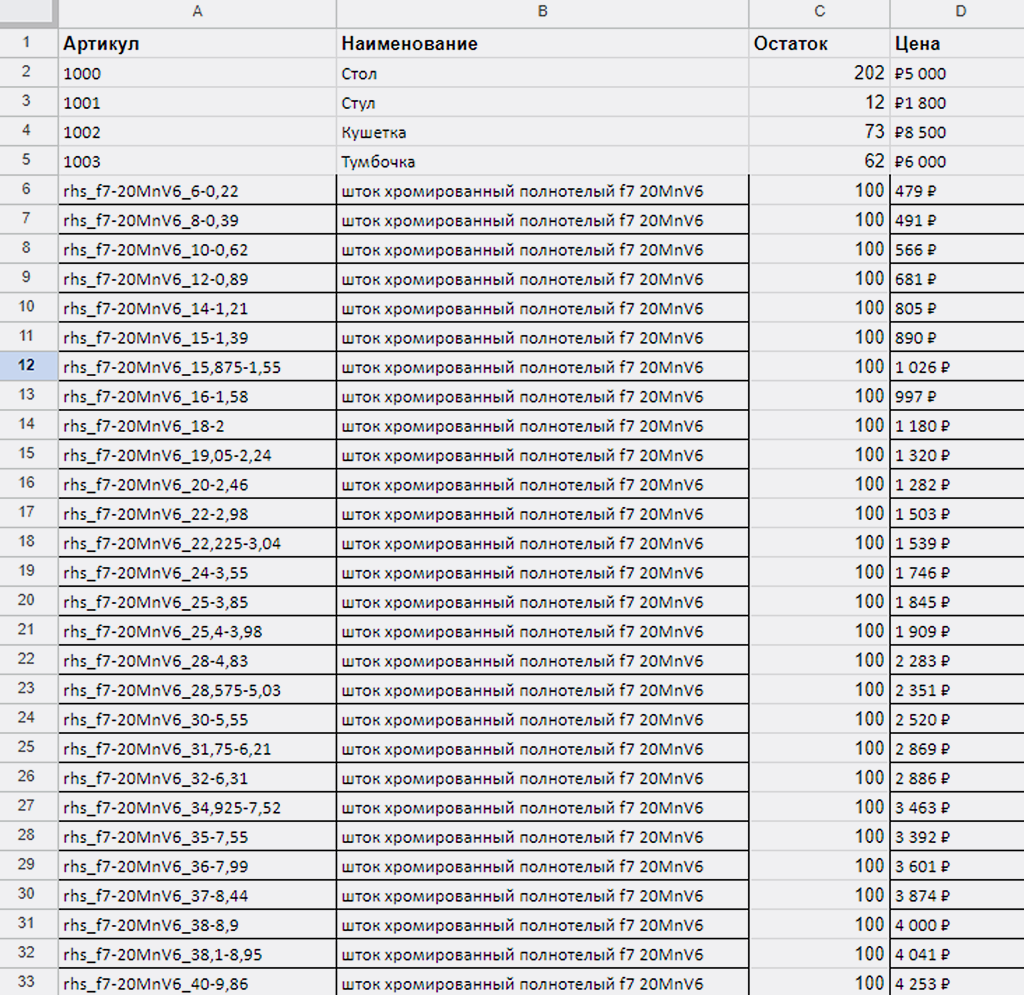
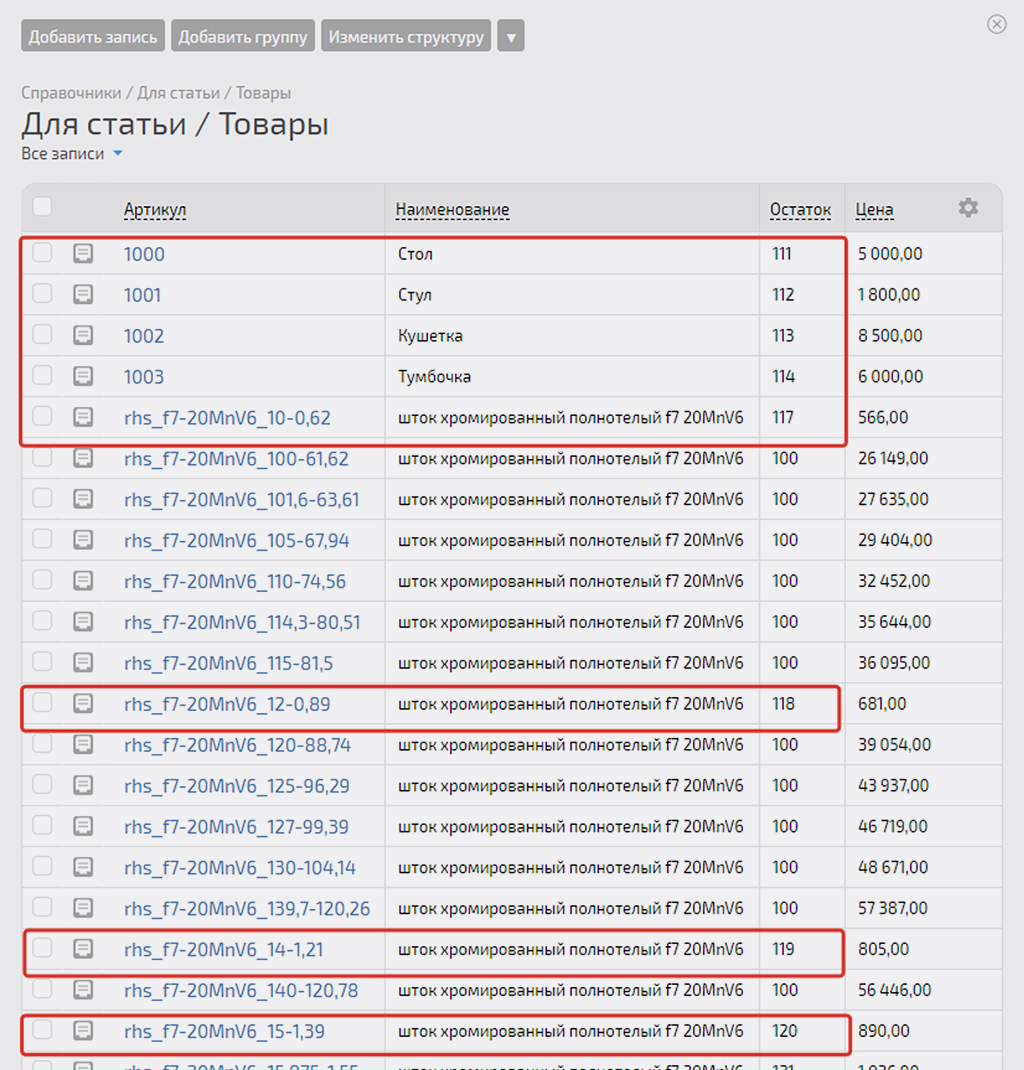
Для проверки работы сценария на большем количестве записей в справочнике, в нашу Google Таблицу загрузил список номенклатуры состоящий из 380 записей, вместе с прежними 4 стало 384 — вполне достаточно для проверки:
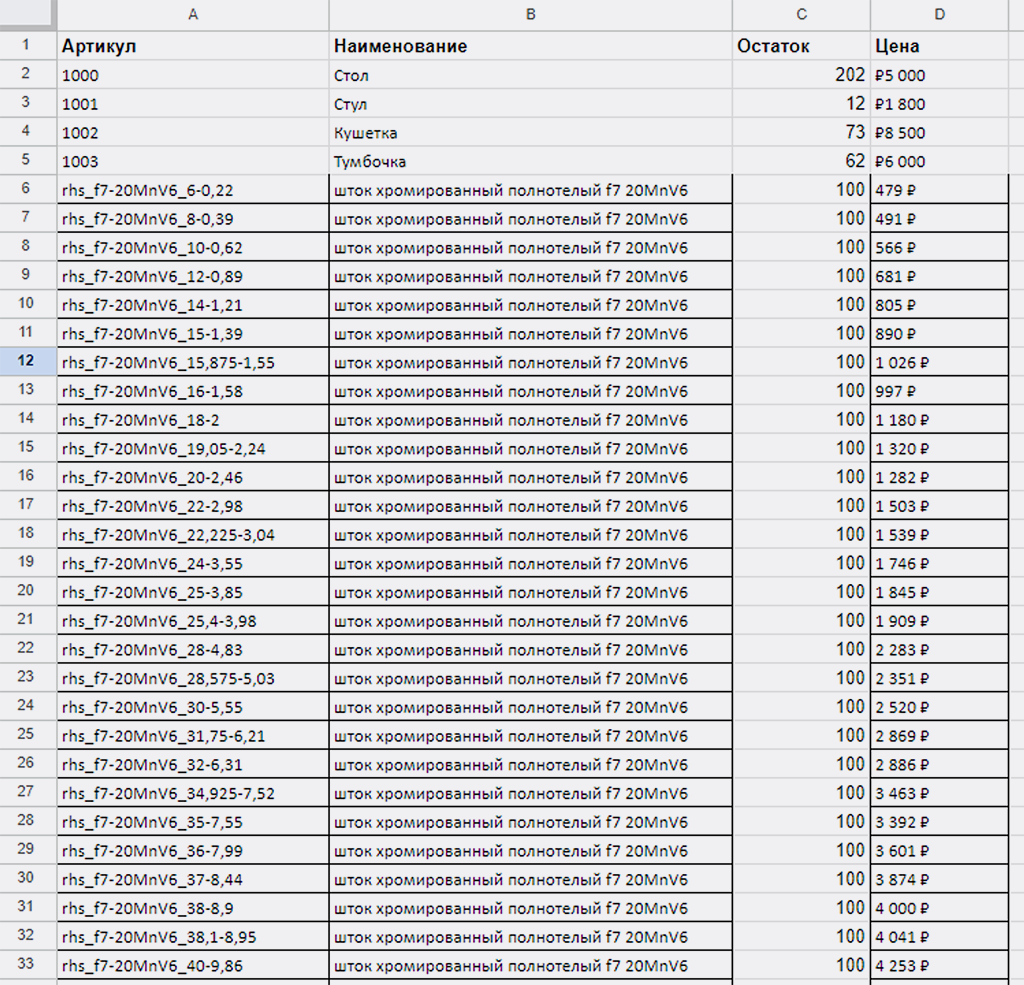
Прежде импортирую эти же данные в наш справочник «Товары» в PlanFix (у всех новых товаров остаток 100). Старые не буду удалять, чтобы убедиться, что к ним никакие новые данные «не прилипают» случайно):
Ограничение модуля PlanFix
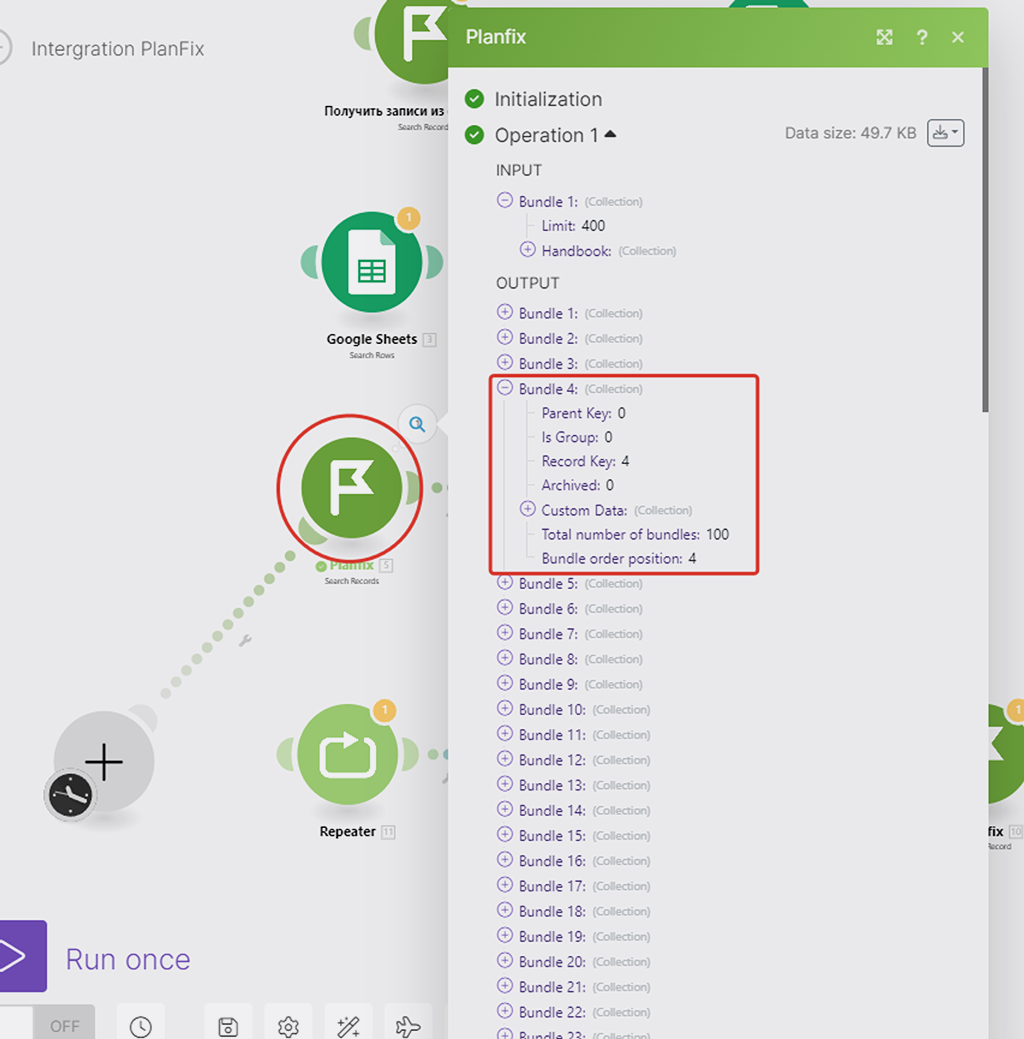
Посмотрим, какой объём данных максимально может получить первый модуль — для этого запустим лишь его, но в настройках лимита укажу значение 400, допустим:
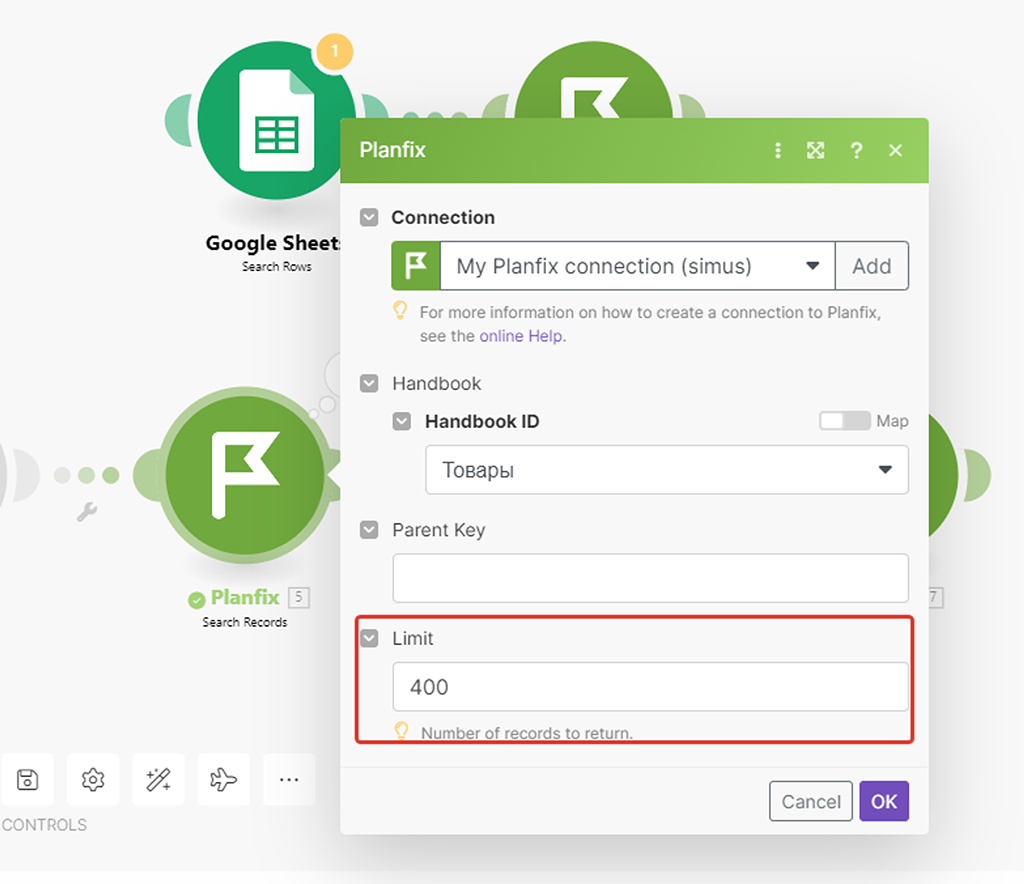
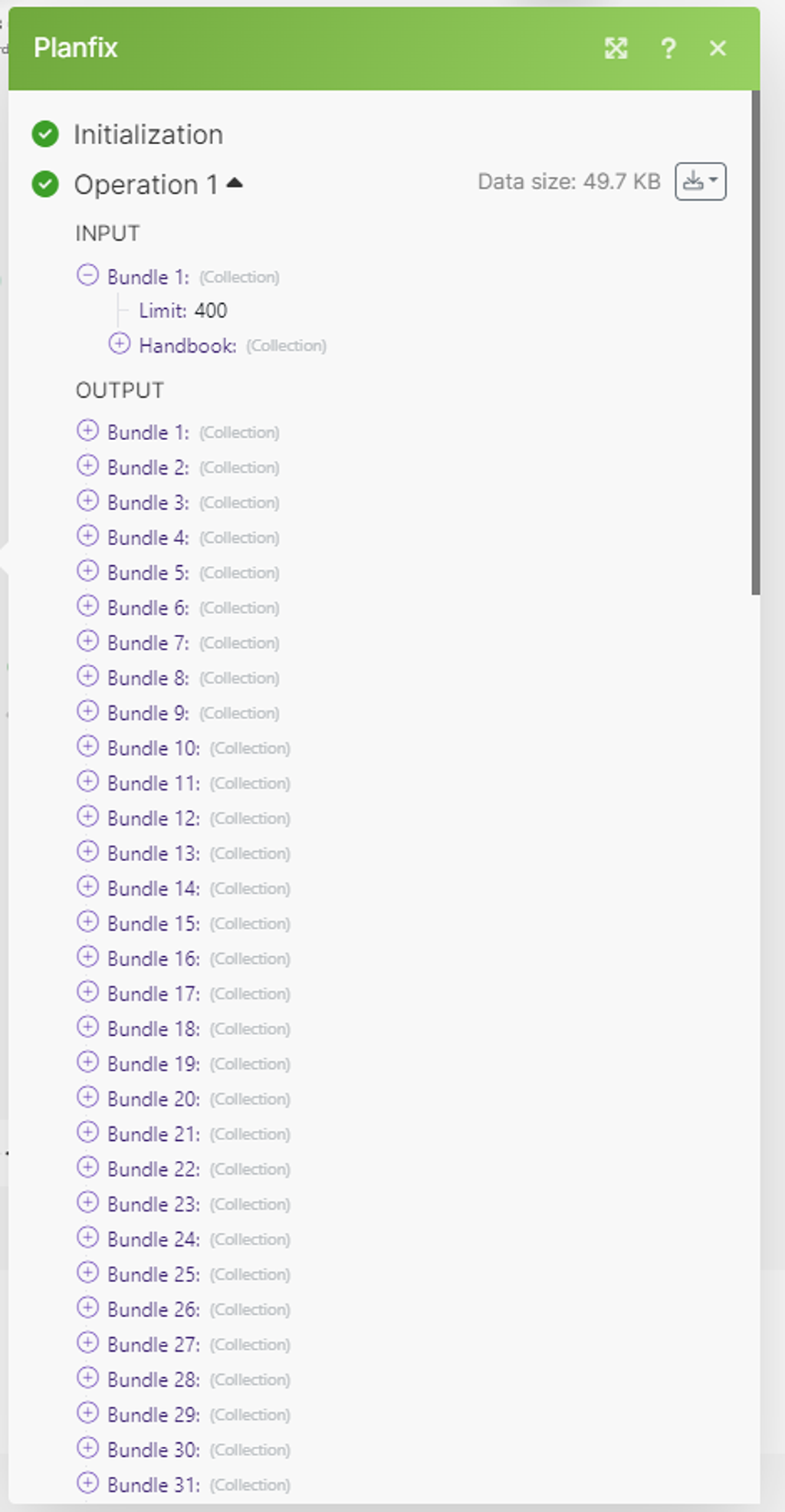
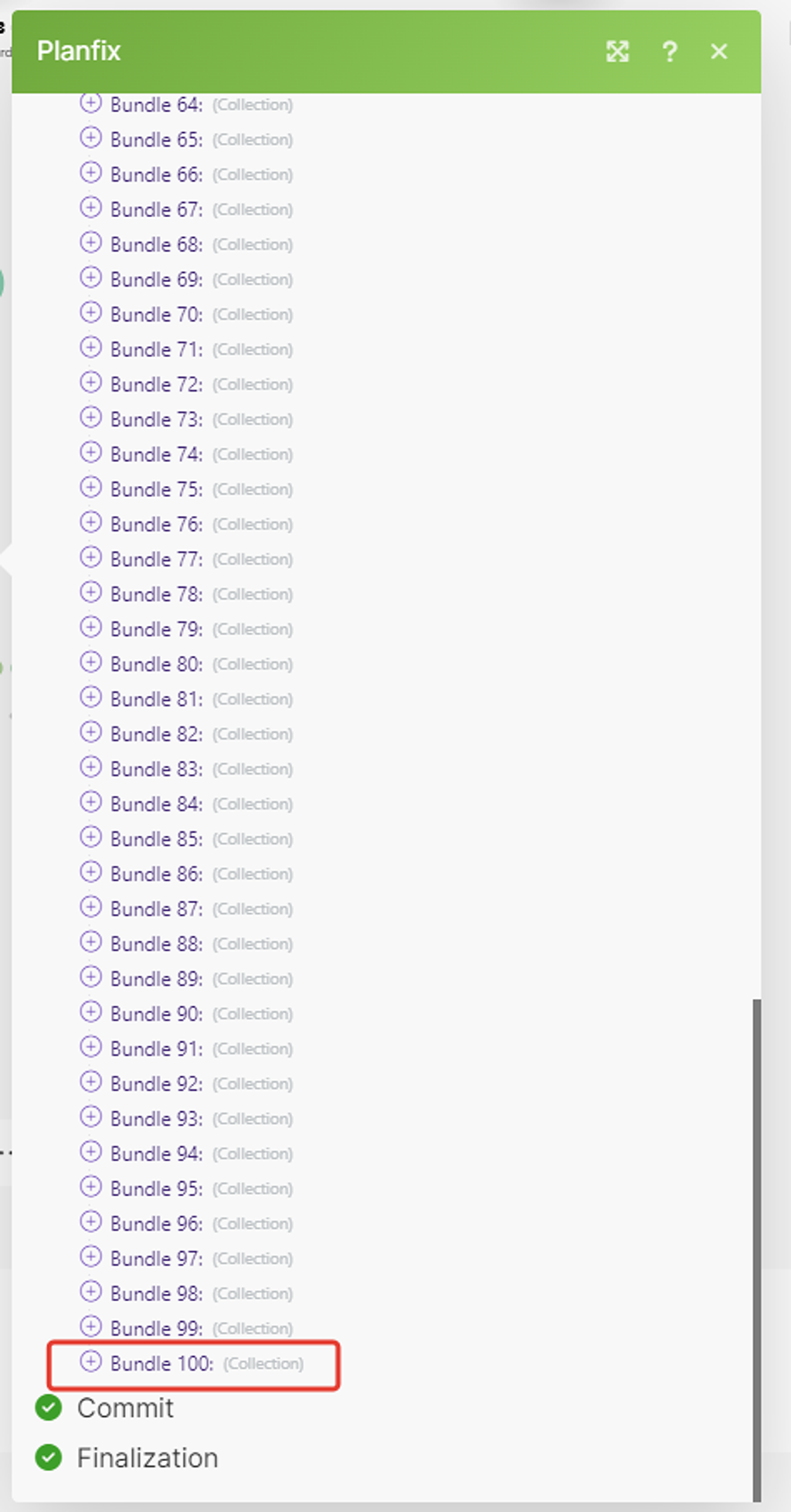
Максимальное количество выгружаемых данных 100 записей — таково ограничение по отдаче данных на стороне сервиса PlanFix, да и у многих иных БД других систем.
Как быть?
Общий алгоритм решения
Алгоритм решения есть и он следующий:
- Добавляем модуль (4), который запускает наш сценарий столько раз, сколько нам нужно.
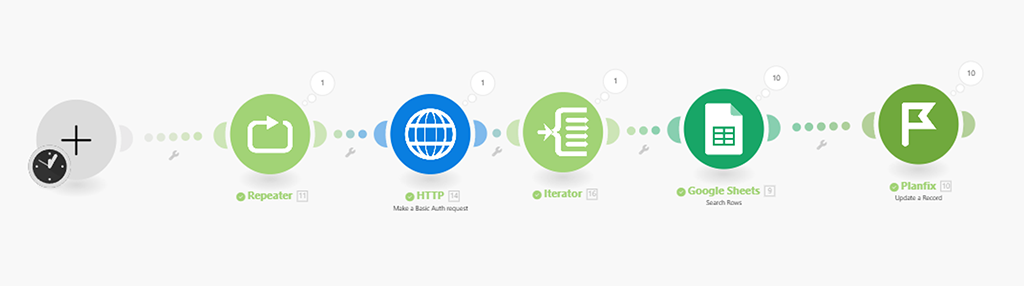
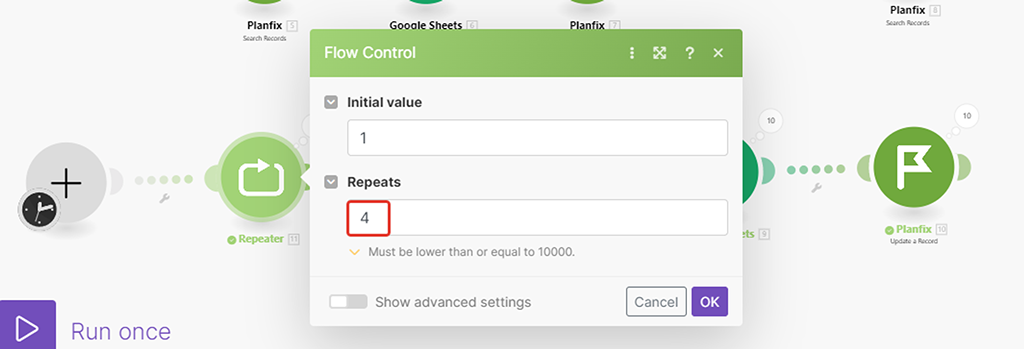
- В первом модуле настраиваем, какую сотню он будет загружать — первую (от 1 до 100), вторую (от 101 до 200) и так далее. Нам нужно 4 запуска, чтобы все наши 384 записи в итоге прогрузились.
Шаг 1 — Добавляем модуль (4) запуска сценария несколько раз
Этот модуль добавляем перед нашим первым модулем предыдущего сценария:
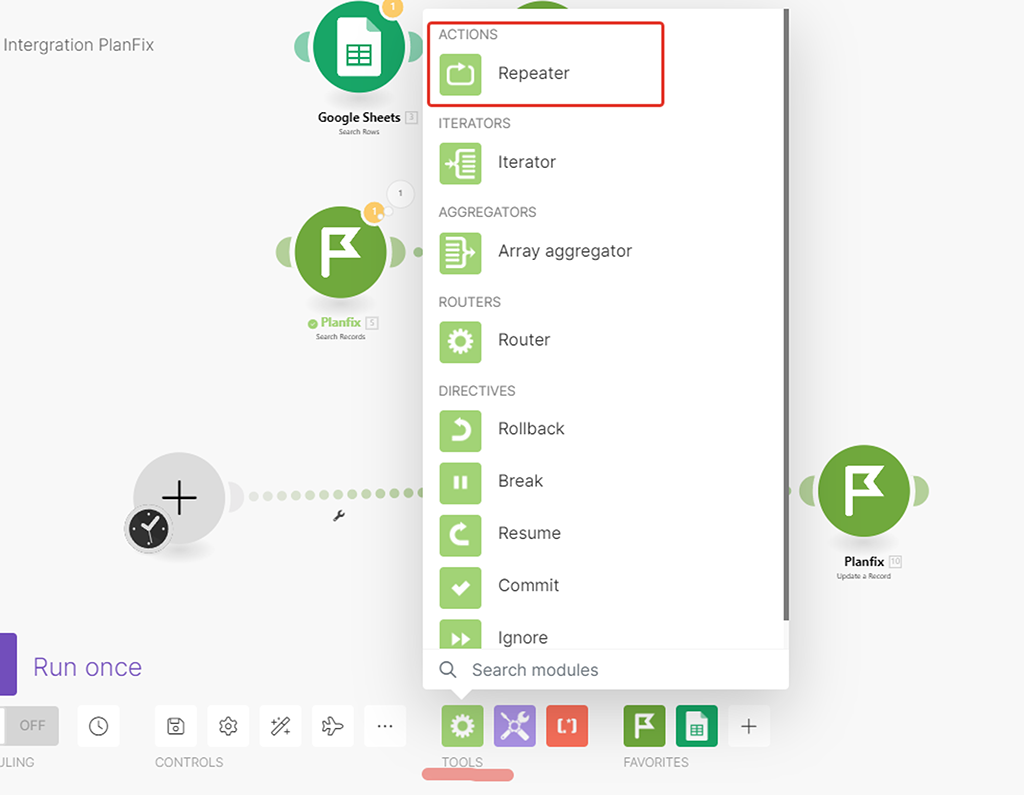
В инструментарии Make есть штатный модуль «Репитер» его и добавляем перетаскиванием в нужное место:
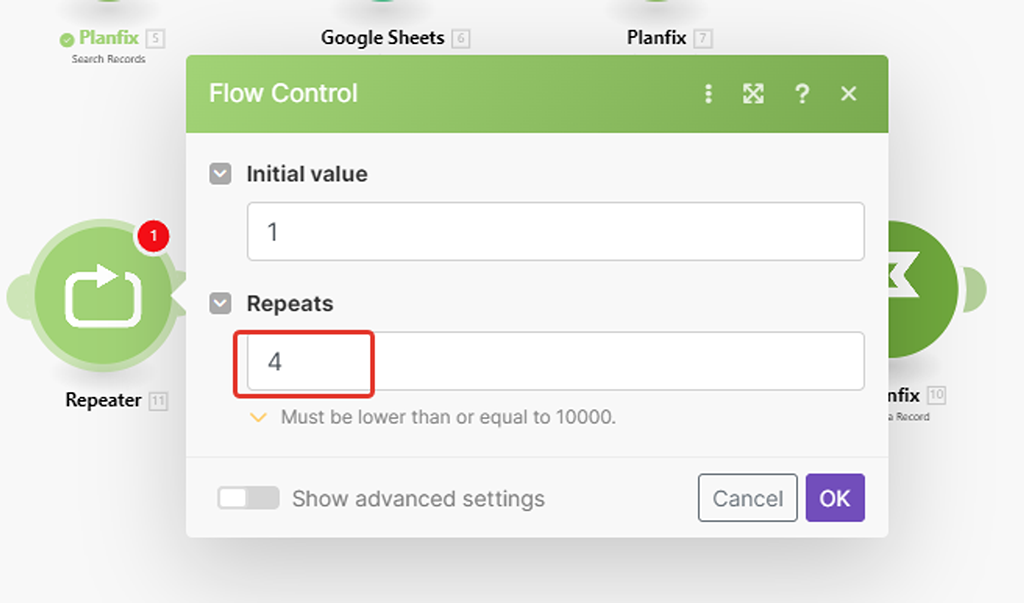
Настраиваем новый модуль.
Нам надо, чтобы модуль перезапустил сценарий 4 раза (на 384 записи по 100 за раз) и начал с 1-го раза:
Шаг 2 — Замена модуля (1) от PlanFix на модуль (5) HTTP API запроса
А) Ещё одна недостаточность модуля от PlanFix
Открываем настройки следующего модуля (1) «Получения записей из справочника PlanFix»:
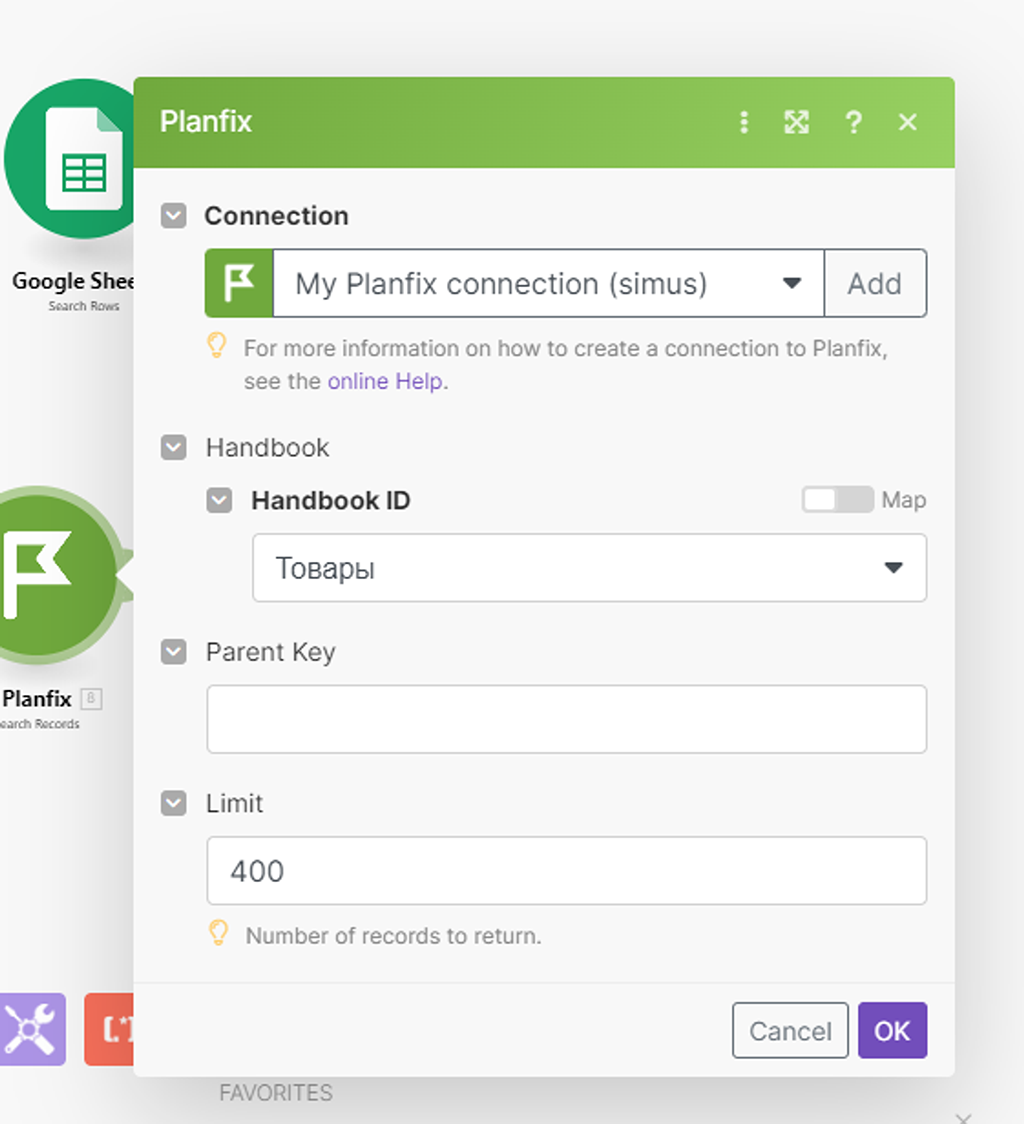
— а настроек какую сотню данных нам загружать здесь то и нет.
Надеюсь, что PlanFix со временем допилит этот блок интеграции, а сейчас нам поможет эту задачу решить модуль (5) формирования API запросов Make и справочник синтаксиса API XML запросов PlanFix, так как нужным нам API запрос там описан, что круто, конечно.
Б) Ищем описание нужного синтаксиса API запроса в справочнике PlanFix
В поиске PlanFix набираем API и видим в результатах поиска ссылку на нужный нам справочник:
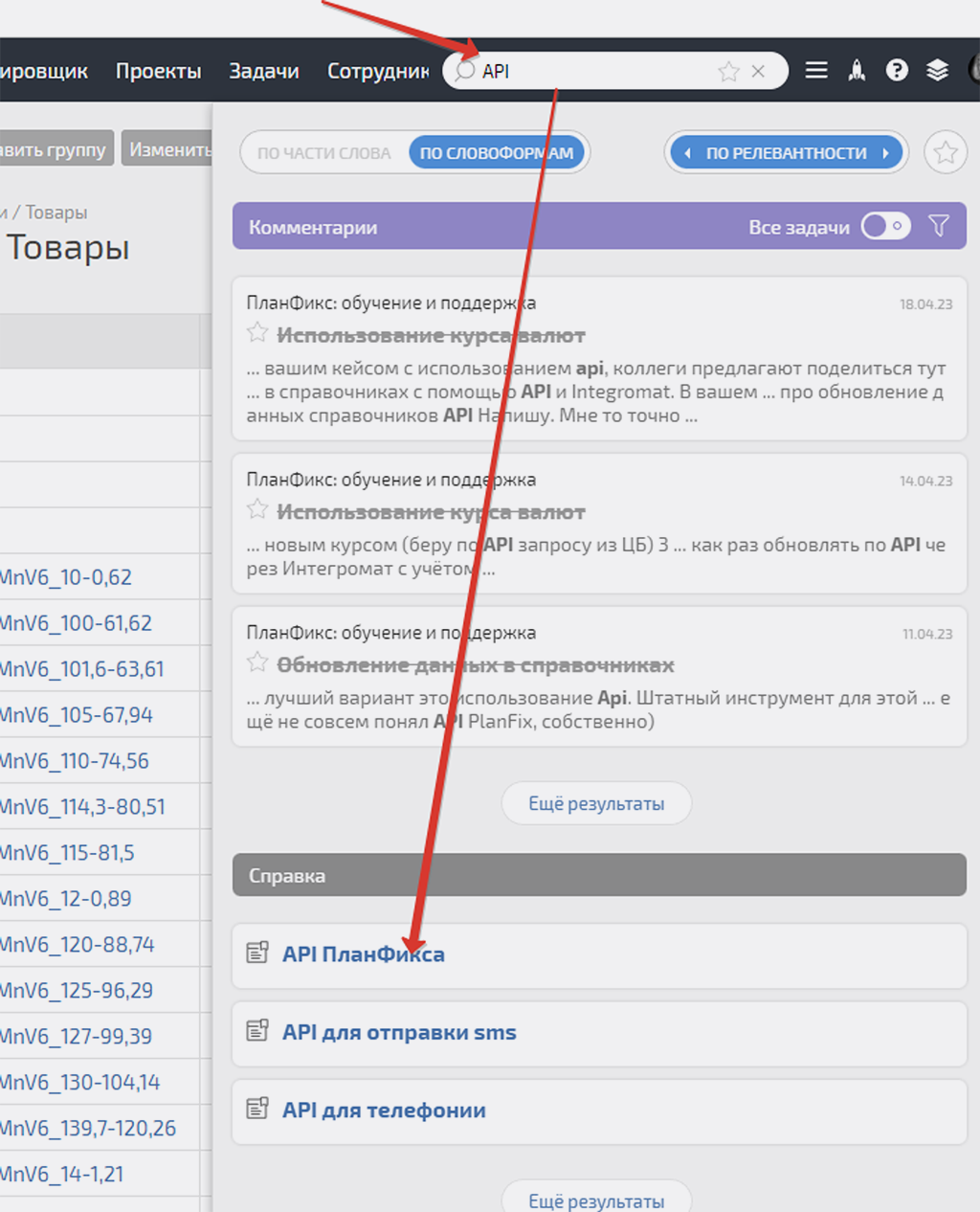
Нас интересует XML API v1:
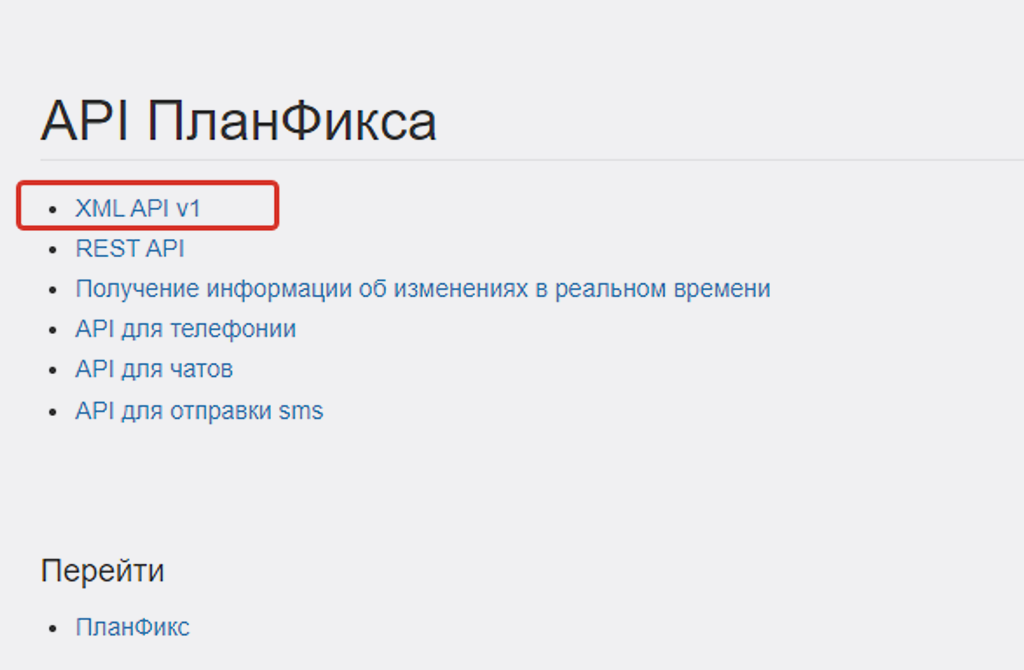
Ссылка на API.
Прокручиваем текст статьи вниз и там находим ссылку «Список функций»:
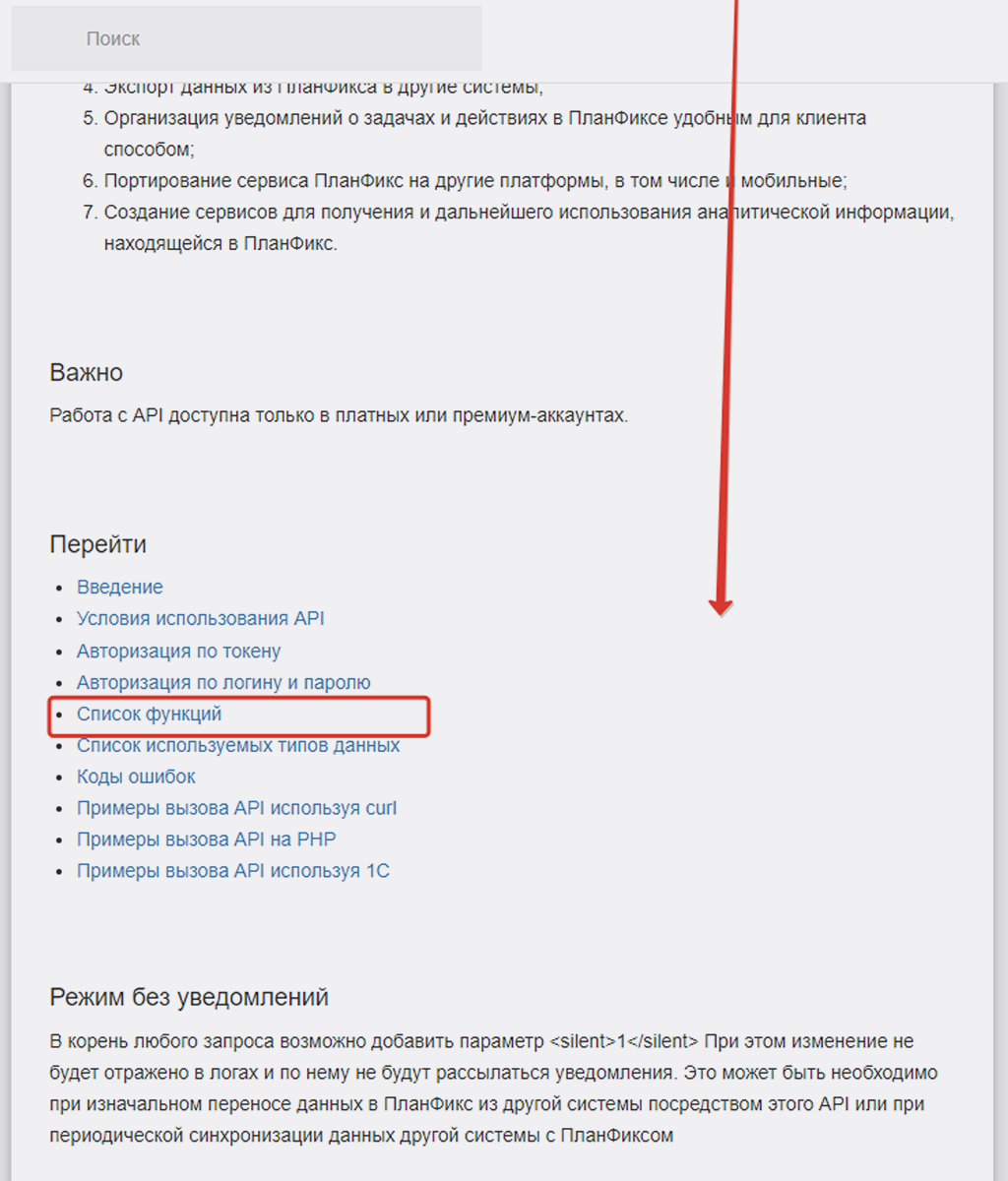
Ссылка на список функций.
В открывшемся перечне находим пункт «Справочники» — он то нам и нужен, как источник знаний:
Здесь нас интересует синтаксис API для получения всех записей справочника:
Ссылка на инструкцию по нужному нам API запросу
Все необходимые нам данные здесь, не все они потребуются для Make, но об этом чуть позже:
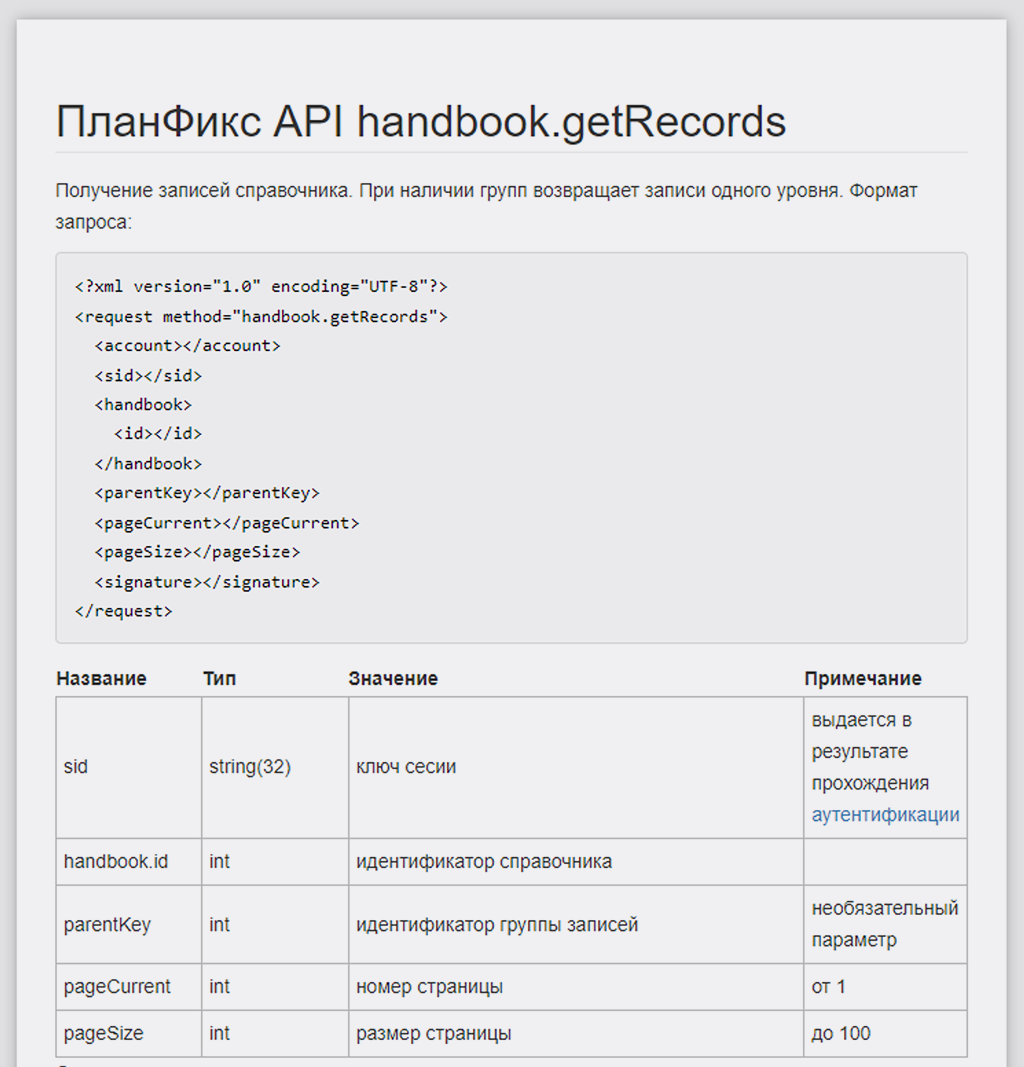
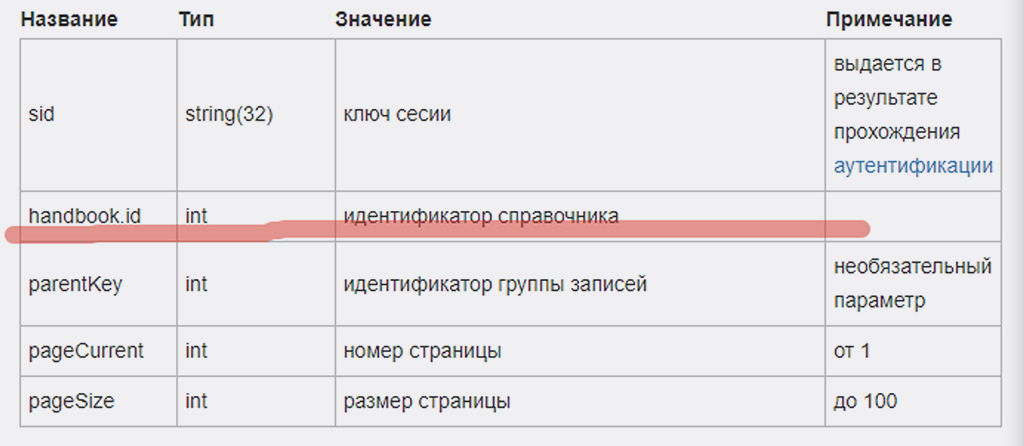
В таблице значений мы видим, что для формирования API запроса в Make нам надо знать ID нужного справочника (это такой же уникальный идентификатор, как и id записи):
Вопрос: как его получить?
Для этого нам надо сделать другой API запрос из Make, который покажет нам все справочники в нашей системе и их ID — такой запрос, благо, есть.
Но есть лайфхак! Не будем изучать так подробно синтаксис API запросов PlanFix — для этого нужна отдельная статья и отдельный кейс, а этот и так уже перегружен нюансами. Воспользуемся лайфхаком)
Вернёмся в Make и откроем модуль (1) получения записей из справочника, который пока не умеет получать нужные нам сотни:
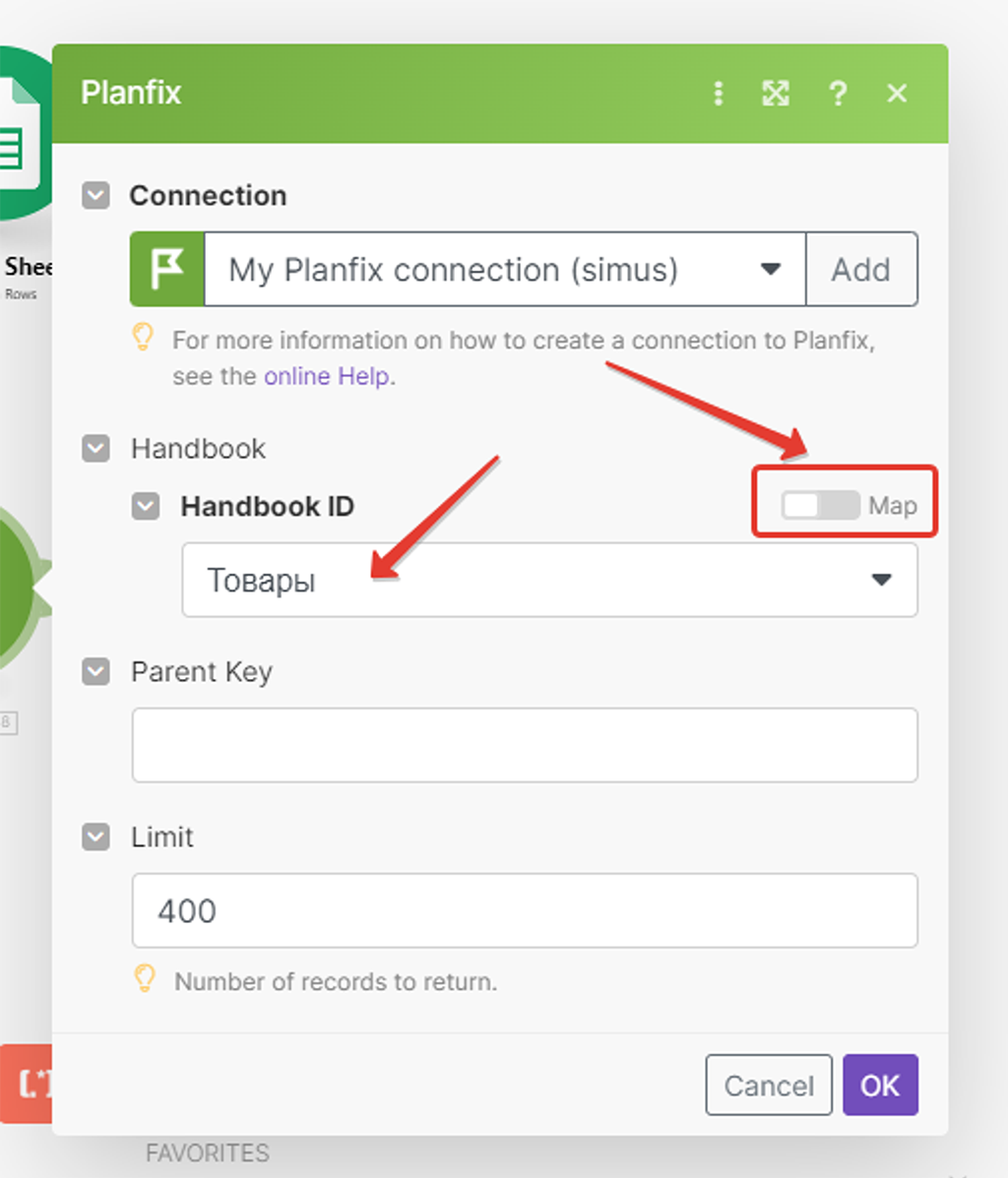
Если мы сейчас включим тумблер «map», то в поле выбора справочника вместо названия отобразиться его ID:
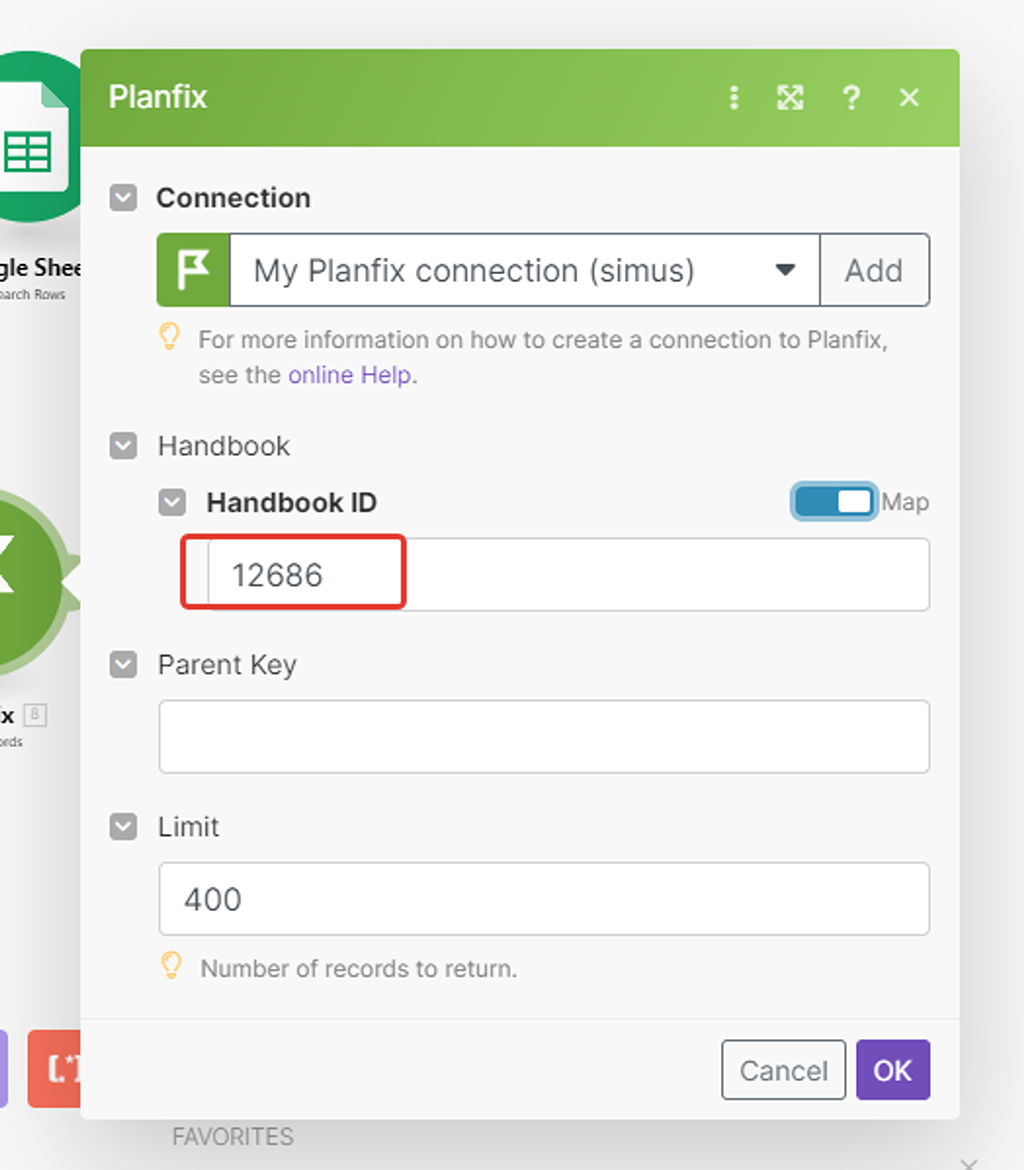
Отлично! 12686 — запомним его.
А из настроек модуля выйдем без сохранения через Cancel. Нужная информация у нас теперь есть.
Теперь надо создать необходимый новый модуль (5) нужного нам API запроса штатными средства Make, вместо уже существующего, но пока ещё не совершенного готового модуля (1) интеграции PlanFix (но и правда, что он совсем свежий и на момент написания статьи даже ещё не анонсировался).
В) Настраиваем модуль (5) HTTP API запрос на получение записей справочника PlanFix
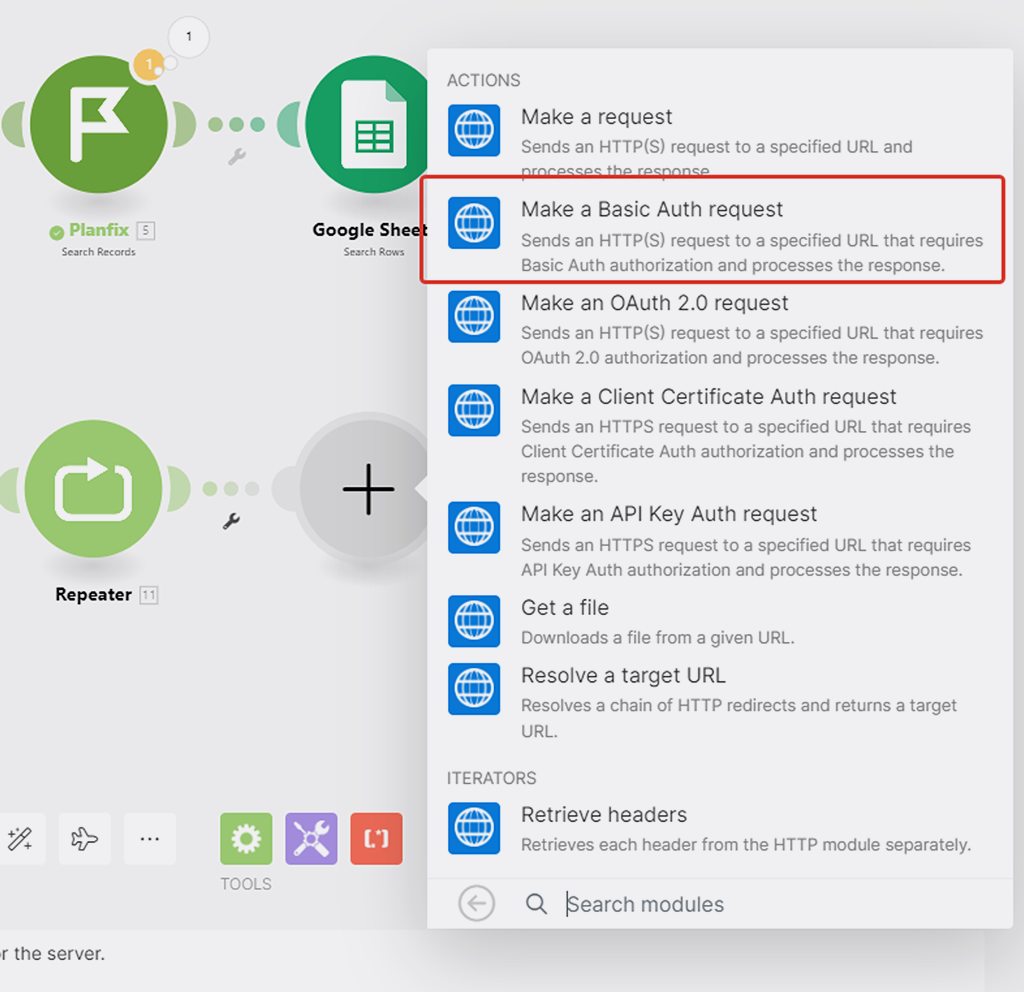
Не работающий как нам надо модуль (1) уберём в сторону, а на его место поставим модуль (5) HTTP API запроса:
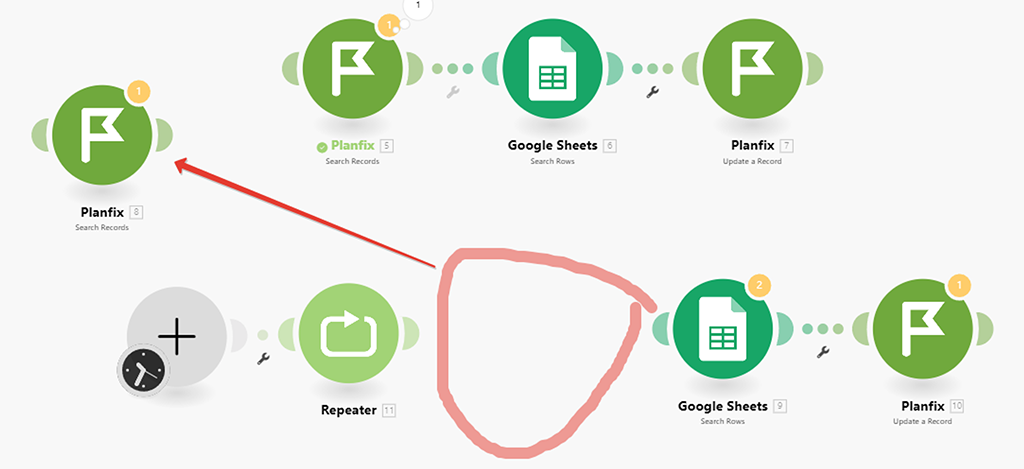
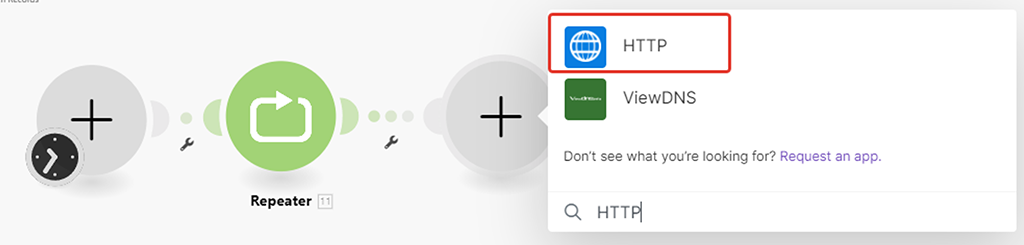
Выбираем вариант «Make a Basic Auth request»:
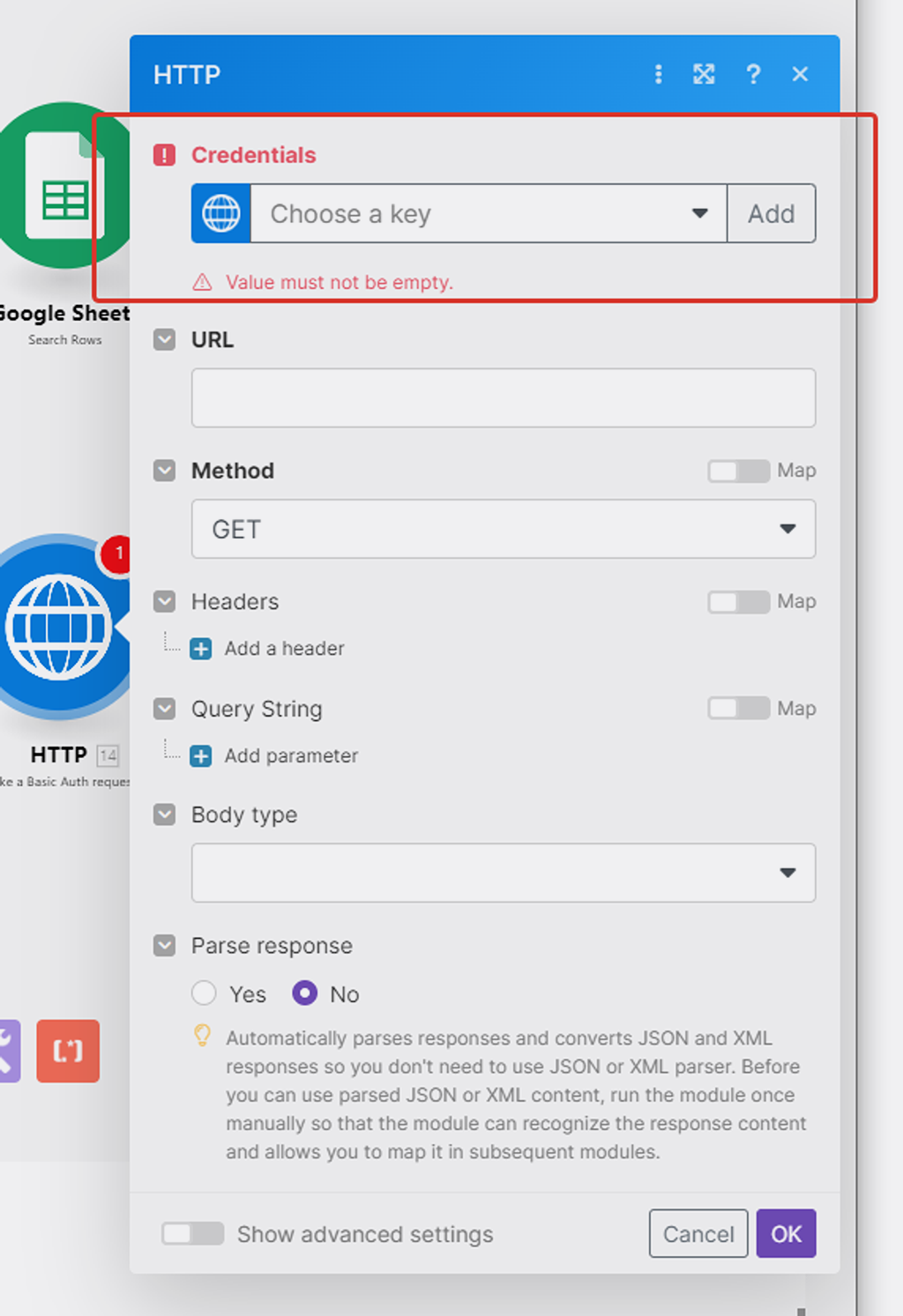
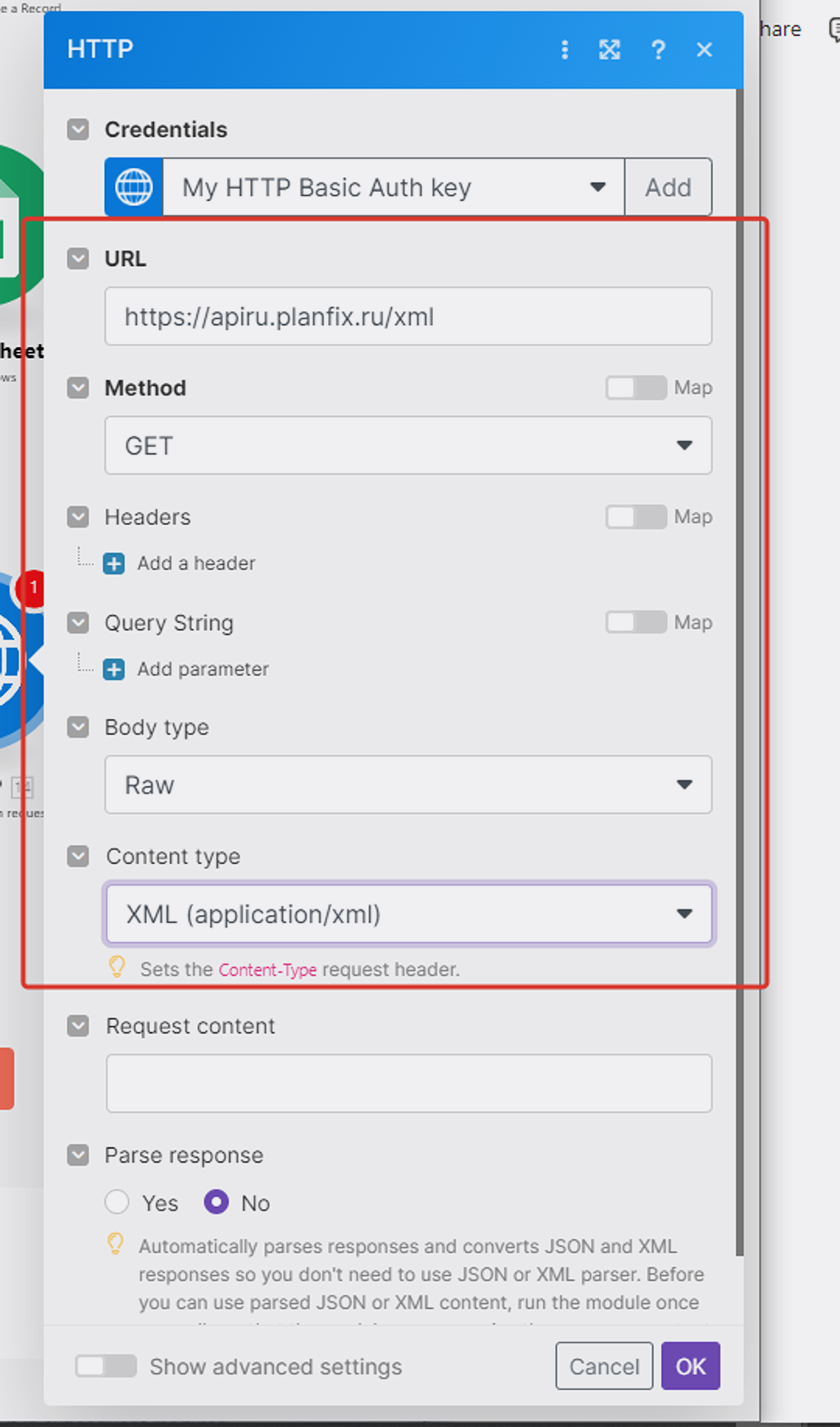
Настраиваем это модуль.
Прежде настроим ключ авторизации с PlanFix — кликаем на добавить (add):
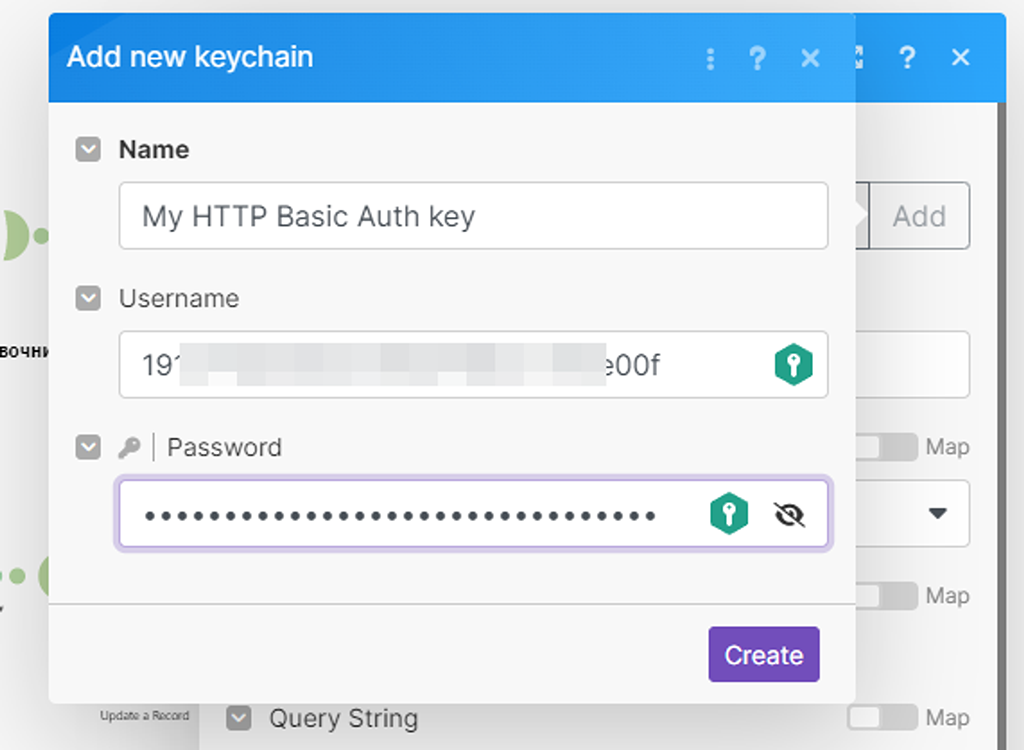
- В поле username — указываем APIKey из аккаунта PlanFix.
- В поле password — указываем Token из аккаунта PlanFix.
Эти данные для авторизации мы создавали в начале нашей статьи и они находятся в настройках ПланФикса в разделе: «Доступ к API» — «XML API»:
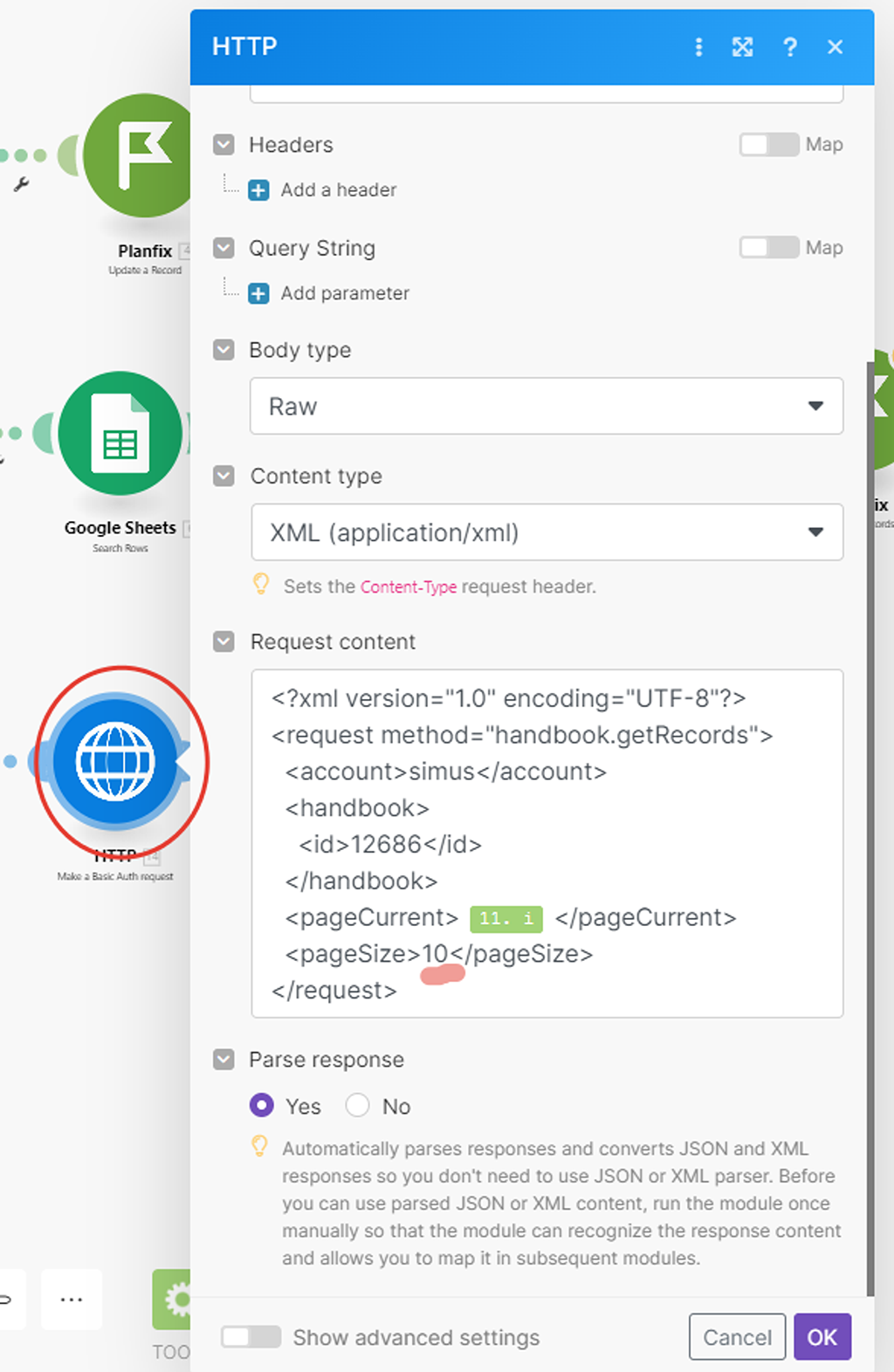
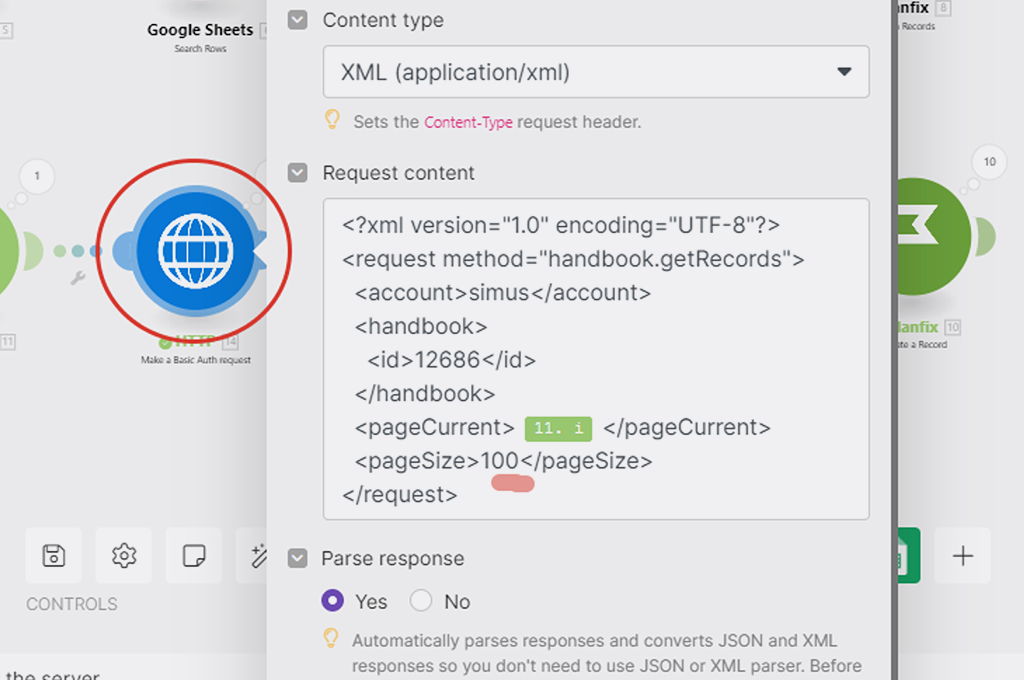
В следующем блоке настроек модуля указываете всё, как на скриншоте. Для поля URL используете адрес API PlanFix — https://apiru.planfix.ru/xml
Для заполнения поля «Request content» (собственно, сама суть API запроса) копируете из инструкции по API запросу все данные API запроса и вставляете их в это поле:
<?xml version="1.0" encoding="UTF-8"?>
<request method="handbook.getRecords">
<account></account>
<sid></sid>
<handbook>
<id></id>
</handbook>
<parentKey></parentKey>
<pageCurrent></pageCurrent>
<pageSize></pageSize>
<signature></signature>
</request>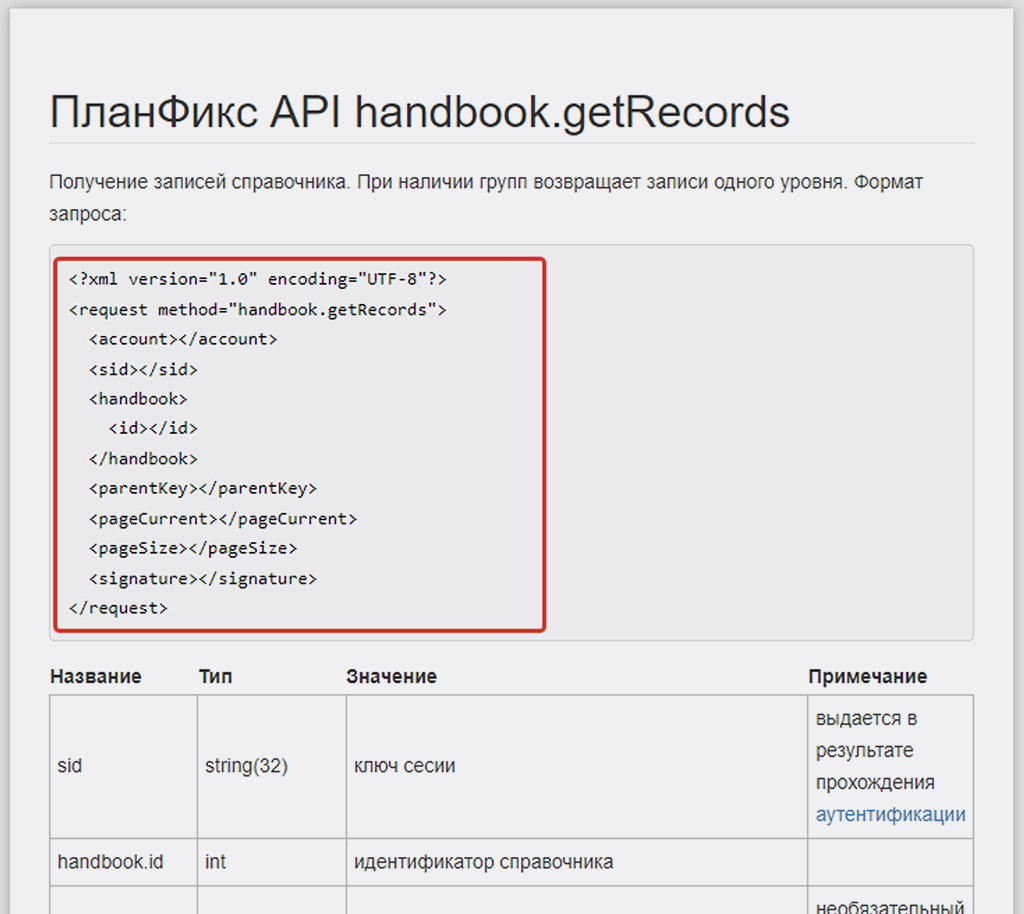
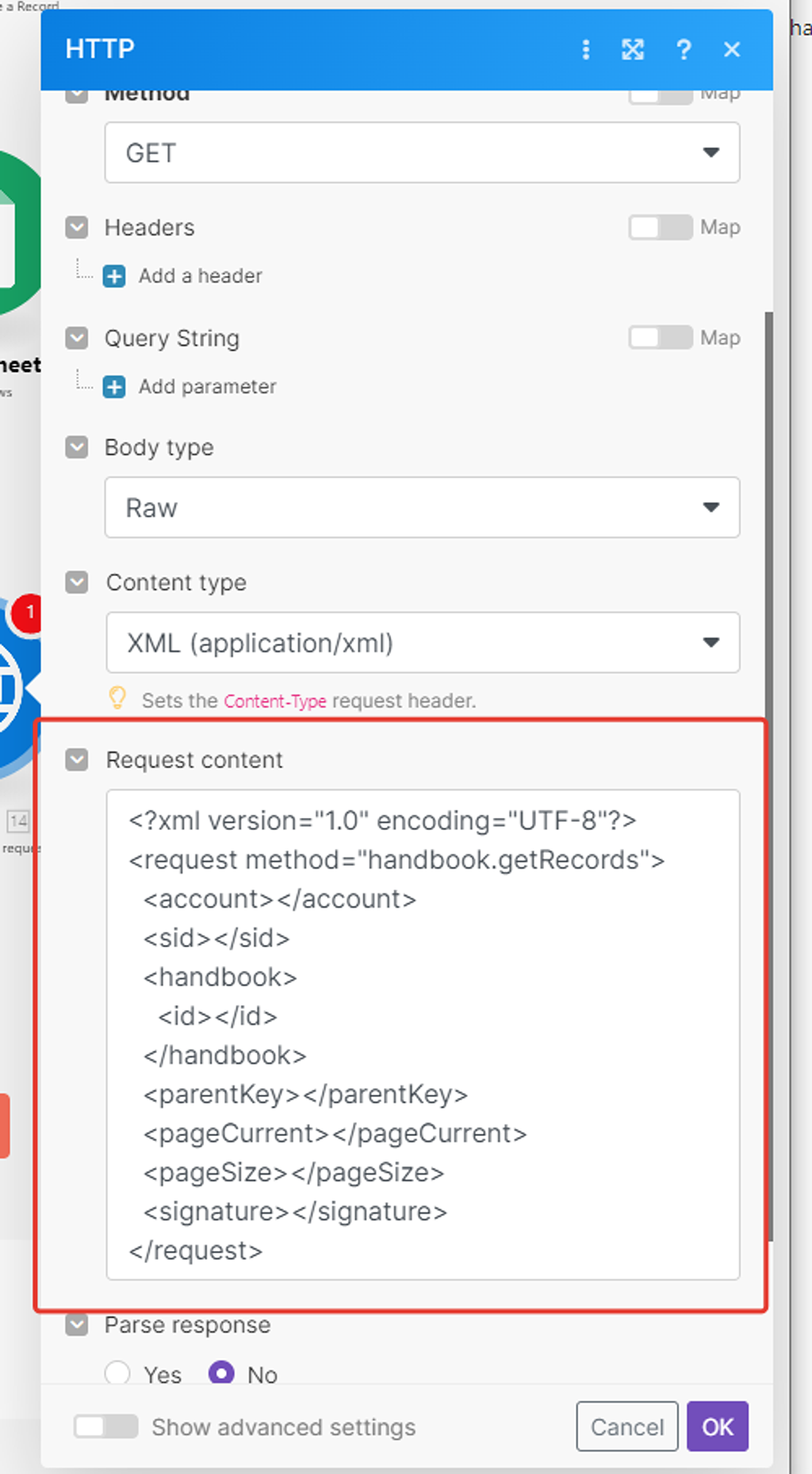
Кое что надо будет удалить, а какие-то параметры как раз заполнить нужными данными.
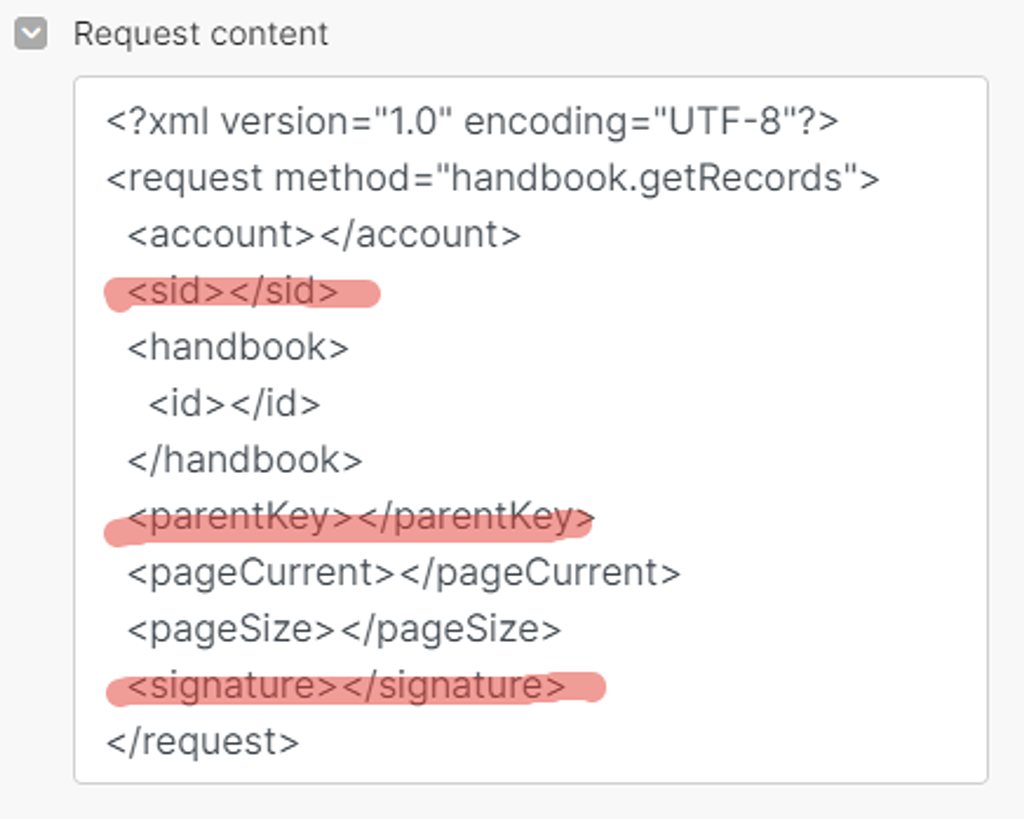
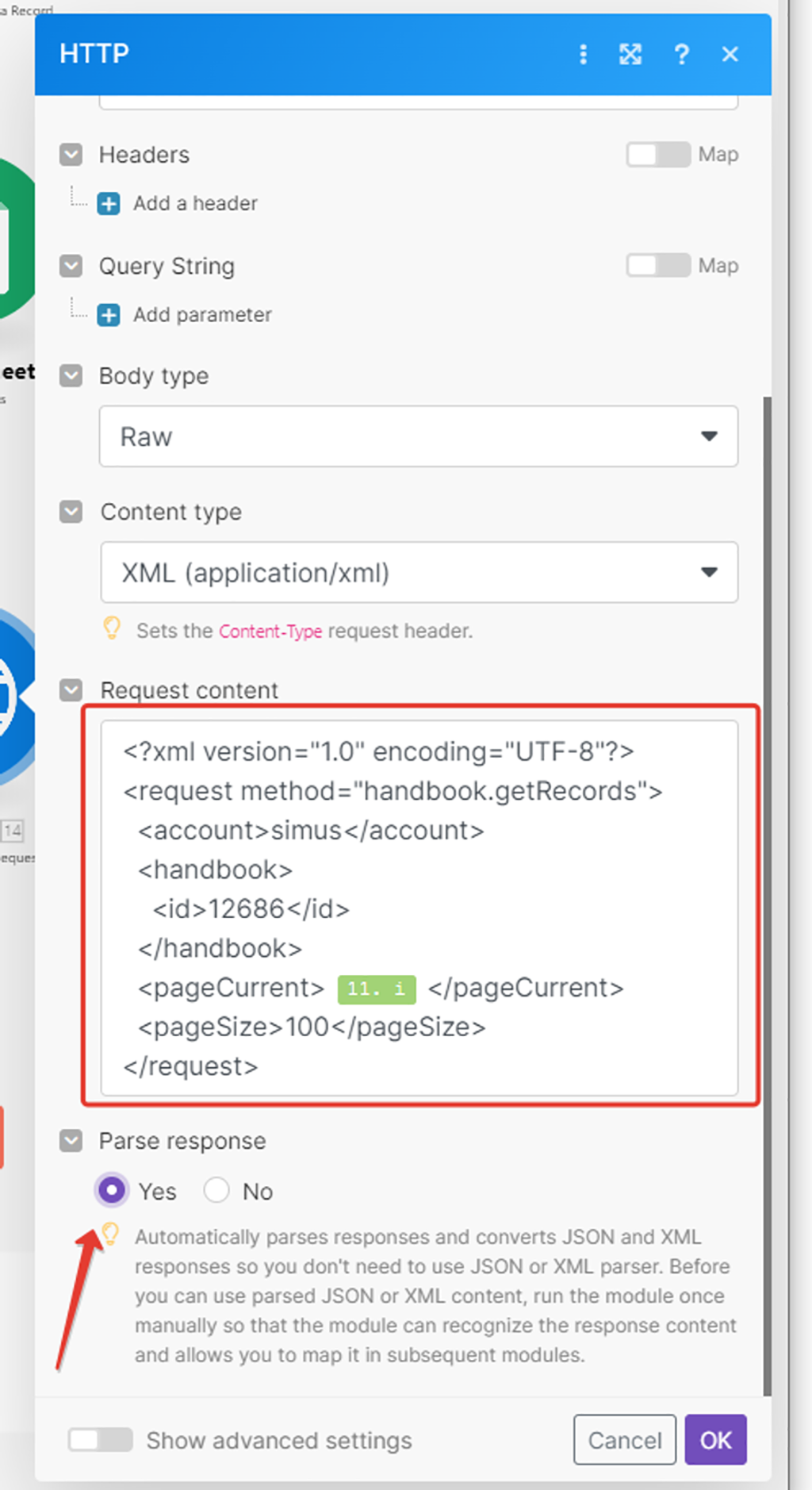
Прежде удалим то, что для Make в API запросе к PlanFix не нужно — помечено красным маркером. SID и SINGATURE — это параметры для авторизации API запроса, но мы их уже сформировали альтернативно в блоке выше (API ключ и токен). PARENT KEY — не обязательный параметр (признак группы):
Далее, в оставшихся параметрах API запроса нам надо указать название нашего аккаунта в ПланФиксе, а также ID справочника, который мы узнали с помощью лайфхака ранее — 12686:
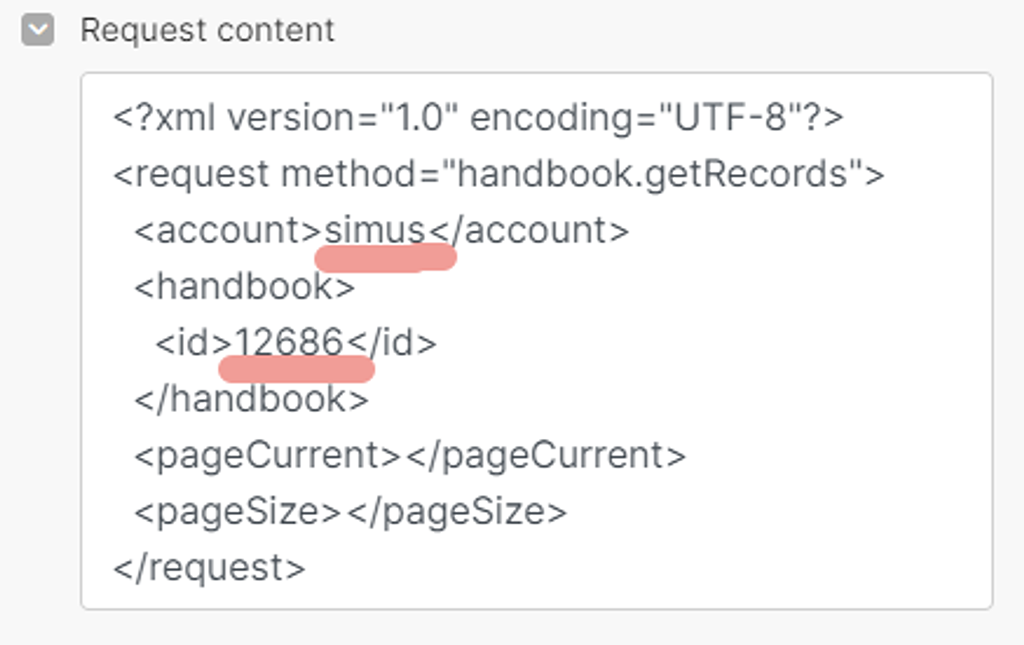
Название вашего аккаунта в ПланФиксе — это часть адресной строки в браузере до «*******.planfix.ru», когда вы авторизированы и работаете с ним. У меня сейчас такой аккаунт SIMUS, у вас свой:

Ок. Теперь настроим какую сотню записей API запросу запрашивать из справочника в PlanFix:
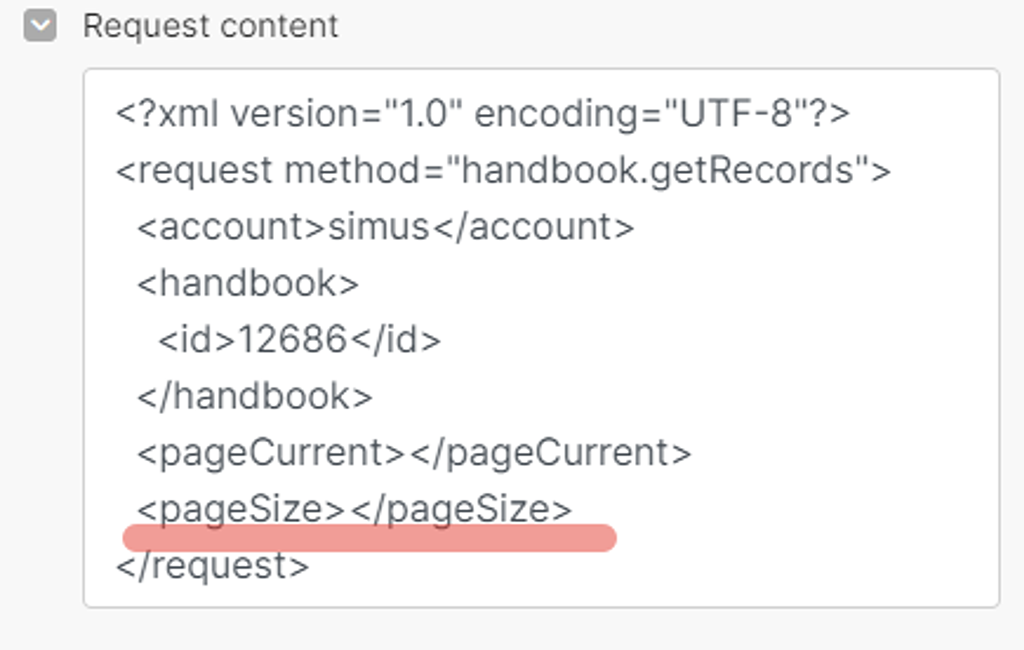
Параметр PageSize как раз отвечает за то, сколько записей в принципе будет браться. Этот тот limit, который был в старом модуле интеграции. Мы уже знаем, что максимально может браться 100 записей — это значение и указываем:
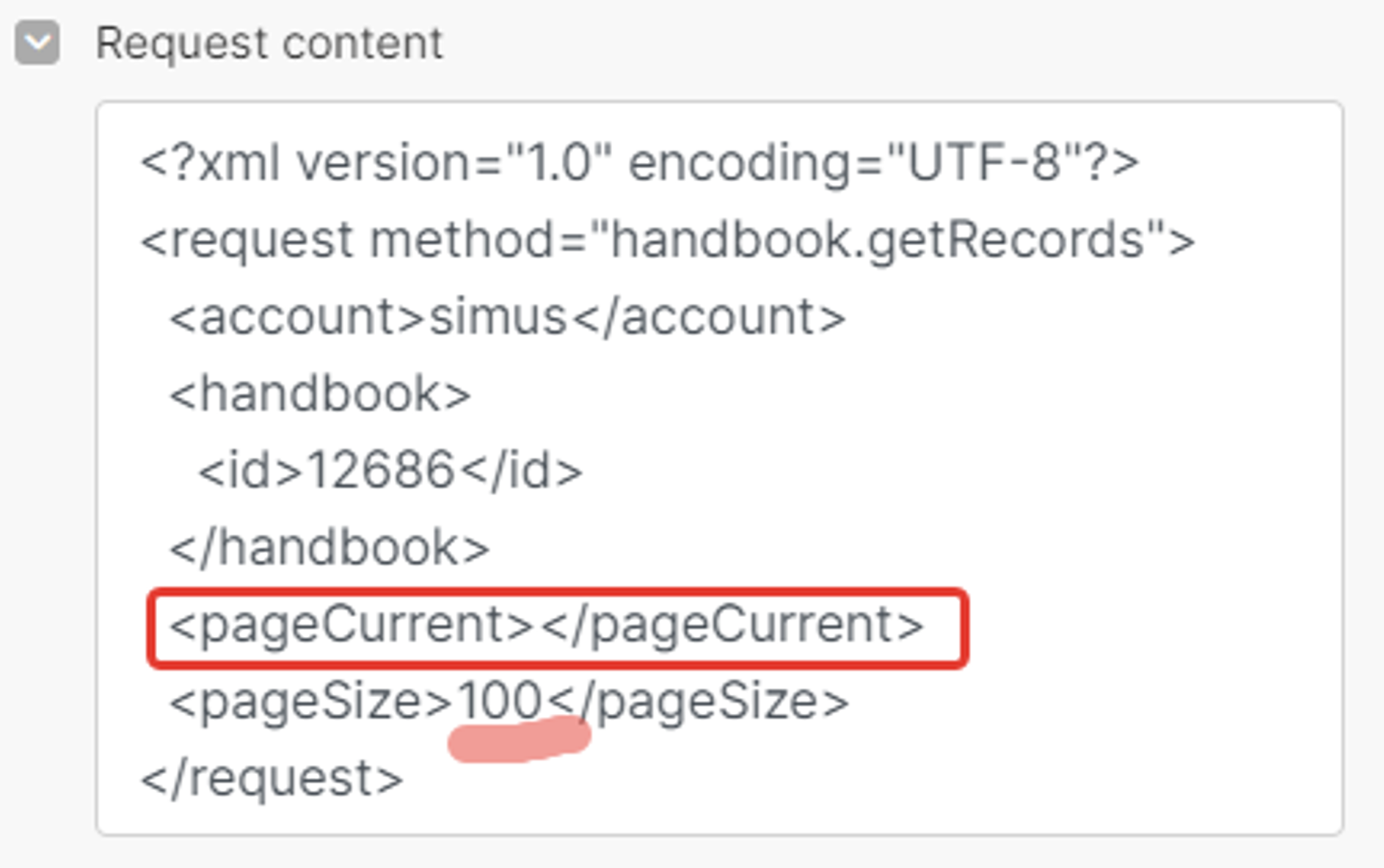
А вот за то, какая это будет сотня (первая, вторая и т.д) отвечает параметр «pageCurrent».
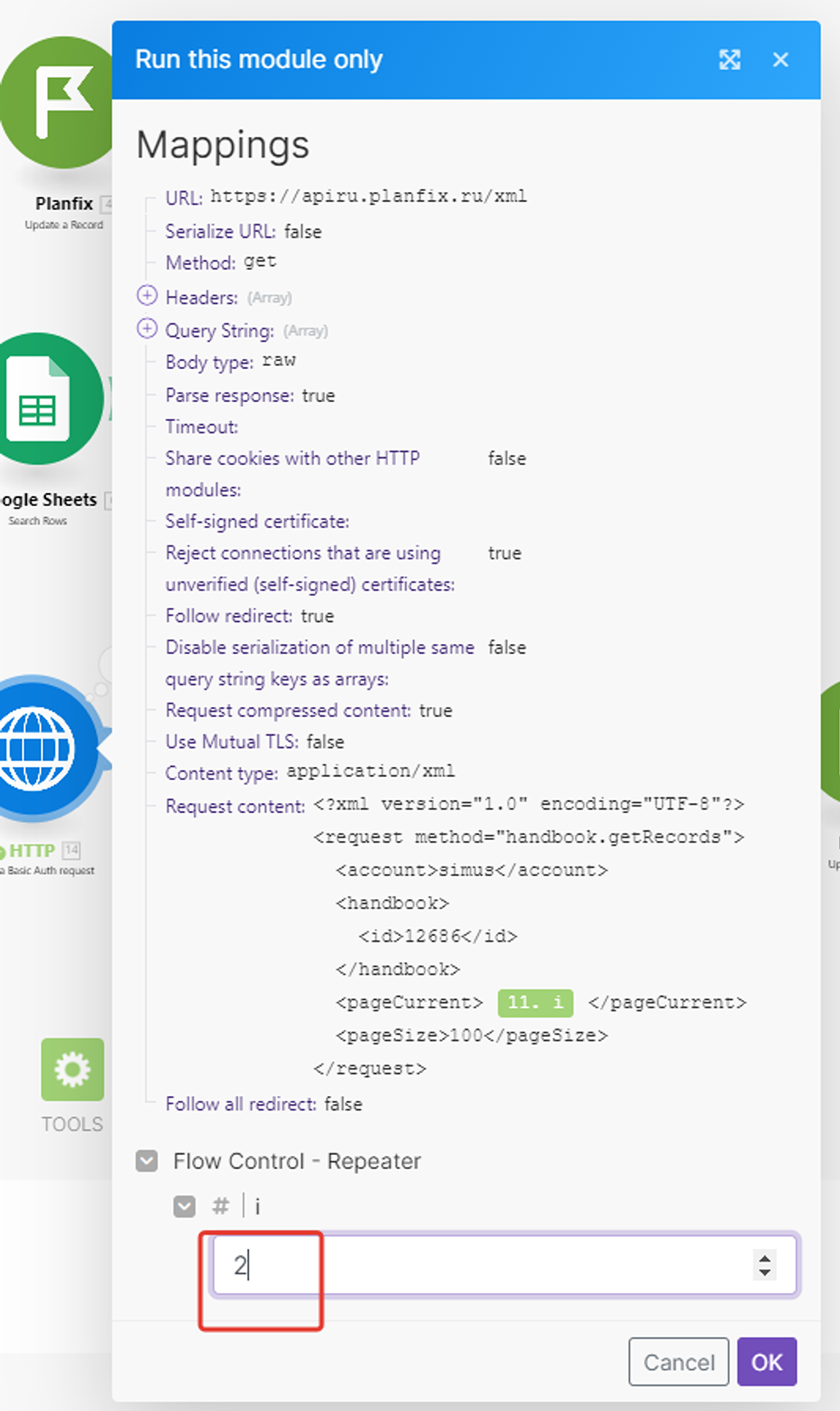
Что указывать здесь? Можем вручную запустить 4 раза сценарий и вручную менять здесь показатель от 1 до 4, но лучше автоматизировать и эту подзадачу.
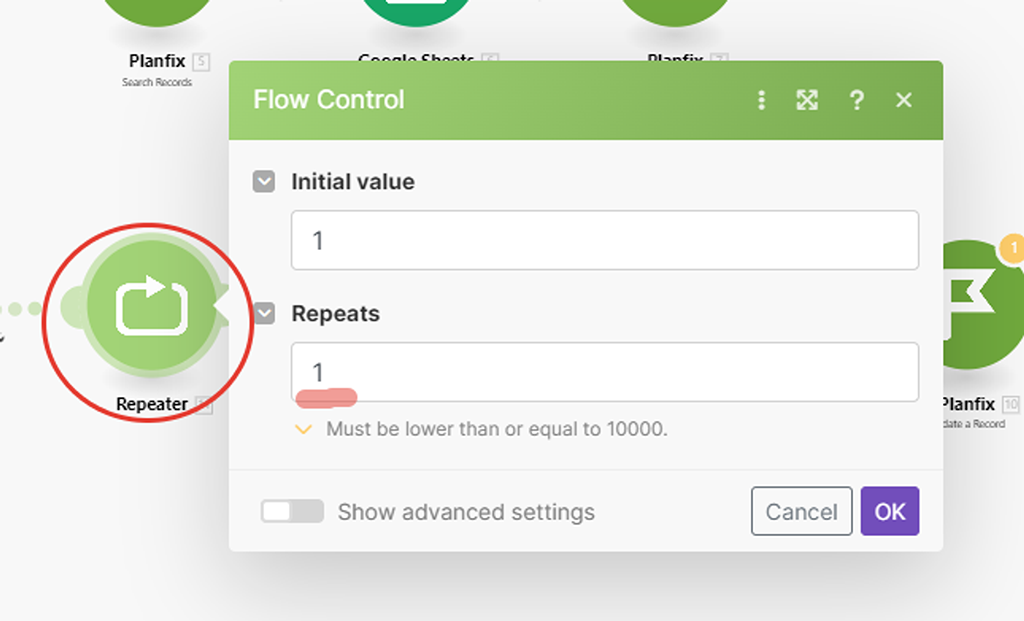
Перед этим мы с вами уже настроили модуль (4), который отвечает сколько раз надо запускать сценарий — модуль «Repeater»:
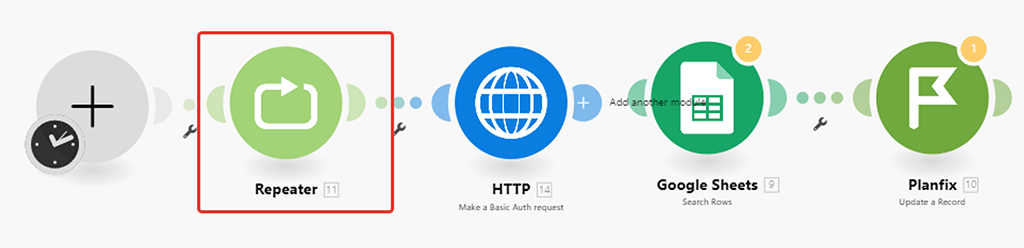
Параметр в его настройках «Initial value» показывает, с какого места его запускать — т.е. если у нас всего 4 запуска сценария, то по умолчания он запускается 1-ый раз, потом 2, 3 и 4. Этот параметр как раз динамически меняется каждый раз с новым запуском сценария на соответствующее значение — он идеально подходит для определения, какую сотню выгружать из PlanFix:
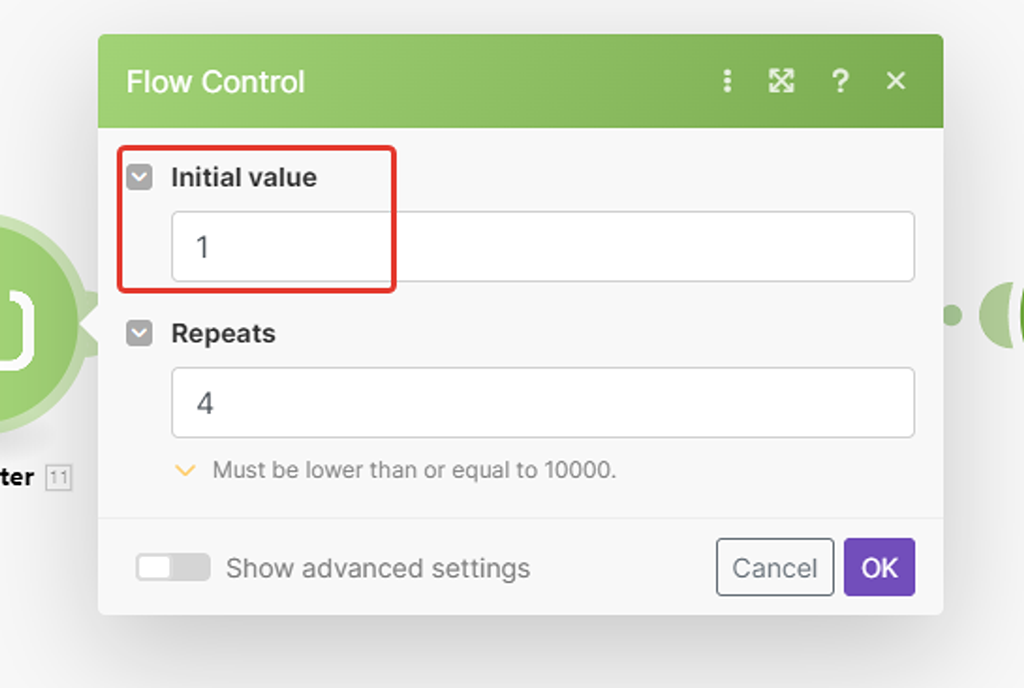
Это значение мы как раз и поставим в значение параметра нашего API запроса — при клике в позиции параметра появится список модулей, из которых можно брать данные, а так как предлагаются только модули, которые располагаются до модуля, с которым работаем, то и выбор у нас будет только один:
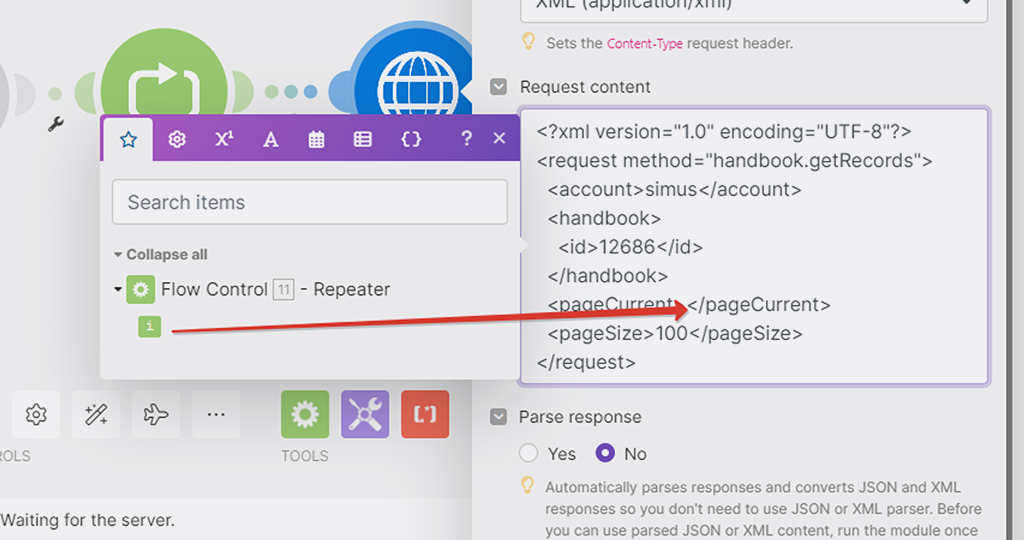
Вот теперь параметры нашего API запроса указаны верно. Только ещё надо поставить галочку, чтобы результаты этого запроса распарсивались (т.е. представлялись структурно):
Ок. Проверим корректность только этого нового модуля HTTP API запроса к нашему справочнику в PlanFix.
Г) Проверяем корректность работы модуля (5) HTTP API запроса
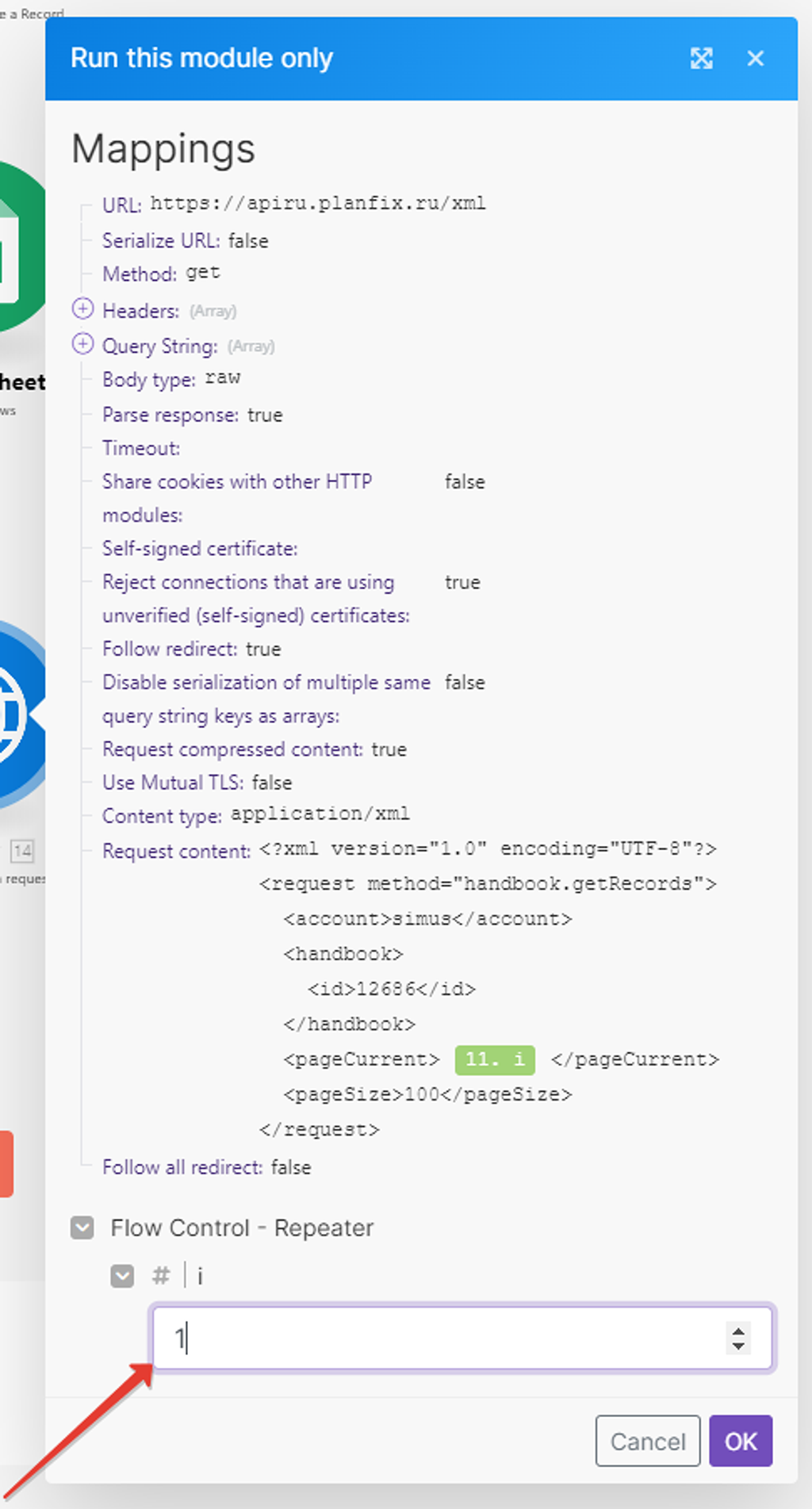
Подставим значение 1 — модуль у нас как раз и спрашивает, какую сотню записей ему брать из справочника, так как работу модуля репитера мы не запускали:

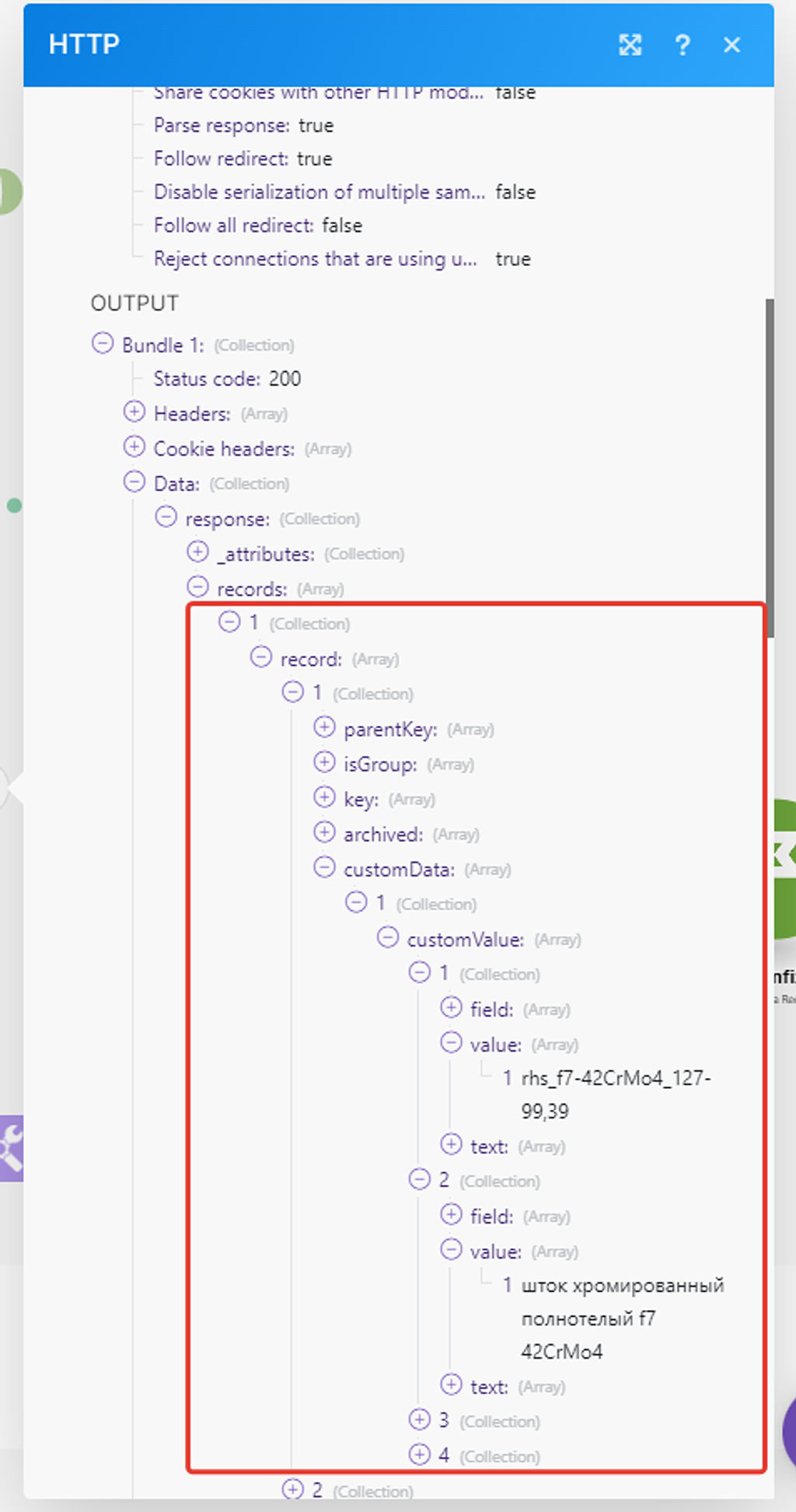
Кликаем на маркер с цифрой 1 и смотрим, что наш модуль получил — всё отлично! Видим массив данных по нашим записям:
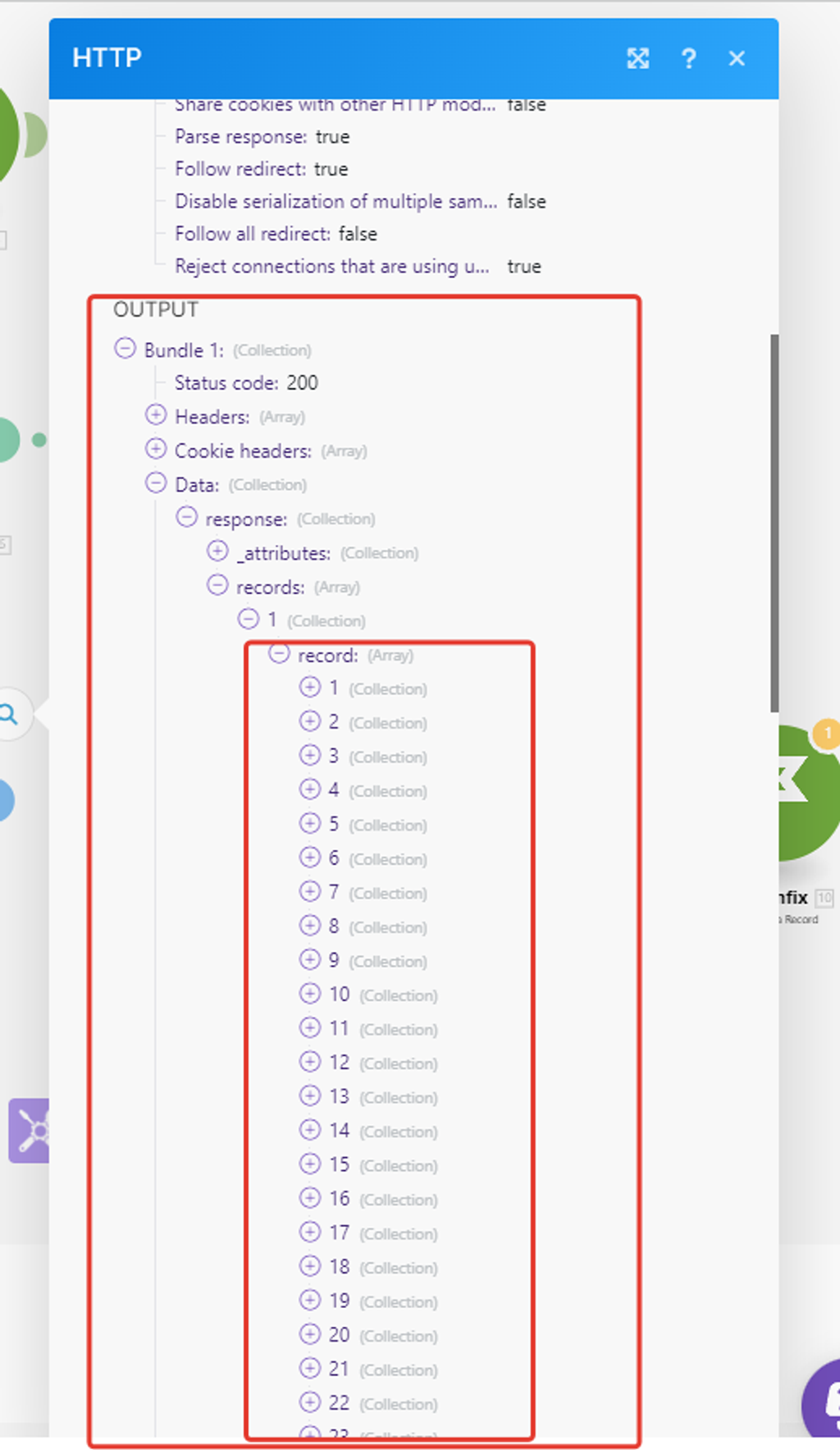
Раскроем подмассив данных 1ой записи:
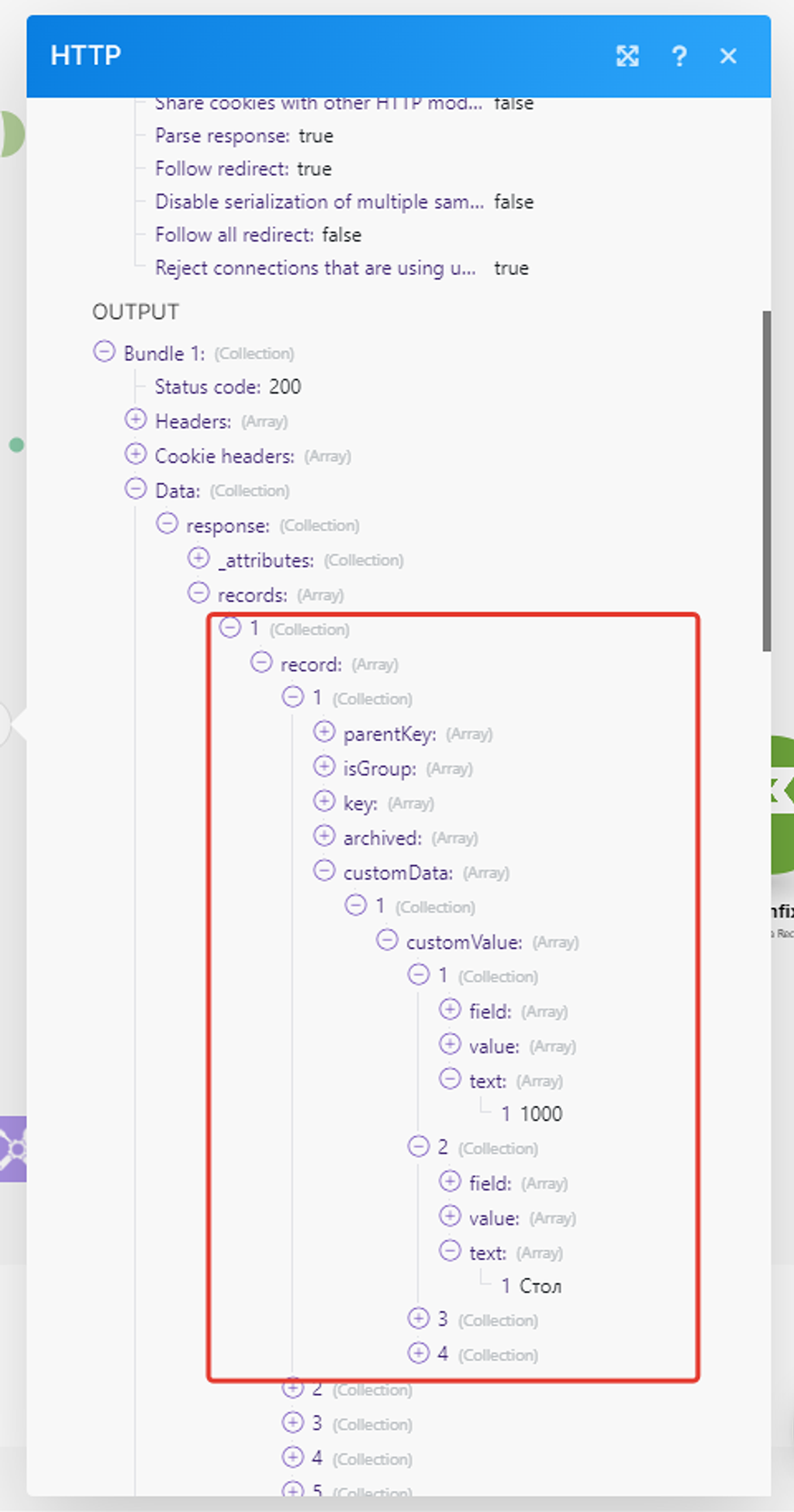
— это как раз наша первая запись в справочнике «Товары» — «Стол».
Значит в подмассиве под №5 будет новая номенклатура:
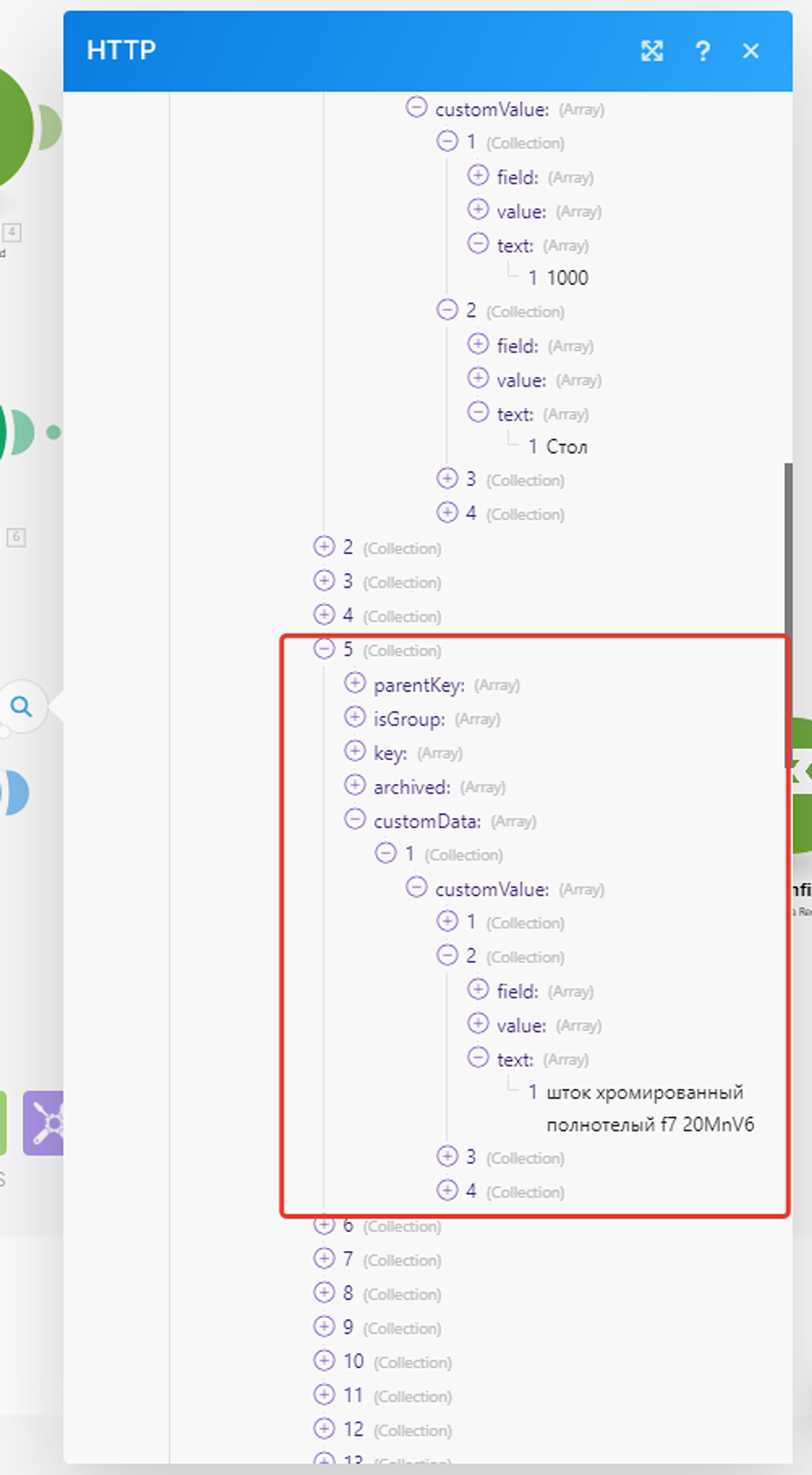
Так и есть – модуль работает.
Ещё раз протестируем работу модуля, изменив значение «№ сотни» на значение «2», чтобы убедиться, что мы получаем следующую сотню записей из справочника. Запускаем модуль заново:
Всё ок, сейчас первым подмассивом у нас запись по новой номенклатуре, которая по списку в справочнике будет под номером 101, скорее всего.
Шаг 3 — Корректировка настроек модуля (2) поиска записи в Google Документе
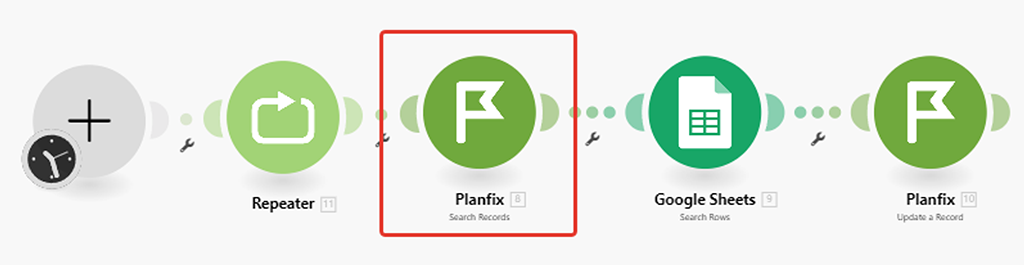
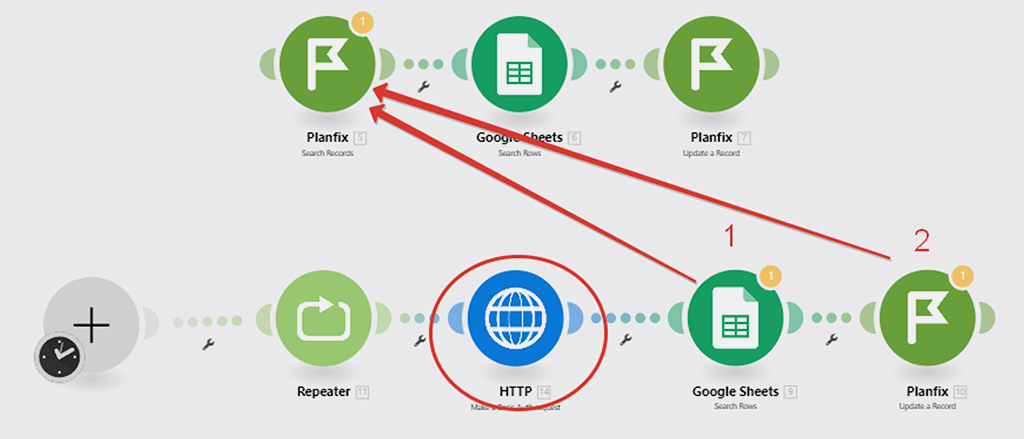
Наш сценарий теперь выглядит таким образом (на верху старый вариант сценария, а внизу новый):
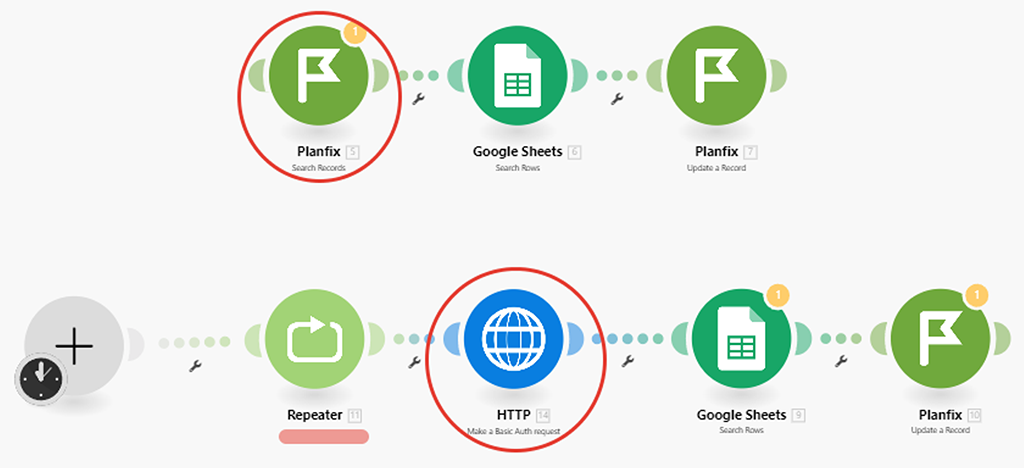
Вместо модуля (1) интеграции от PlanFix, нам пришлось использовать модуль (5) HTTP API запроса. Ну, и ещё мы поставили в начале модуль (4) репитер, чтобы он запускал весь сценарий (а вернее те модули, которые идут после него) необходимое нам количество раз:
Но прежде чем запустить сценарий, нам надо:
- Внести правки в настройку модуля (2) поиска записей в Google Документе, так как он оперировал результатами выгрузки модуля от PlanFix, а мы его заменили на штатный модуль Make HTTP для формирования собственного API запроса к PlanFix.
- Внести правки в настройку модуля (3) обновления записей от PlanFix, так как ID записи он также брал из модуля от PlanFix, который мы удалили:
Перенастраиваем модуль (2) поиска записи в Google Документе:
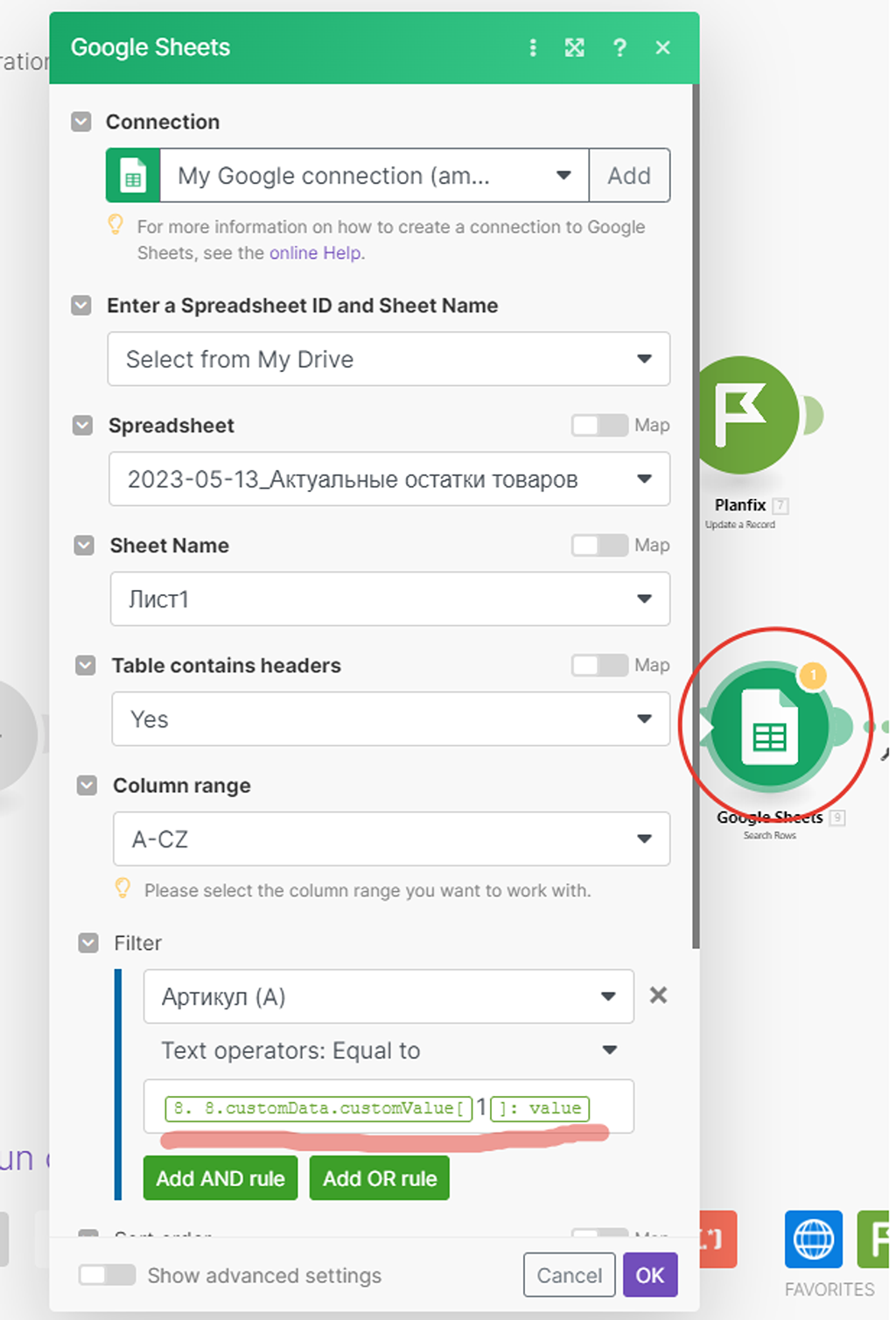
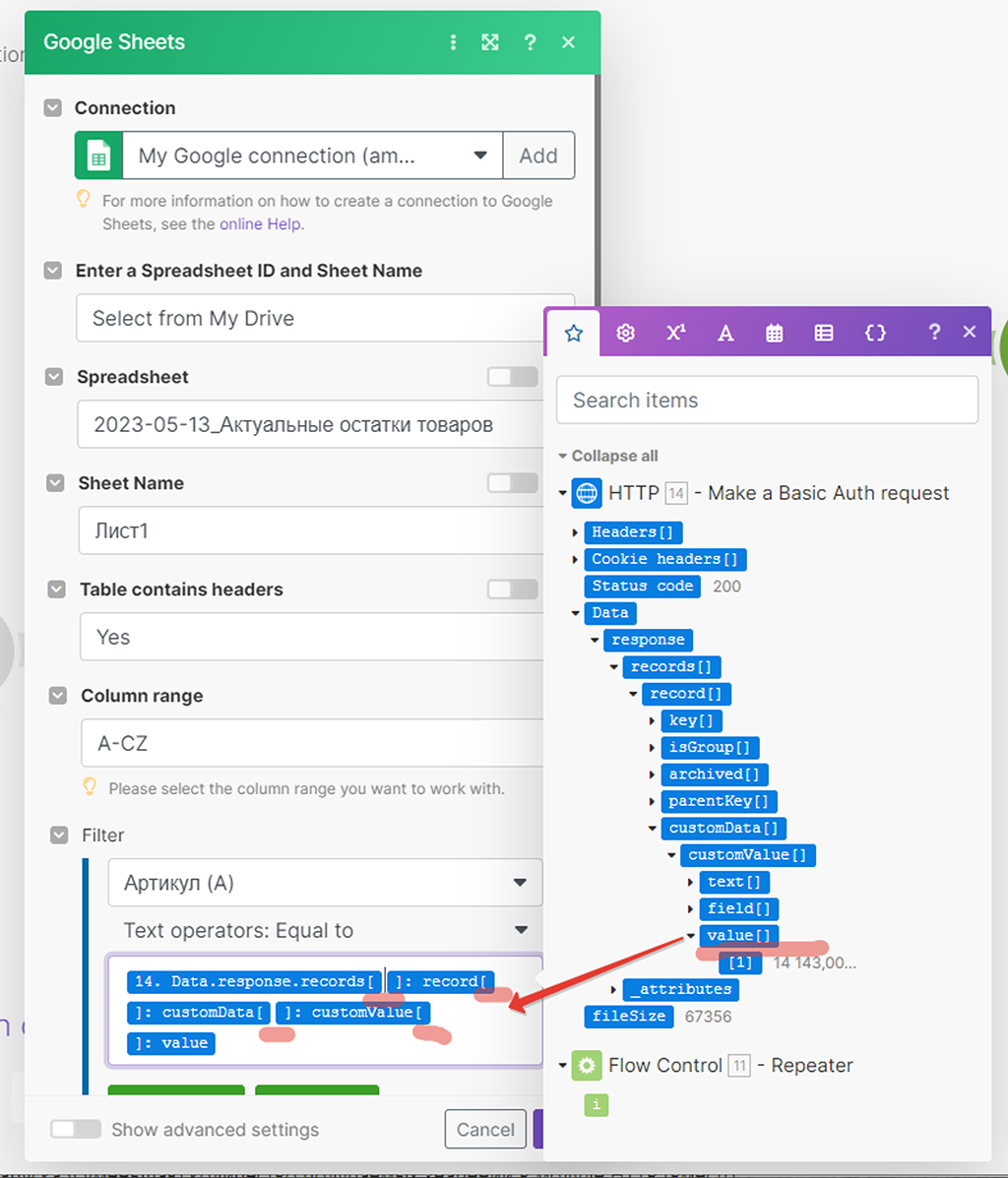
Новый модуль (5) HTTP API запроса выдаёт результат в ином виде, нежели это делал модуль (1) с аналогичным запросом от PlanFix — это отличие принципиально:
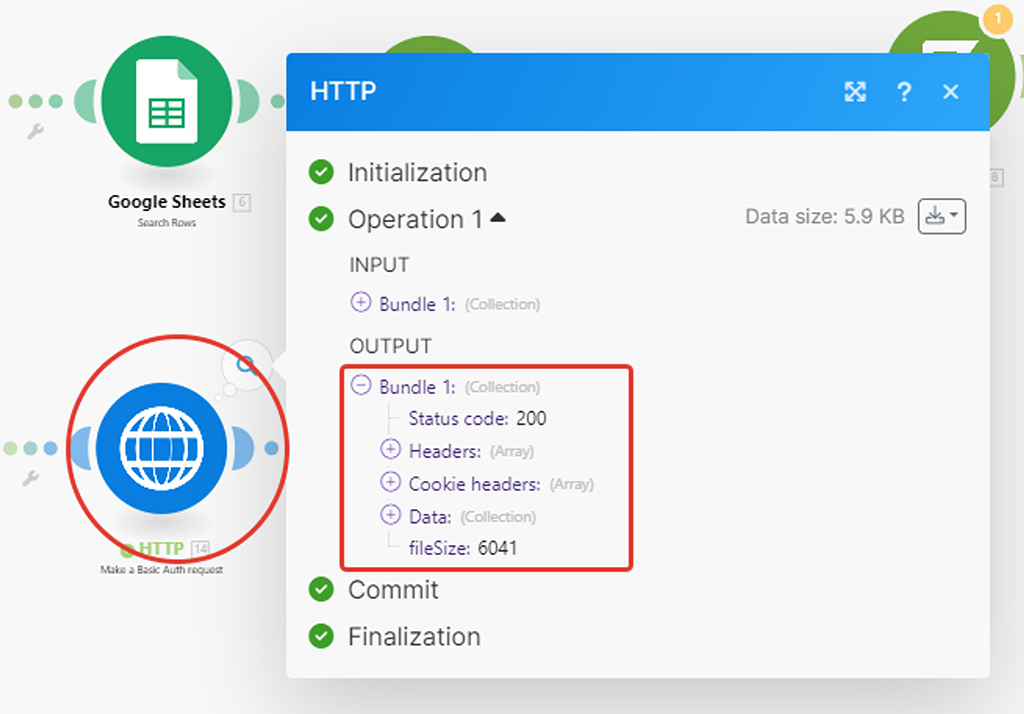
- Модуль (1) от PlanFix выдаёт результат бандлами, т.е. самостоятельными цельными пакетами. Каждая запись — отдельный пакет массива данных. В таком виде вся цепочка сценария «знает», что далее сначала надо отработать по цепочке первый полученный пакет данных (бандл), потом второй, потом третий и так далее:
- А вот Модуль (5) HTTP API запроса выдаёт результат иначе — весь массив данных полученных по всем записям упаковывается в рамках одного бандла (пакета), а там внутри уже разбивается на подмассивы данных, как по записям, так в целом по технической информации по самой таблице. Как бы «недораспарсивается». Это плохо, так как вся дальнейшая цепочка сработает только на 1-ый подмассив данных (на 1-ую запись), а все остальные пропустит:
Посмотрим, как это выглядит в работе.
Сценарий ищет в Google Таблице запись, совпадающую по артикулу с полученной записью из справочника PlanFix. Вот так сейчас выглядит наша Google Таблица:
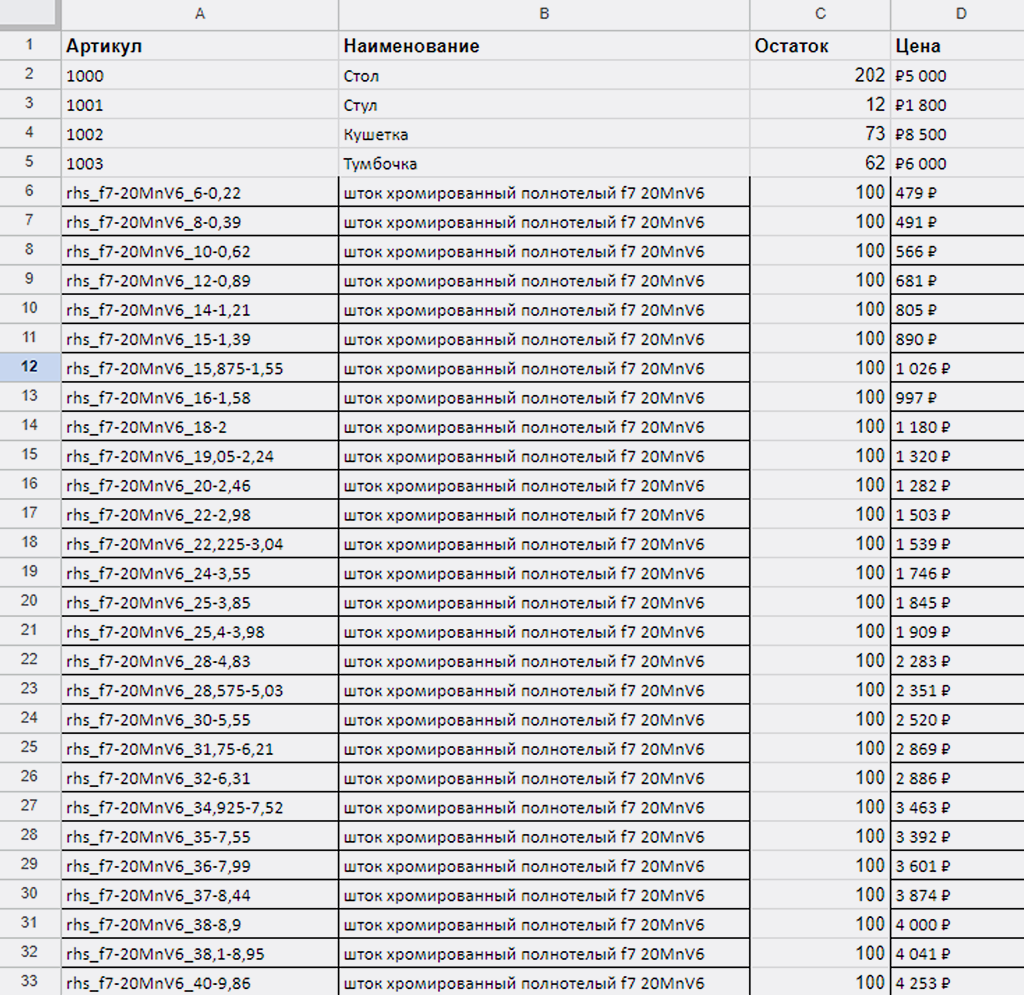
Аналогично выглядит и справочник «Товары»:
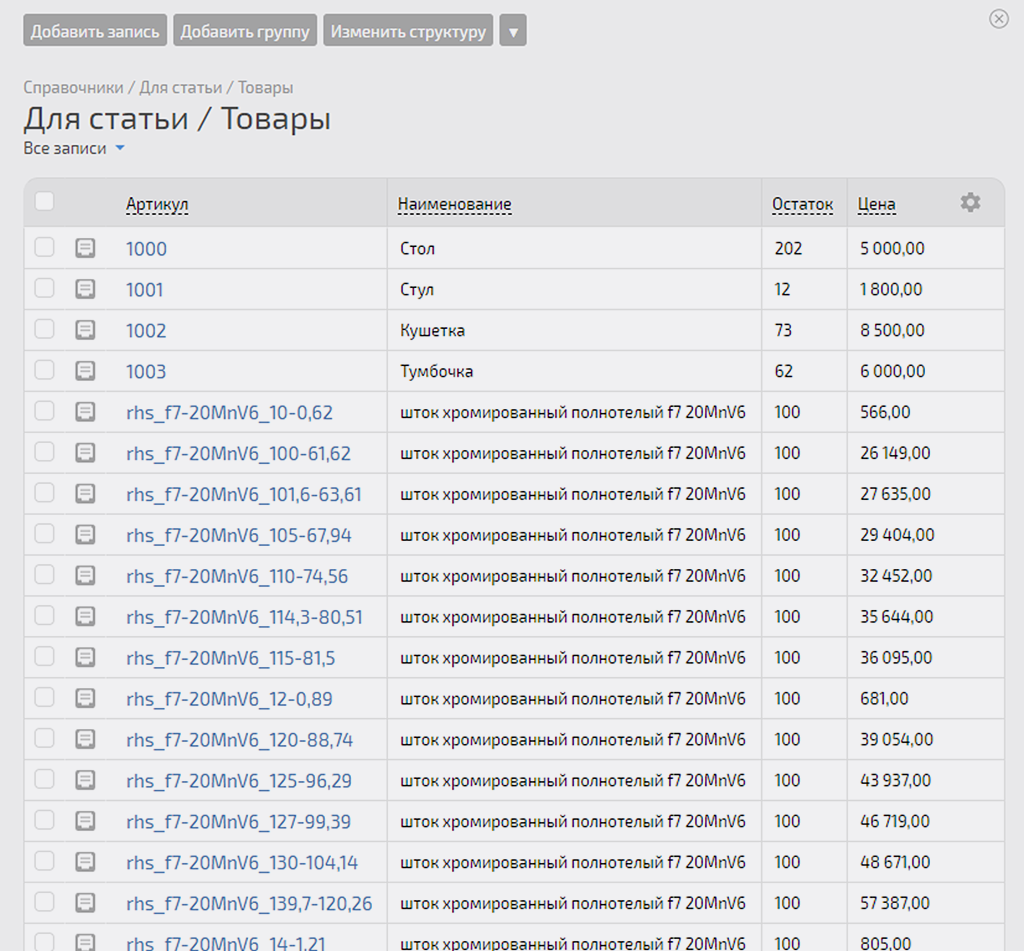
Запускаем сценарий (пока отключил в нём последний модуль (3) — мы его ещё не донастроили):
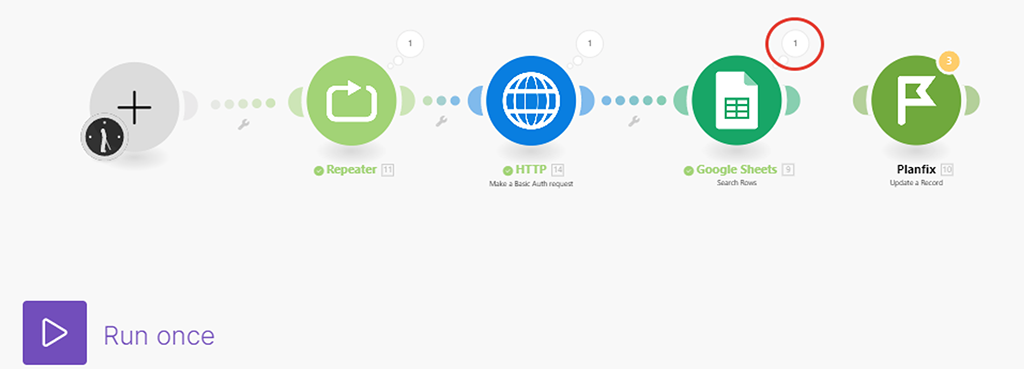
Проверяем результат работы всего сценария по маркеру на модуле (2) Google Таблиц:
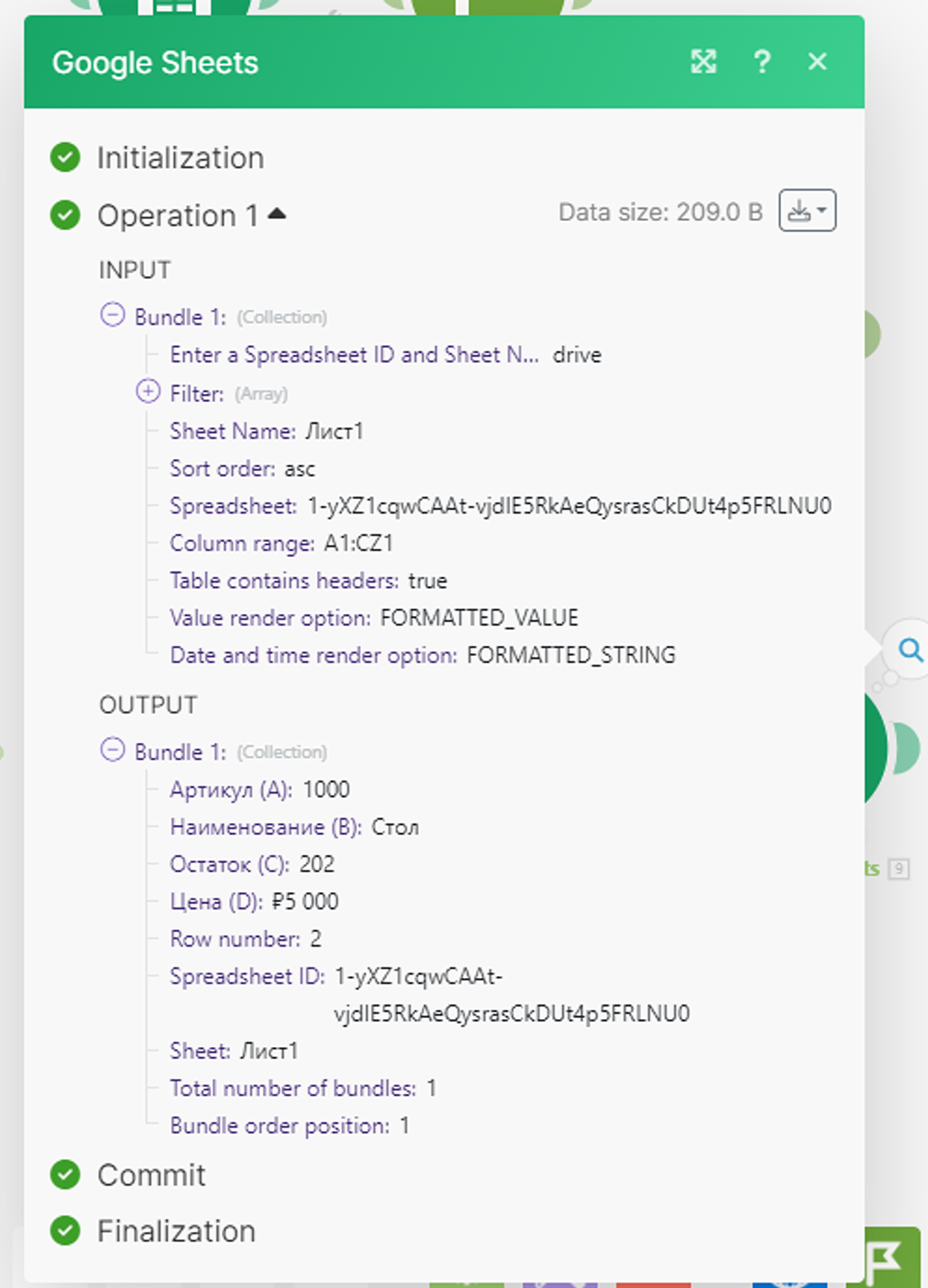
Модуль сработал корректно, но отработал лишь одну первую найденную запись — в нашем случае это «Стол».
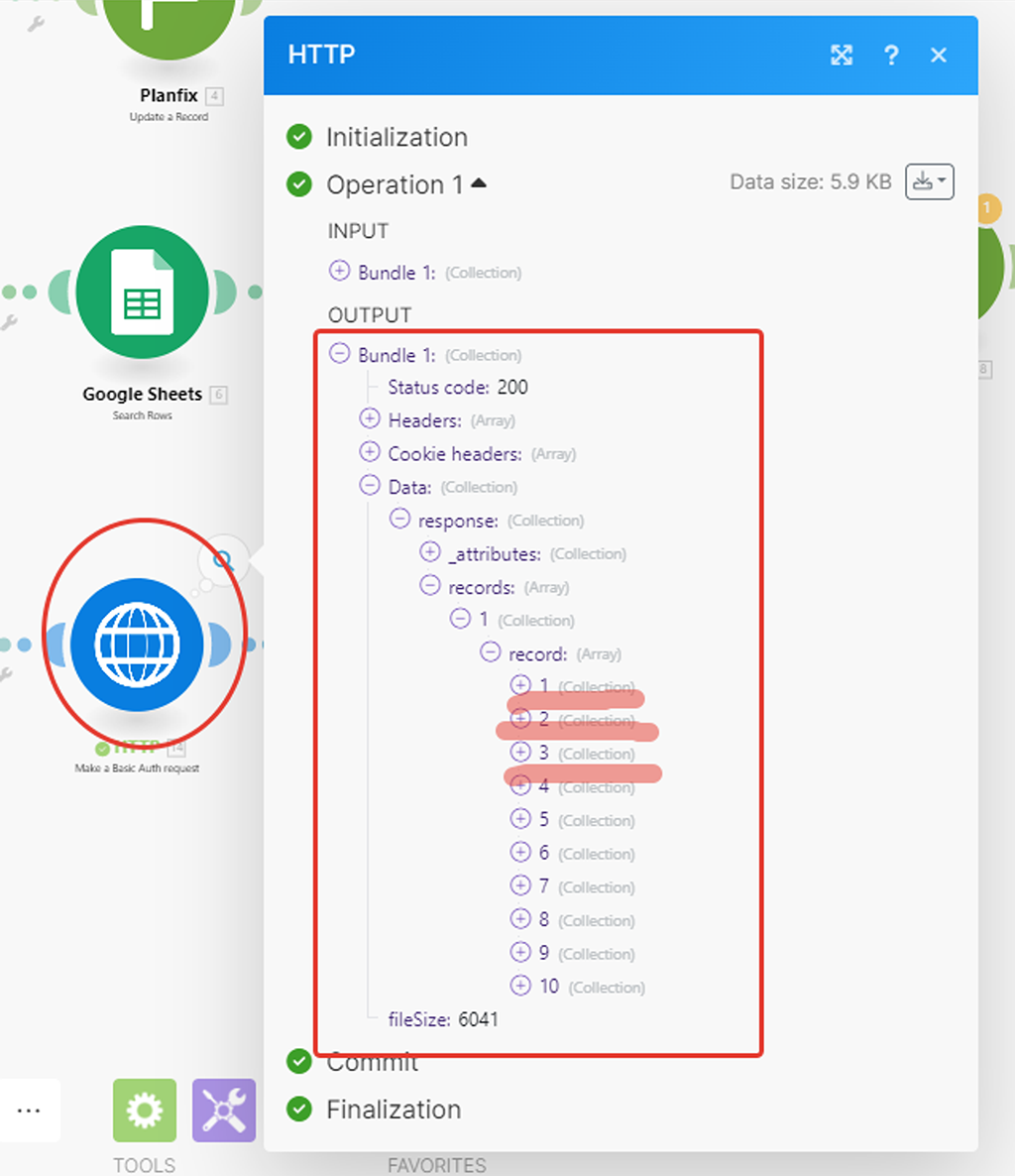
Чтобы нам результаты работы HTTP модуля получить в окончательно распарсенном виде, т.е. когда данные по каждой записи представлены в виде собственного пакета данных (бандла), нам надо добавить после модуля (5) HTTP штатный модуль (6) “Итератор”, который как раз решает такую задачу:
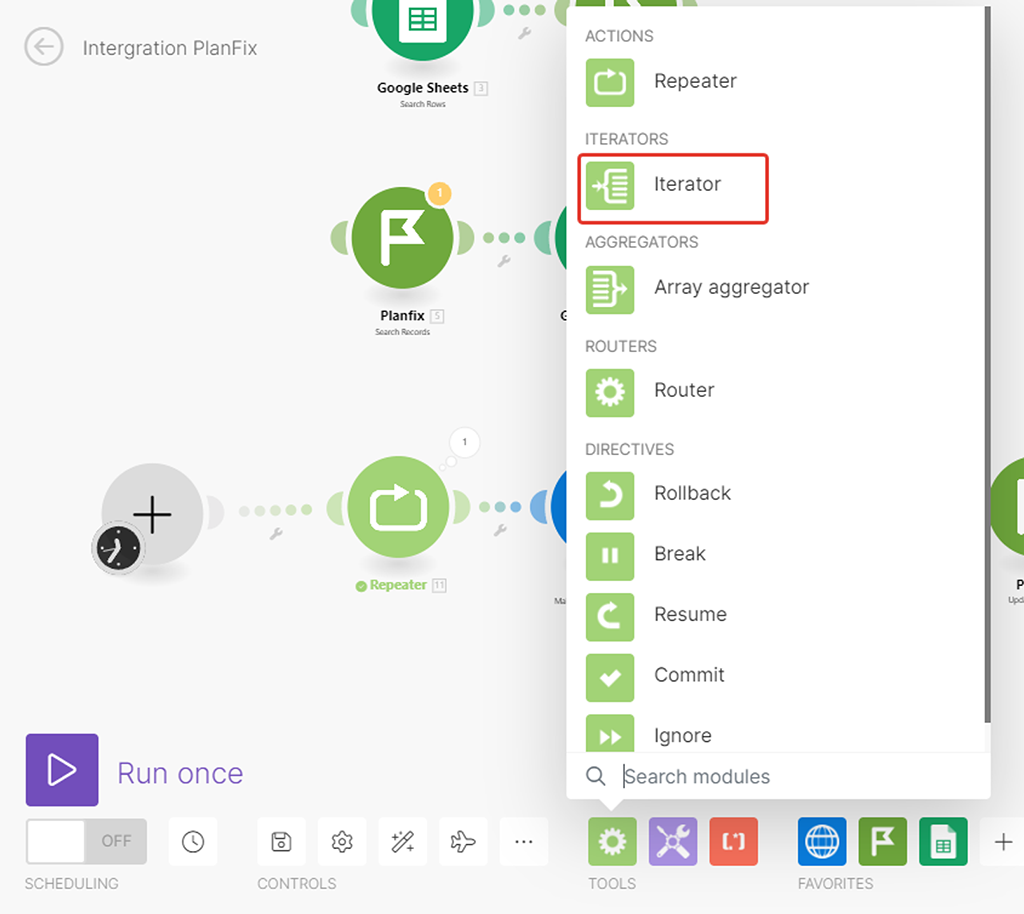
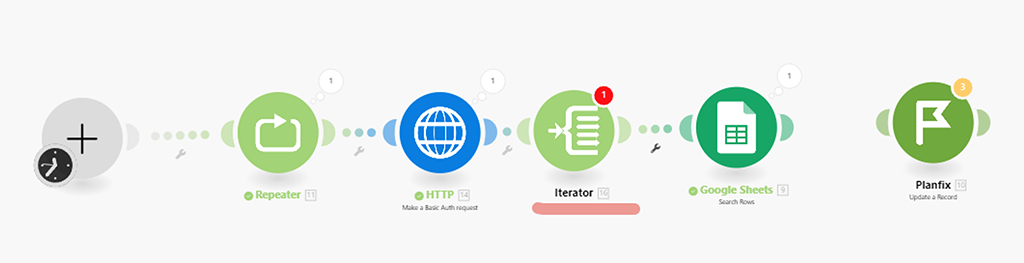
Шаг 4 — Настройка нового модуля (6) Итератор
Суть его простая — на входе у него данные, которые имеют внутренние массивы данных, но не выражены в самостоятельные пакеты. На выходе этот модуль данные преобразовывает в самостоятельные пакеты (бандлы) — что нам и нужно:
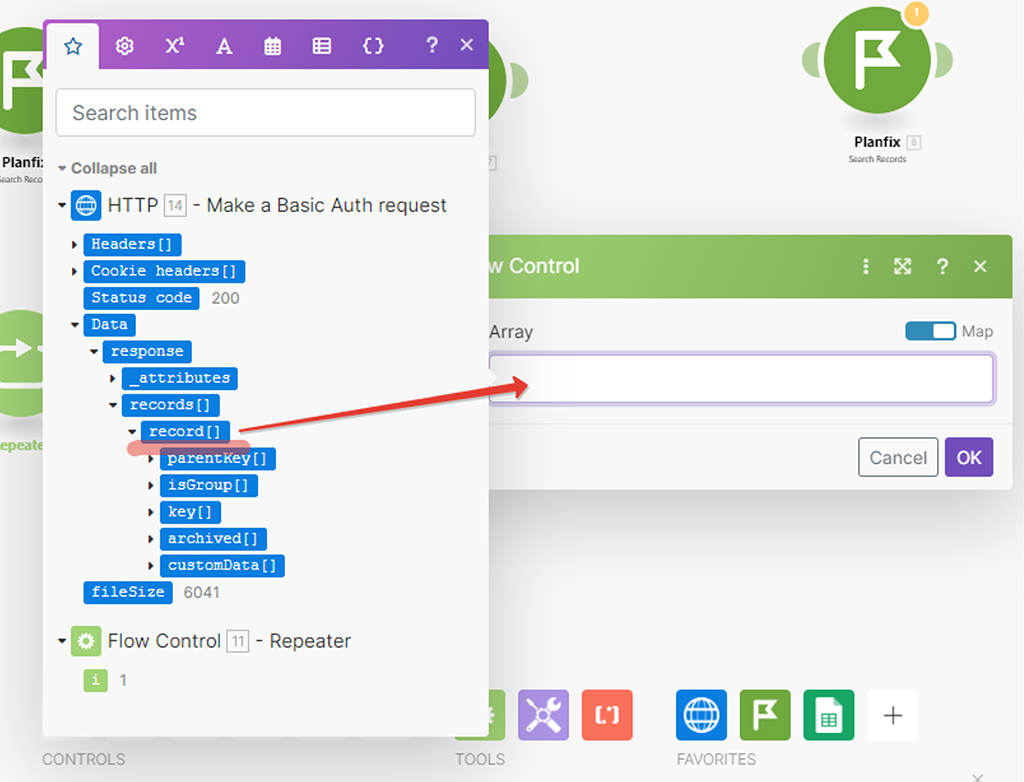
Проверим работу только этого модуля, отключив модули которые идут за ним, так как нам надо, чтобы сработали все модули и которые перед ним:
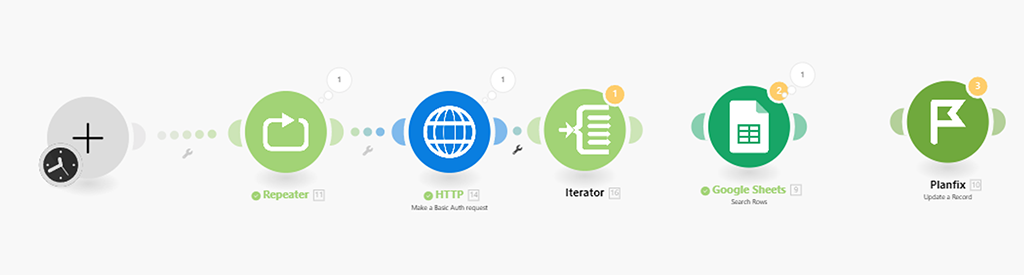

Проверим результат:
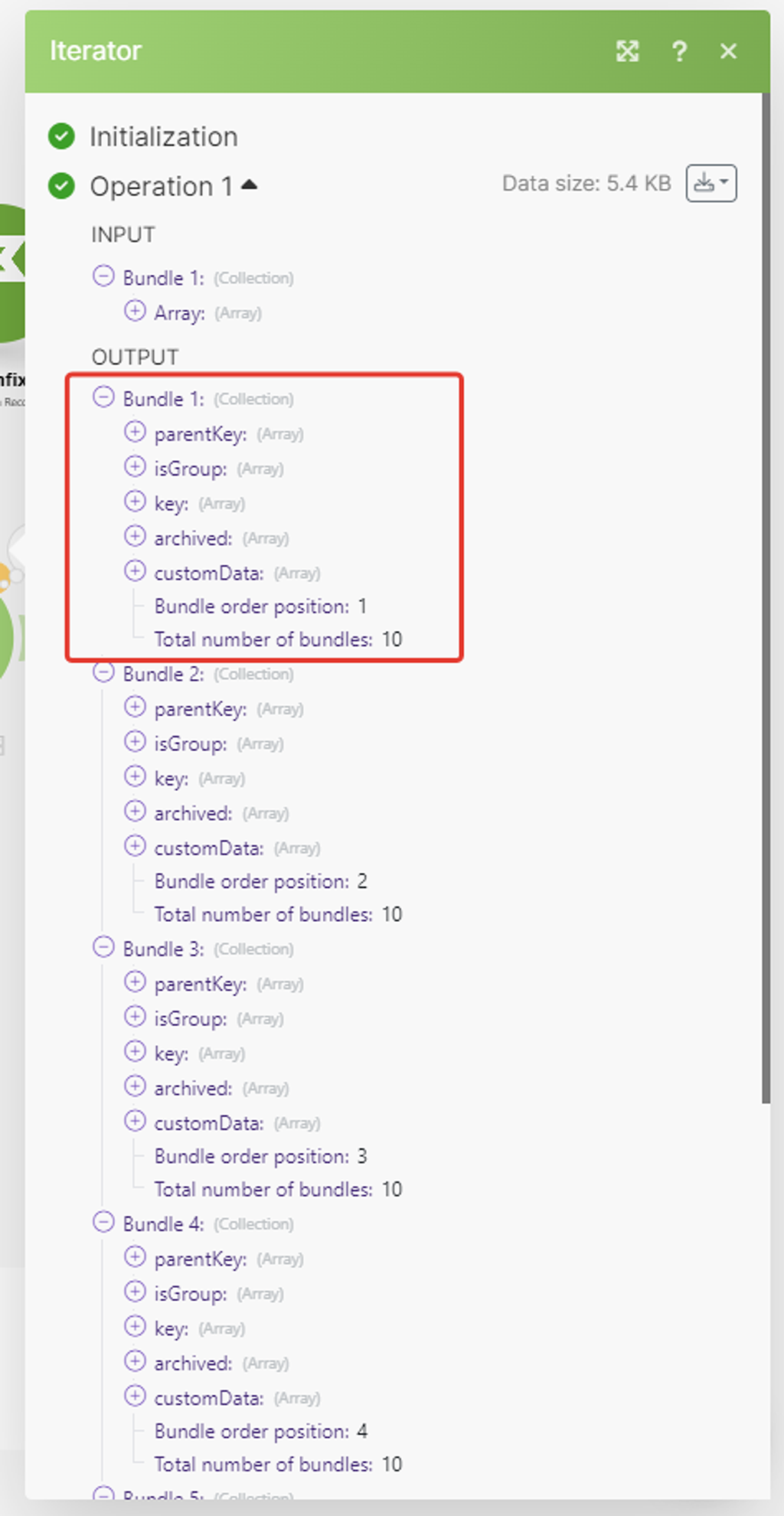
— то, что надо. Теперь все наши массивы данных по каждой записи переупакованы в свой собственный пакет (бандл).
Шаг 5 — Продолжение настройки модуля (2) поиска записей в Google Таблице
Теперь нам снова надо скорректировать модуль (2) поиска записи в Google Документе, чтобы он брал данные не из HTTP модуля (5), а распарсенные данные в бандлы уже из модуля Итератора (6):
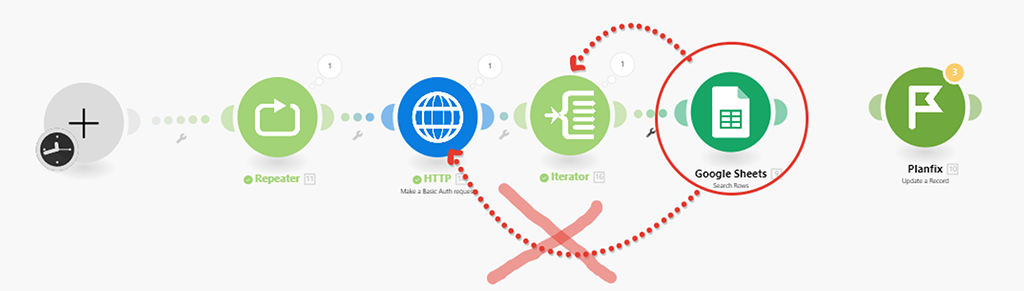
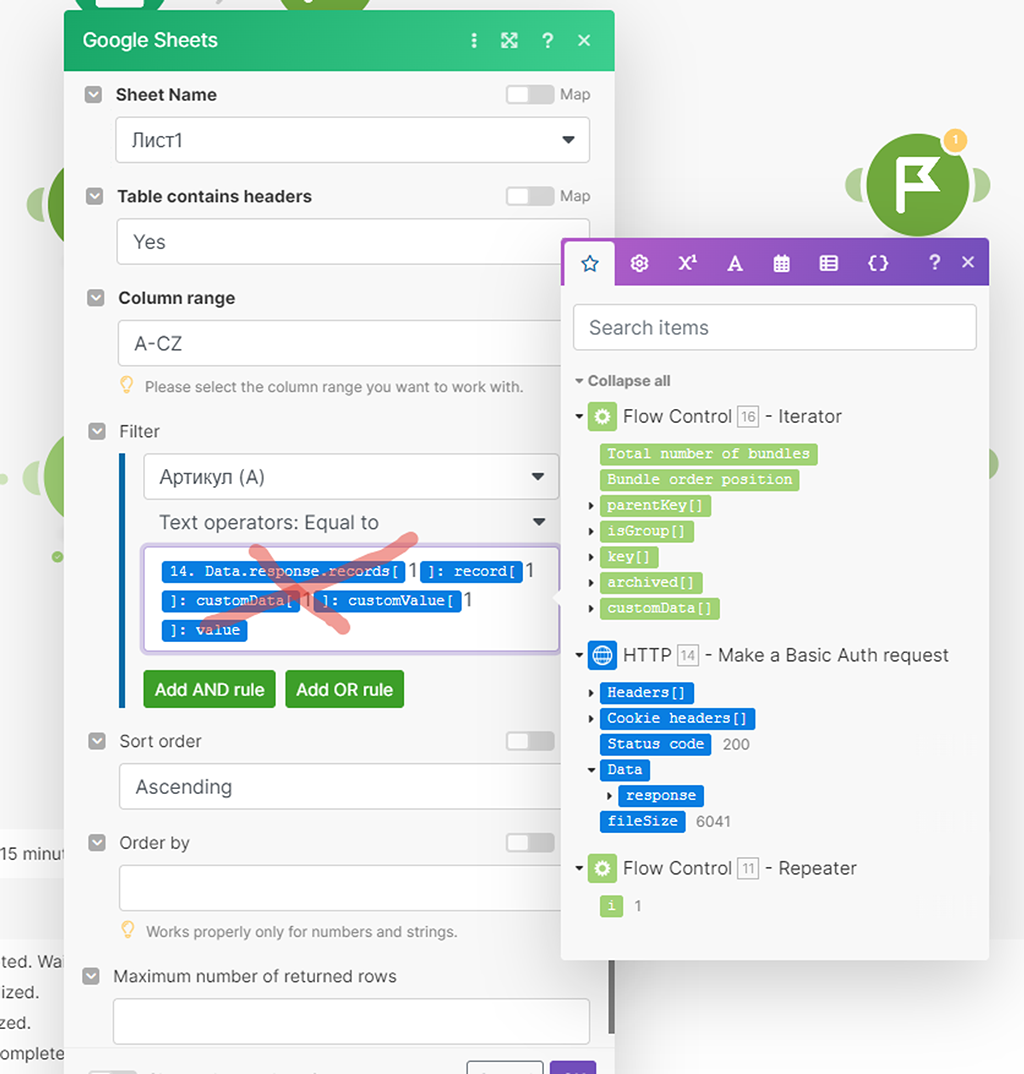
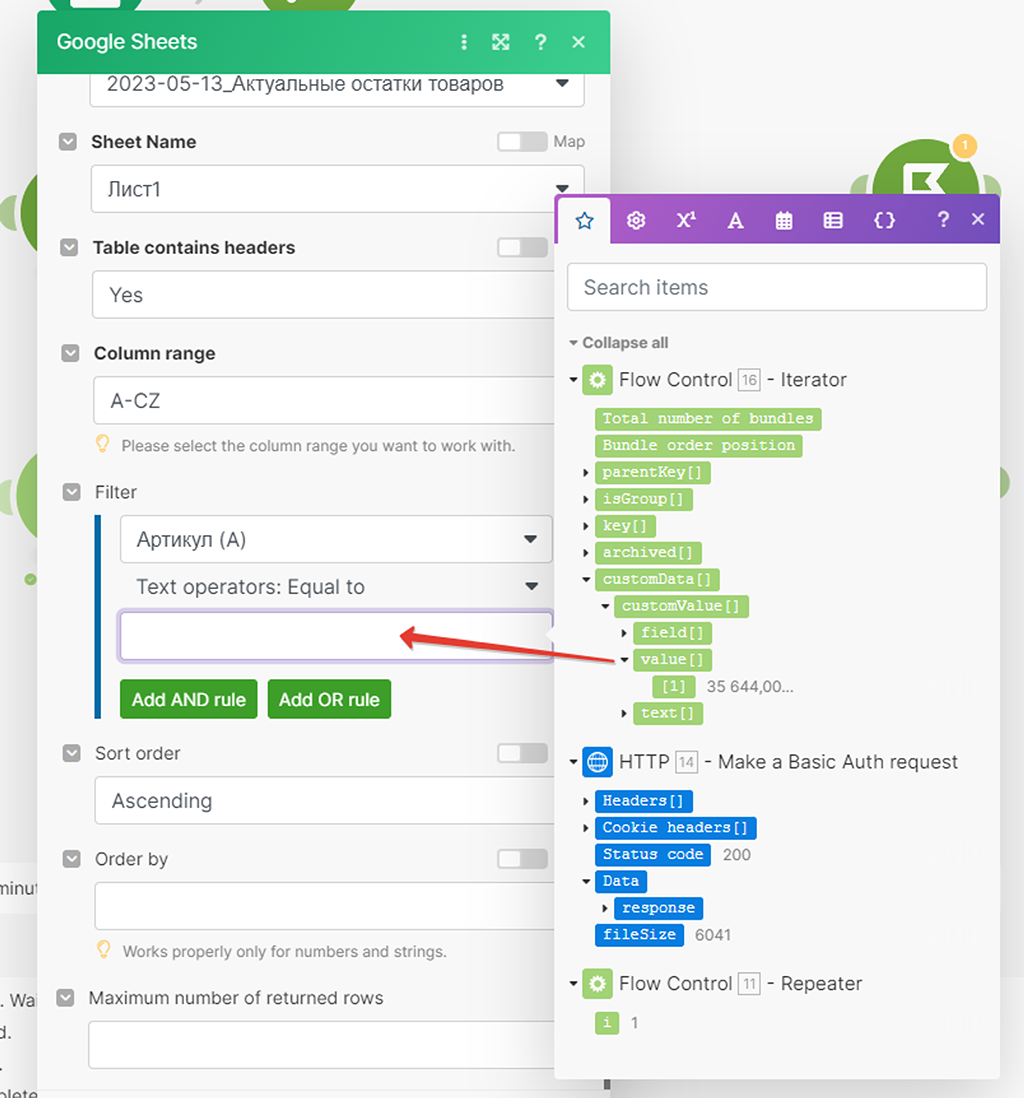
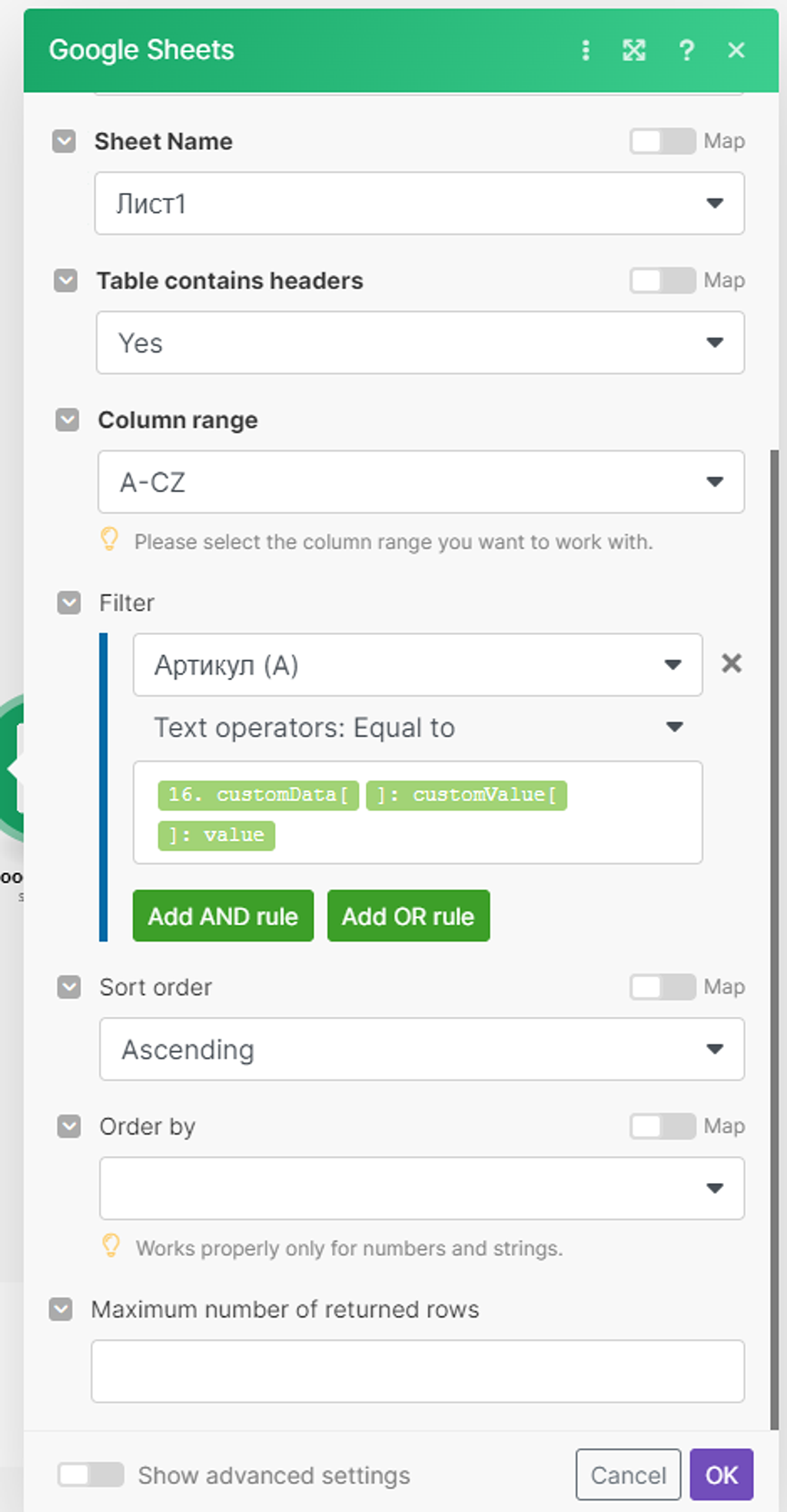
Запускаем сценарий для проверки:
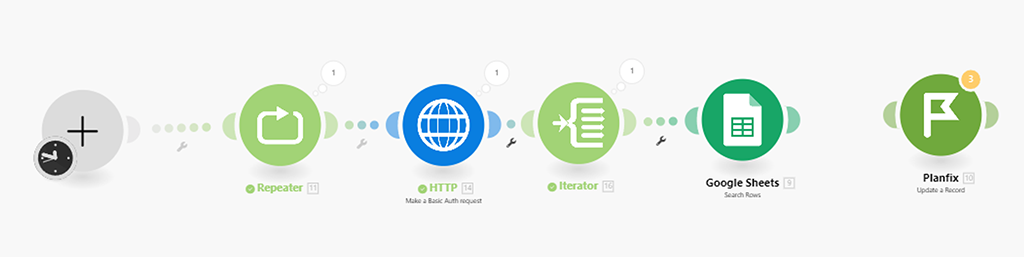
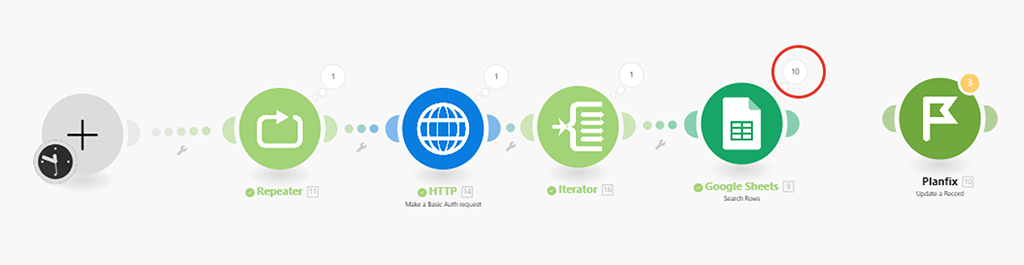
Даже по маркеру модуля (2) Google видно, что он корректно отработал — у нас в настройках модуля (5) HTTP сейчас стоит получить 10 записей, Google модуль 10 записей выявил и провёл по ним поиск (по артикулу).
Для тестового запуска я уменьшил количество получаемых значений в модуле (5) HTTP (вместо 100 теперь 10) и количество проходов сценария в модуле репитере (4) (вместо 4 теперь 1) — просто, чтобы уменьшить объём затрачиваемых операций и возможный объём негативных последствий при отладке сценария). Потом верну значения назад:
Да, теперь модуль работает корректно — ищет по артикулам полученных записей из справочника соответствующие записи в Google Документе и находит их.
Осталось скорректировать последний модуль (3) обновления данных в справочнике.
Шаг 6 — Корректировка модуля (3) обновления записи в справочнике PlanFix
Присоединяем этот модуль к цепочке нашего сценария и проверяем настройки:
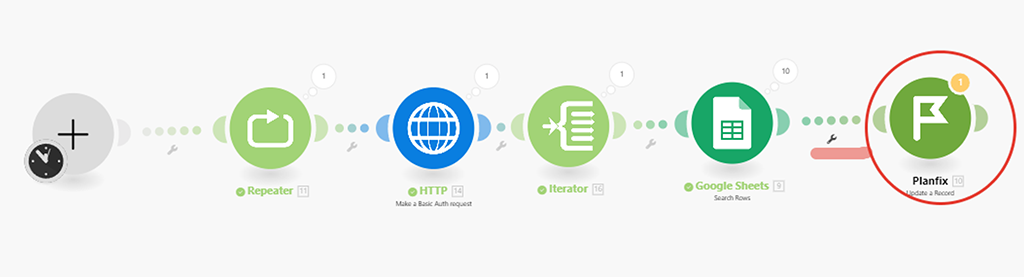
Мы видим, что модуль также, как и предыдущий, ссылается на уже удалённый из сценария модуль (1) PlanFix, а получать ID записи он теперь будет из распаренных массивов данных и собранных в бандлы (пакеты) из модуля (6) Итератор:
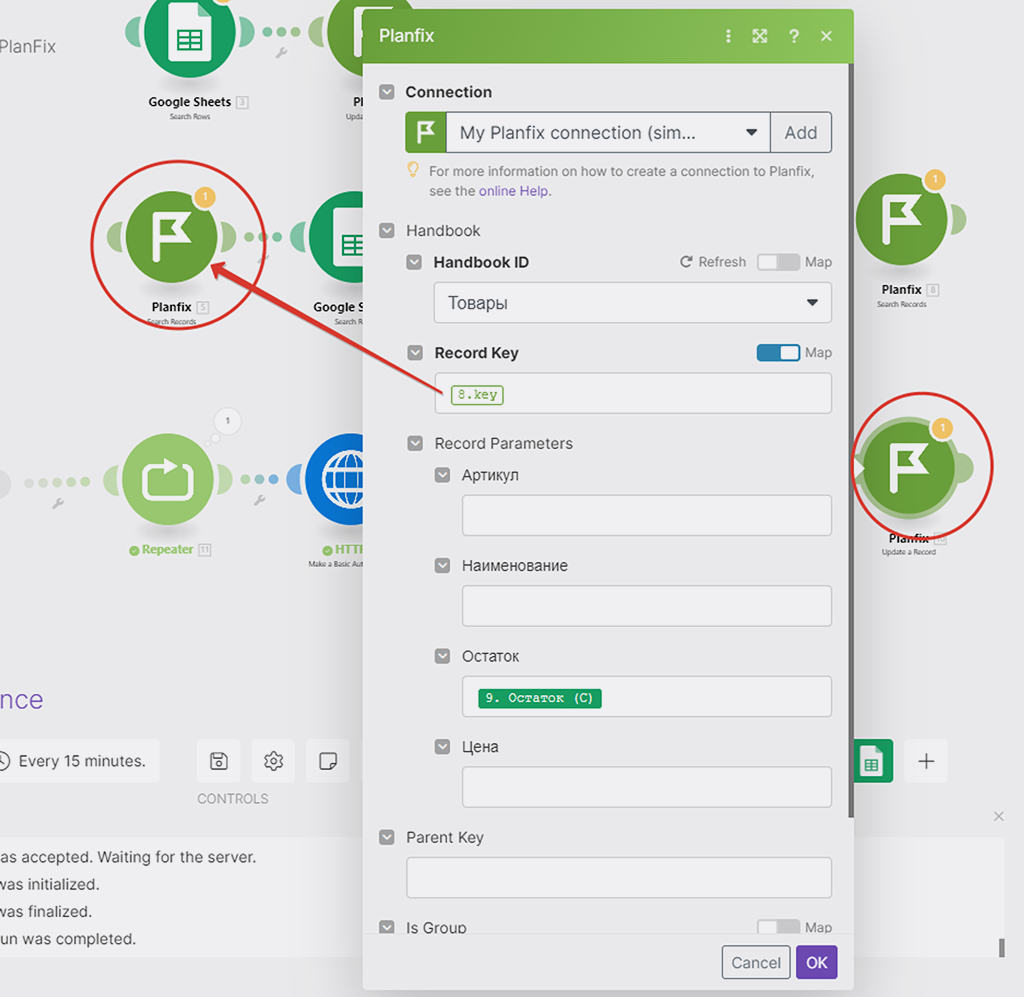

Key — это и есть наш Record key.
Вроде как всё. Проверим результат работы всего сценария.
Проверка работы сценария
Напомню, что:
Для тестового запуска я уменьшил количество получаемых значений в модуле HTTP (вместо 100 теперь 10) и количество проходов сценария в репитере (вместо 4 теперь 1) — просто, чтобы уменьшить объём затрачиваемых операций и возможный объём негативных последствий. Потом верну значения назад.
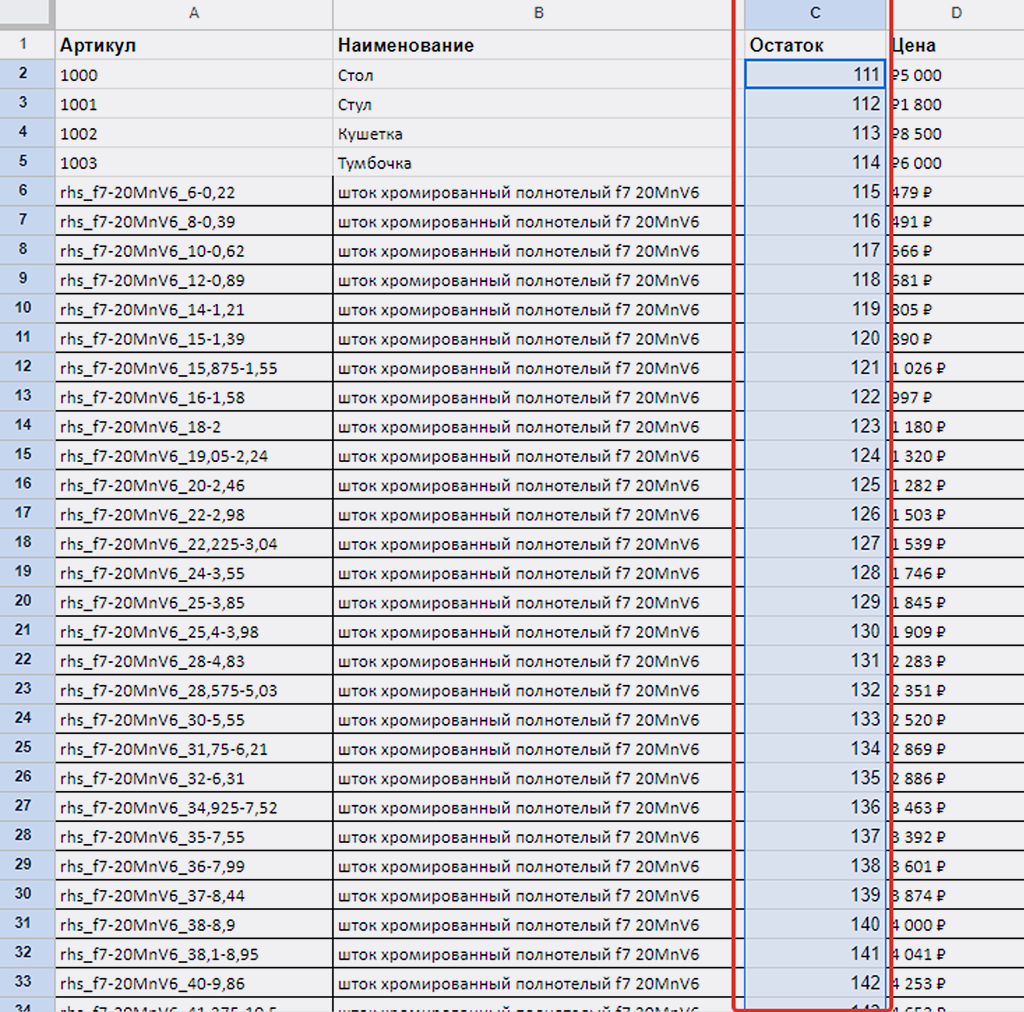
Прежде изменяем данные по остаткам в Google Документе, чтобы увидеть результат его работы в справочнике.
Сейчас в таблице и справочнике:
Изменил в Google Таблице остатки:
Запускаем сценарий в тестовом режиме (10 первых записей и только один запуск):
Так как сортировка записей в Google Таблице и в справочнике сейчас разная, то изменённые записи в справочнике не последовательно, но всё ок — работает.
Возвращаем рабочие настройки сценария (100 записей за раз и получить последовательно 4 сотни) и запускаем сценарий в рабочем режиме, прежде скорректировав все цены в Google Таблице:
Запускаем сценарий и смотрим на результат работы сценария по индикаторам модулей:
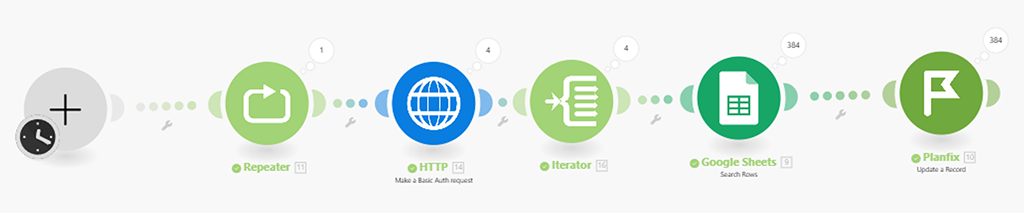
Что мы видим:
- Репитер (4) — сработал один раз. Ок — его задача была 4 раза запустить следующие за ним модули, всё это он производит в рамках одного срабатывания.
- HTTP API запрос (5) — сработал 4 раза, как нам и надо было, т.е. забирал 4 разные сотни данных.
- Итератор (6) — сработал 4 раза, как нам и надо было. Т.е. 4 раза обработал 4 поступивших в него сотни данных.
- Google модуль (2) — обработал все наши 384 записи (нашёл соответствующие записи в Google Таблице), т.е. взял 4 сотни, но последняя сотня не полная (84 записи), т.е. лишних отработок (пустых) он не сделал — бережёт наши деньги).
- Модуль (3) обновления записей в справочнике PlanFix — обновил все 384 записи нашего справочника.
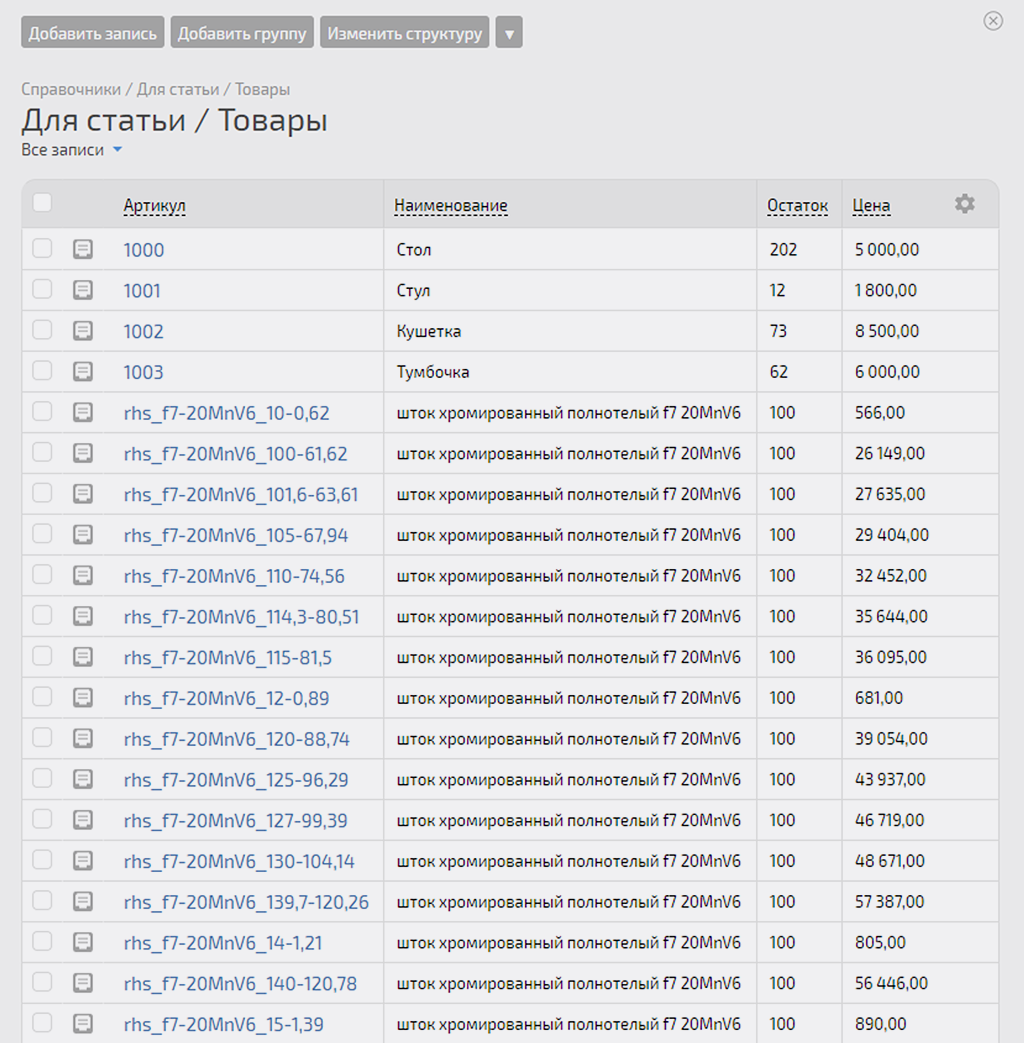
Ок. Проверим результат в справочнике PlanFix:
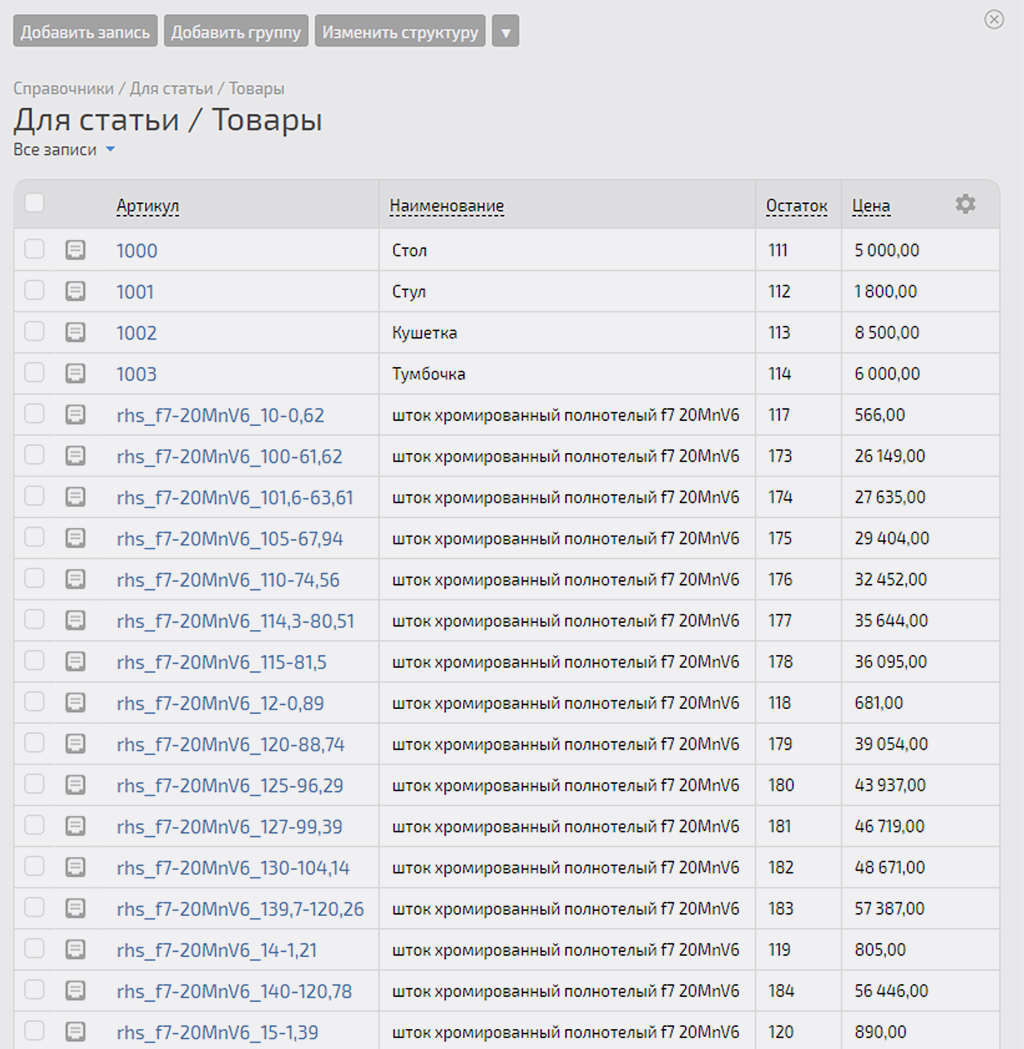
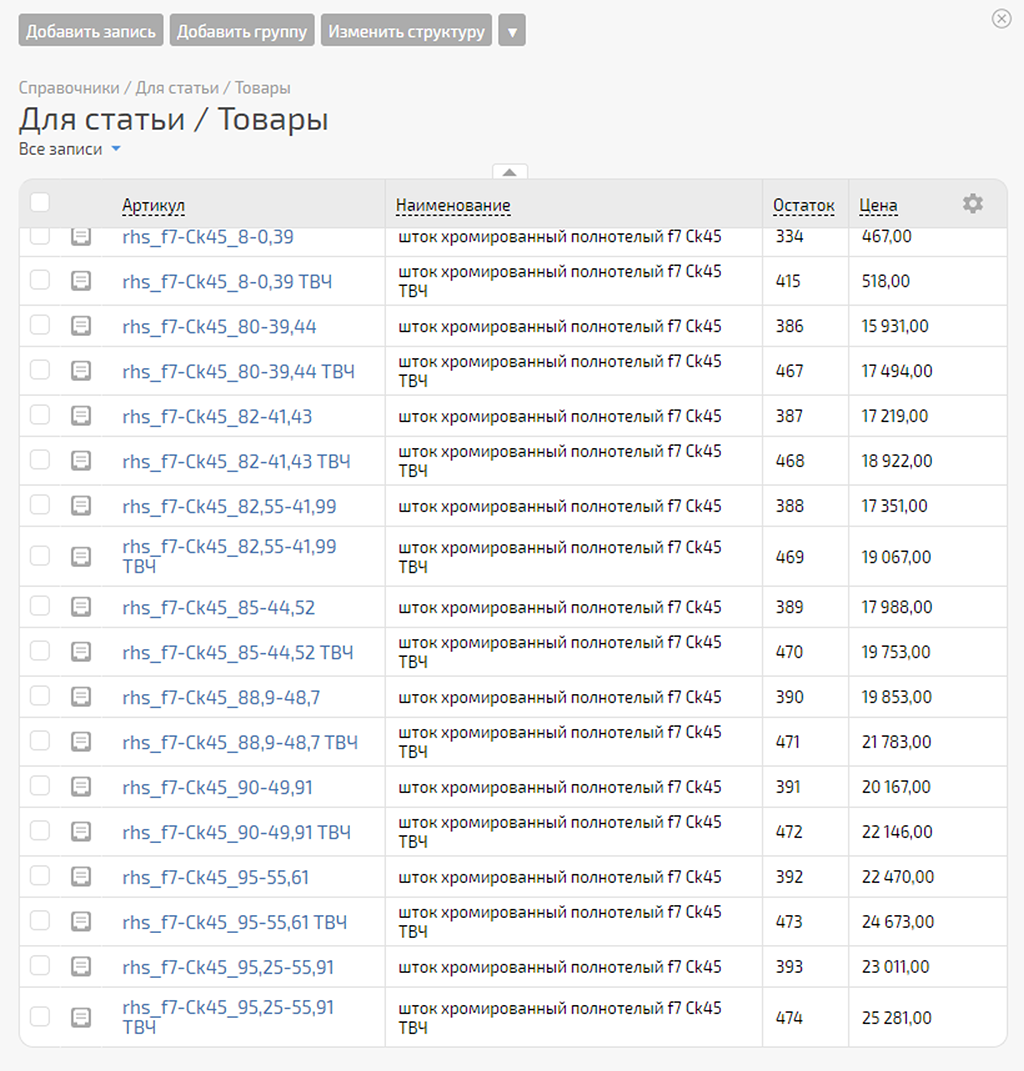
Да, у всех наших 384 записей данные по остаткам изменились. Сделаем выборочную проверку, чтобы убедиться, что все записи были изменены на соответствующие данные из записей Google Таблицы.
1) Запись в Google под№ 88 — артикул “rhs_f7-42CrMo4_18-2”, остаток “197”:
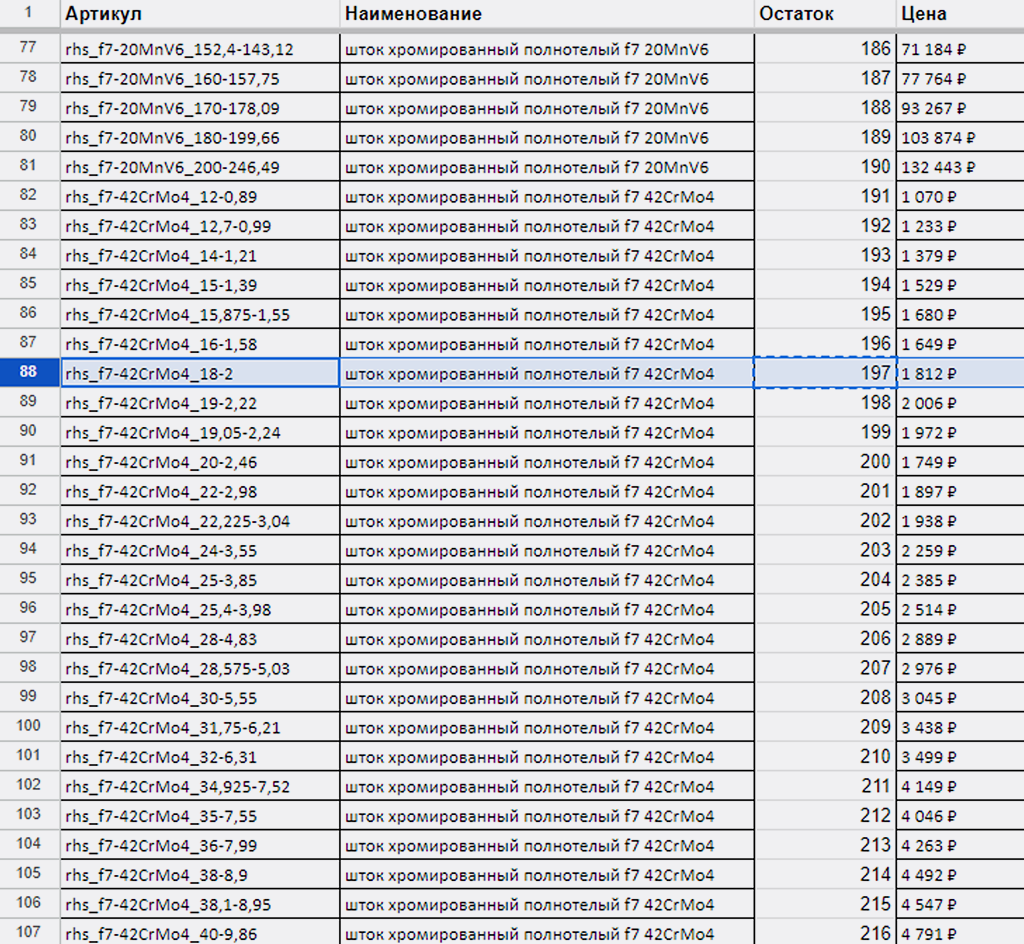
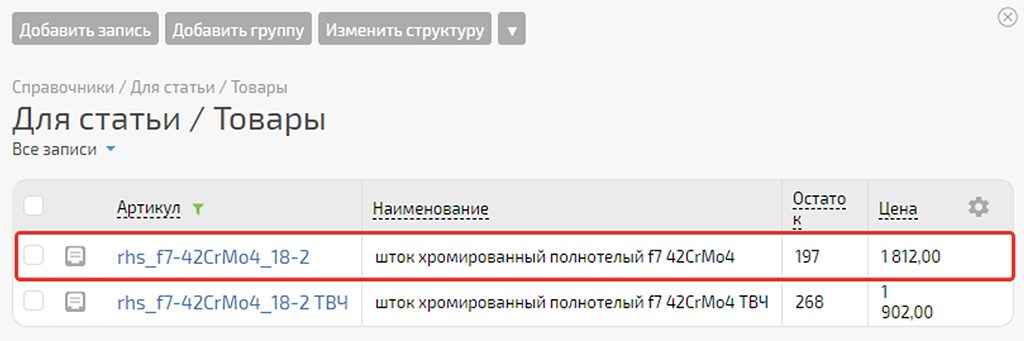
Всё ок.
2) Запись в Google под № 156 — артикул «rhs_f7-42CrMo4_15-1,39 ТВЧ», остаток «265»:
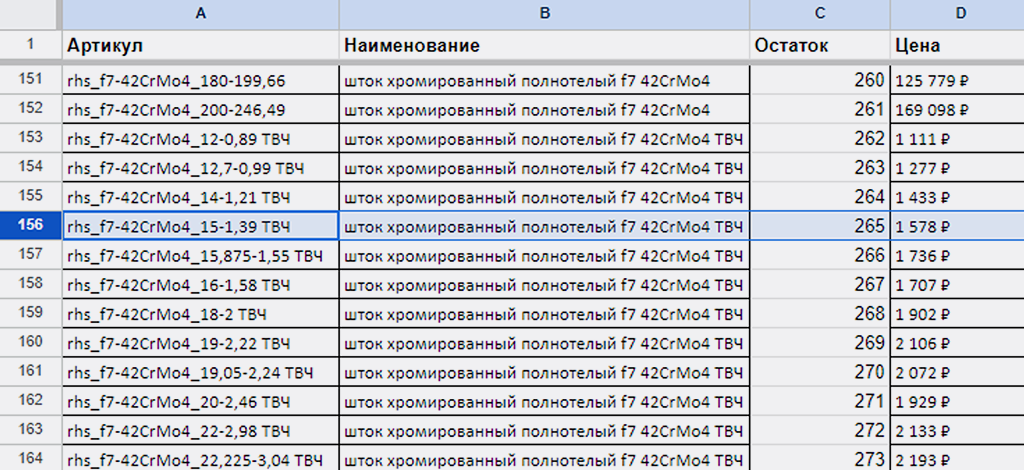
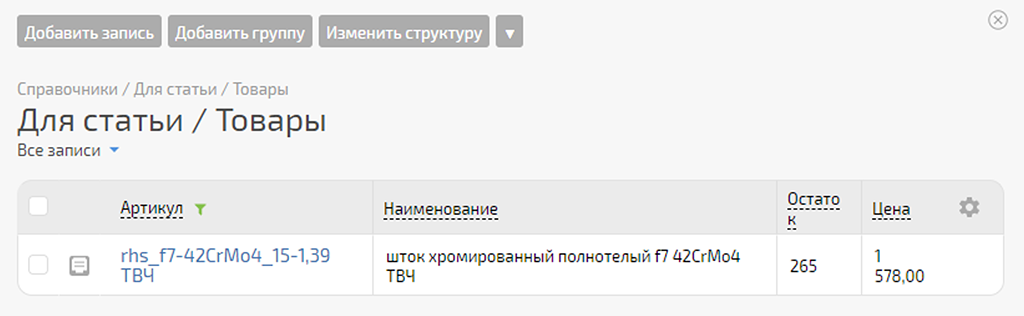
Всё ок.
3) Запись в Google под № 232 — Артикул «rhs_f7-Ck45_16-1,58», Остаток «341»:
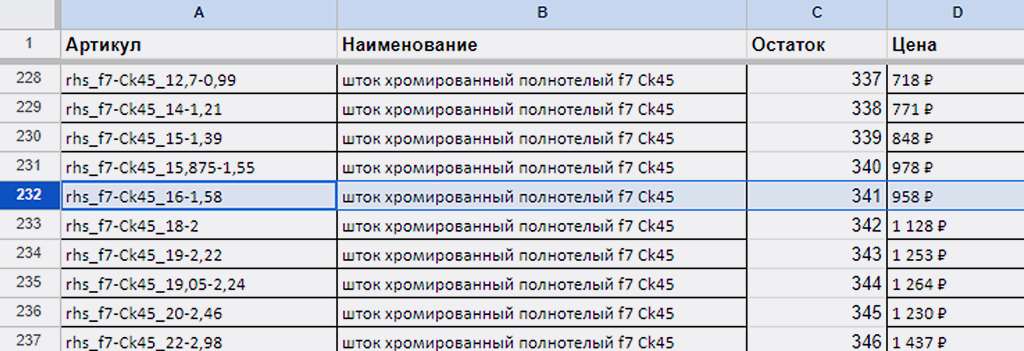
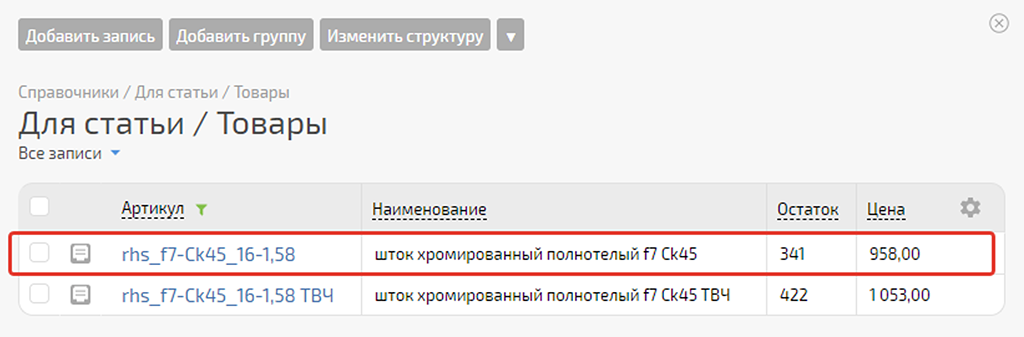
Всё ок. Сценарий, судя по контрольной выборке, работает корректно.
Ну, и отлично)
Итоги
Главный итог
Благодаря наличию в ПланФиксе разработанного интерфейса взаимодействия с БД других облачных сервисов API XML, мы можем не только решать такую специфическую задачу, как обновление данных в справочниках, но множество прочих задач по интеграции различных облачных сервисов с ПланФиксом по API.
Дополнительно
А) Сервис Make хорошая платформа для разработки цепочки API-запросов для интеграции между самыми различными облачными сервисами, в том числе и для интеграции с ПланФиксом — главное, что это no-code платформа, которая позволят не программисту решать такие задачи интеграций. Я вот вообще продакшн продюсер по разработке мультимедийного контента).
Б) Наличие готовых модулей интеграции от облачных сервисов в Make сильно упрощает работу (мы видели готовые решения от PlanFix, от Google).
В) Но если готовых модулей нет или они не совершенны (а у облачного сервиса есть свой API, то можно воспользоваться штатными инструментарием Make для решения задач интеграции. Чуть сложнее, но и гибче).
Г) Немного изучили синтаксис API XML PlanFix.
Д) Увидели, что может быть несколько вариантов решения одной задачи даже с одним и тем же инструментарием.
Надеюсь, описание этого кейса вышло полезным для читающего и станет подспорьем для решения иных задач при настройке собственных систем управления в ПланФиксе.
Артём Колисниченко: Я вас поздравляю, вы осилили этот трактат 🙂 Теперь вы знаете чуточку больше о настройках nocode-сервисов. Надеюсь, новые знания вы успешно будете применять в своей работе.
Не забывайте о наших социальных сетях: ВКонтакте, Telegram и ВК Видео. Там появляются новости о доработках и новинках. Подпишитесь, чтобы ничего не пропустить.

Невероятно круто, что вы осилили эту механику внешней интеграции! Спасибо за материал, он показывает, почему внешние интеграции вообще сложные, не говоря о том, что это все продумать надо.
А ведь если появится поле в справочнике, удалится => надо же поменять кусочки кода в Маке, а это еще помнить надо. С каждым типом поля свои нюансы работы.
В общем, кому очень надо, пройдут этот непростой путь.
Мы обновляем записи справочника по трек-номерам Почты России, соответствия у нас попроще сделать:
https://getupd.io/blog/instructions/27-kak-podklyuchit-konnektor-otslezhivaniya-pisem-po-trek-nomeru
Степан, спасибо за оценку материала.
***
А ведь если появится поле в справочнике, удалится => надо же поменять кусочки кода в Маке, а это еще помнить надо. С каждым типом поля свои нюансы работы.
***
Да, к сожалению, так и есть. Даже если Вы просто поменяете расположение полей в справочнике, то и расположение “свитков” в массиве полученный данных также изменится.
Да, тоже столкнулся с необходимостью синхронизации двух баз данных справочников – в ПФ и в стороннем приложении из-за невозможности выборки по значению поля (писал об этом на форуме несколько лет назад https://forum.planfix.ru/viewtopic.php?t=5600).
В REST API появилась возможность выборки по полю через фильтр, но отсутствуют возможности работы с аналитиками, например.
На предложение реализовать подобную функцию в XML API получил отказ.
Похоже, придется пользоваться двумя API одновременно.
Кстати, Make (Integromat) сам прекрасно фильтрует полученные данные по любому значению — это опция доступна не в самом модуле интеграции, а в связке между модулями. Очень удобно и функционально. Правда, каждая фильтрация тоже ест операции и бюджет, соотвественно)
Ну, во-первых – это красиво.
Во-вторых – дочитал
В-третьих – спасибо за материал! 🙂
Очень подробный гайд, просто жесть.
Повторить нет желания 🙂
Очень хочется чтобы в Планфиксе появился импорт который обновит значения полей в существующих записях, и просто кидать эксельку в монитор.
Жаль, что в блоге нету лайков, а то я бы поставил 👍
Тоже хочу такой импорт. Есть идея, как это сделать, но не хватает ресурсов, чтобы угнаться за всем. Хотя я все равно верю в лучшее будущее)